CV¶
一些深度学习基础知识点¶
最开始学深度学习的时候做的一些笔记,这个部分先暂时放在这里
白化(Whitening)¶
https://blog.csdn.net/danieljianfeng/article/details/42147109 白化(Whitening) PCA白化 ZCA白化
白化是一种重要的预处理过程,其目的就是降低输入数据的冗余性,使得经过白化处理的输入数据具有如下性质:(i)特征之间相关性较低;(ii)所有特征具有相同的方差。
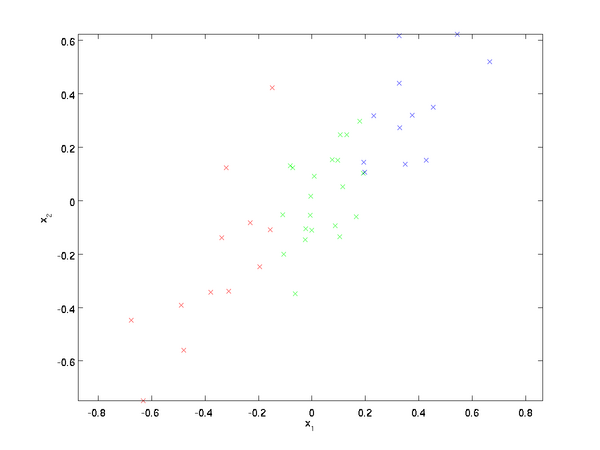
原始数据
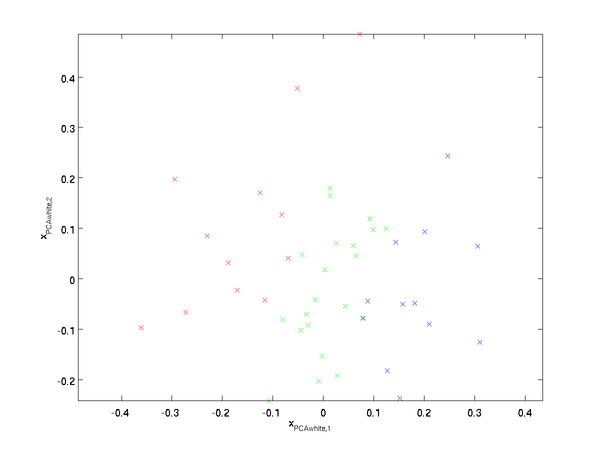
PCA白化
ZCA白化
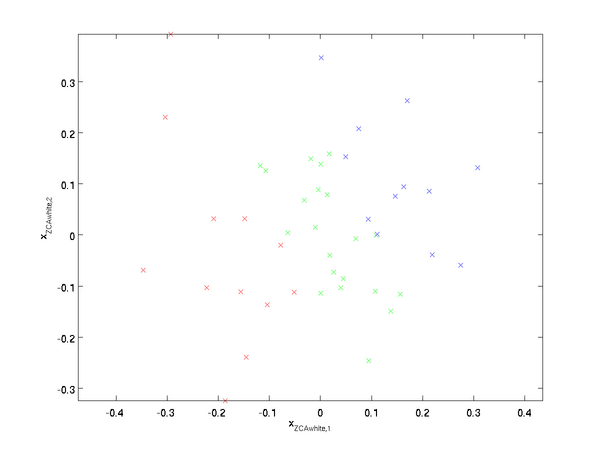
ZCA白化¶
只不过是把他再转回原来的角度
PCA白化和ZCA白化的异同¶
PCA白化ZCA白化都降低了特征之间相关性较低,同时使得所有特征具有相同的方差。
1.PCA白化需要保证数据各维度的方差为1,ZCA白化只需保证方差相等。
2.PCA白化可进行降维也可以去相关性,而ZCA白化主要用于去相关性另外。
3.ZCA白化相比于PCA白化使得处理后的数据更加的接近原始数据。
正则化¶

Dropout¶
dropout 在训练和测试时候的差异¶
训练时要dropout,测试和验证的时候不需要
如果失活概率为0.5,则平均每一次训练有3个神经元失活,所以输出层每个神经元只有3个输入,而实际测试时是不会有dropout的,输出层每个神经元都有6个输入, 这样在训练和测试时,输出层每个神经元的输入和的期望会有量级上的差异。
因此在训练时还要对第二层的输出数据除以(1-p)之后再传给输出层神经元,作为神经元失活的补偿,以使得在训练时和测试时每一层输入有大致相同的期望。
batch normalize BN¶
BN训练和测试时的参数是一样的嘛?¶
BN训练时为什么不用全量训练集的均值和方差呢?¶
这个差别实际上能够增加模型的鲁棒性,也会在一定程度上减少过拟合。 | 也正是因此,BN一般要求将训练集完全打乱,并用一个较大的batch值,否则,一个batch的数据无法较好得代表训练集的分布,会影响模型训练的效果。

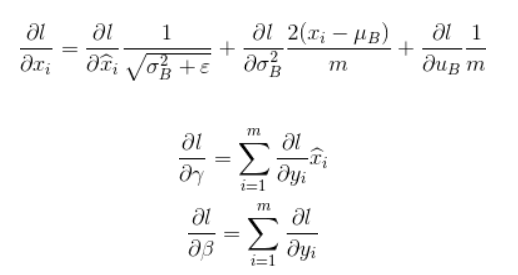
BN解决过拟合¶
Batch Normalization的主要作用是加快网络的训练速度。
如果硬要说是防止过拟合,可以这样理解:BN每次的mini-batch的数据都不一样,但是每次的mini-batch的数据都会对moving mean和moving variance产生作用,可以认为是引入了噪声
BN和Dropout 共同使用¶
不会产生1+1>2的效果,相反可能会得到比单独使用更差的效果。 论文《Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift》
会产生「方差偏移」的现象。
当网络从训练转为测试时,Dropout 可以通过其随机失活保留率(即 p)来缩放响应,并在学习中改变神经元的方差,而 BN 仍然维持 X 的统计滑动方差。 这两者之间会有误差。 随着网络越来越深,最终预测的数值偏差可能会累计,从而降低系统的性能。
作者采用了两种策略来探索如何打破这种局限。一个是在所有 BN 层后使用 Dropout,另一个就是修改 Dropout 的公式让它对方差并不那么敏感,就是高斯Dropout。
pooling池化¶
max pooling和average pooling¶

稍微总结一下:
average 的话能保留更多信息,但是也会把冗余信息保留下来
mean-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差,更多的保留纹理信息。
Global average pooling¶
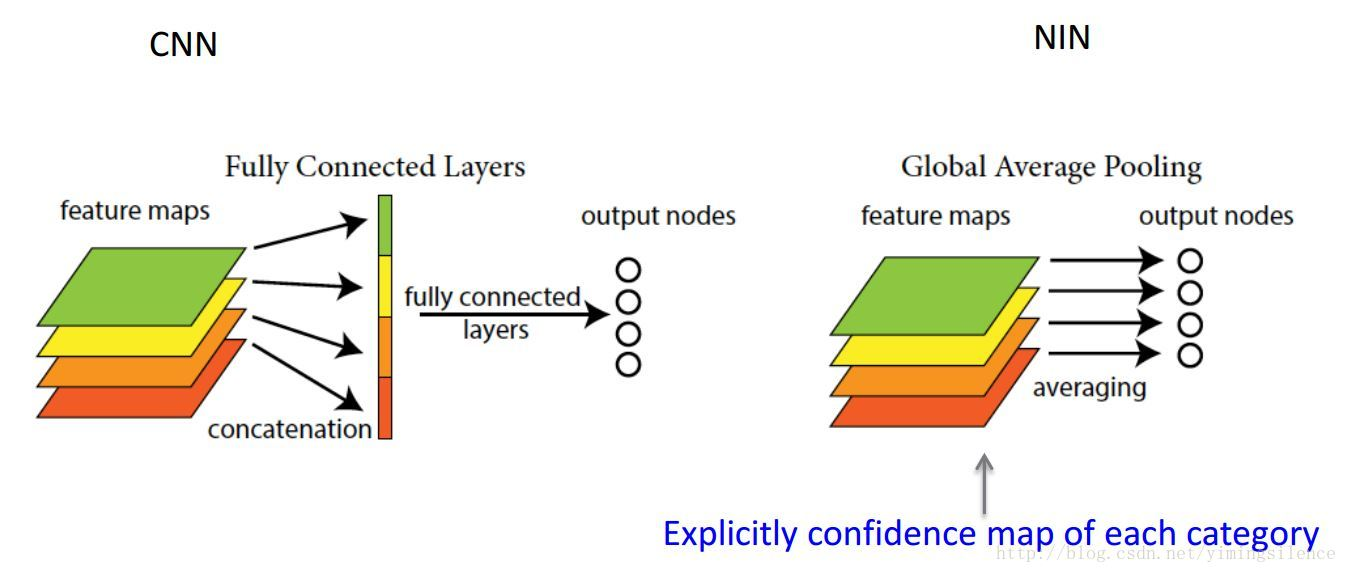
理解是。之前的多分类,通过的是两层mlp,压缩到输出类别n。Global ave pooling是直接压缩到n
有两个优点:一是GAP在特征图与最终的分类间转换更加简单自然;二是不像FC层需要大量训练调优的参数,降低了空间参数会使模型更加健壮,抗过拟合效果更佳。
相当于剔除了全连接层黑箱子操作的特征,直接赋予了每个channel实际的类别意义。
AdaptiveAvgPool1d¶
Padding¶
嵌入层 Embedding¶
激活函数¶
导数 s’(x) = s(x)(1-s(x))
tanh
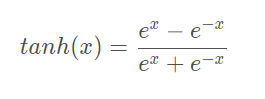
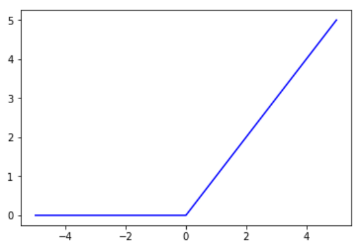
Relu(x)=max(0,x)
relu的优点:
第一,采用sigmoid等函数,算激活函数时候(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相当大,而采用Relu激活函数,整个过程的计算量节省很多
第二,对于深层网络,sigmoid函数反向传播时,很容易就出现梯度消失的情况(在sigmoid函数接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练
第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生
缺点:
有一个被称为 “ReLU 死区” 的问题:在训练过程中,一些神经元会“死亡”,即它们停止输出 0 以外的任何东西。 在某些情况下,你可能会发现你网络的一半神经元已经死亡,特别是使用大学习率时。 在训练期间,如果神经元的权重得到更新, 使得神经元输入的加权和为负,则它将开始输出 0 。当这种情况发生时,由于当输入为负时,ReLU函数的梯度为0,神经元就只能输出0了。
Dead ReLU


损失函数¶

softmax loss只是交叉熵的一个特例

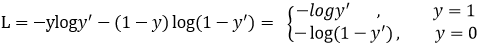
分类为什么用CE而不是MSE 请见 machine_learning 那一页的 Logistics regression
有哪些损失函数¶
smooth L1 loss ( |x| < 1 时等于0.5x**2, else:等于|x|-0.5)
pytorch中有哪些损失函数¶
PyTorch 学习笔记(六):PyTorch的十八个损失函数 https://zhuanlan.zhihu.com/p/61379965
文章里面有详细的解释
1.L1loss
2.MSELoss
3.CrossEntropyLoss
4.NLLLoss
5.PoissonNLLLoss
6.KLDivLoss
7.BCELoss
8.BCEWithLogitsLoss
9.MarginRankingLoss
10.HingeEmbeddingLoss
11.MultiLabelMarginLoss
12.SmoothL1Loss
13.SoftMarginLoss
14.MultiLabelSoftMarginLoss
15.CosineEmbeddingLoss
16.MultiMarginLoss
17.TripletMarginLoss
18.CTCLoss
熵,交叉熵,KL散度¶
这个视频讲的不错 Entropy,Cross Entropy,KL Divergence 信息熵,交叉熵,KL散度 https://www.bilibili.com/video/BV1Rb411M75k?from=search&seid=9372239679612024672
下段内容摘抄总结自 为什么交叉熵(cross-entropy)可以用于计算代价? https://www.zhihu.com/question/65288314
先给出一个“接地气但不严谨”的概念表述:
一种信息论的解释是:
一句话总结的话:KL散度可以被用于计算代价,而在特定情况下最小化KL散度等价于最小化交叉熵。而交叉熵的运算更简单,所以用交叉熵来当做代价。
首先讲信息论里的交叉熵

其实这个就是衡量两个分布之间的距离的。属于各个类别的预测值的分布,这句话描述的是关于类别的分布,而不是样本的分布,不要弄混. (因为公式里面都是概率)。KL散度也是
KL散度和交叉熵的对比¶
关于softmax细节¶
更加细致的东西
从最优化的角度看待Softmax损失函数 https://zhuanlan.zhihu.com/p/45014864
Softmax理解之二分类与多分类 https://zhuanlan.zhihu.com/p/45368976
在二分类情况下Softmax交叉熵损失等价于逻辑回归
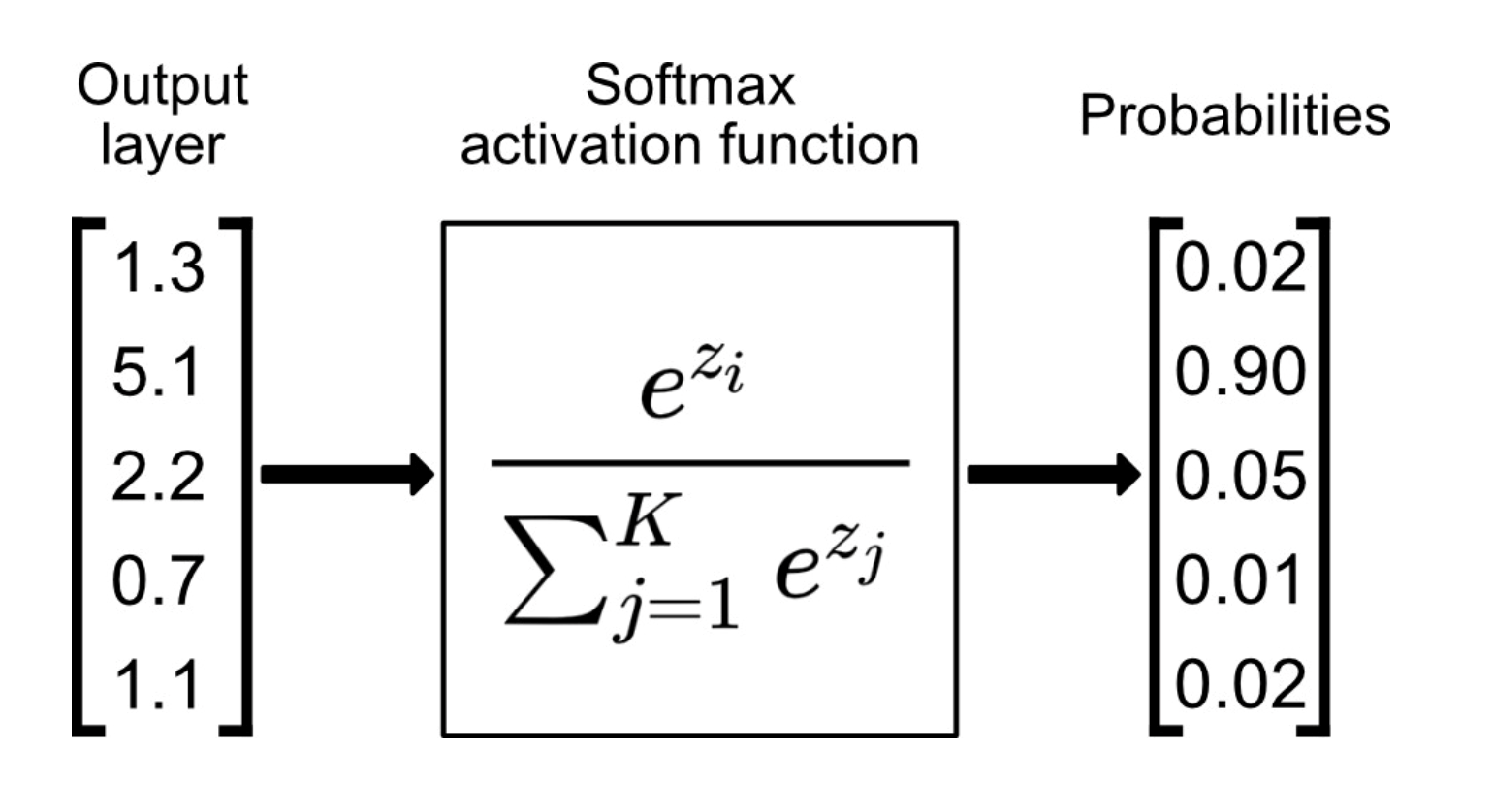
softmax为什么要对output layer 进行指数运算后再归一化,直接归一化不行吗:
focal loss¶
Kaiming 大神团队在他们的论文Focal Loss for Dense Object Detection
解决分类问题中类别不平衡、分类难度差异
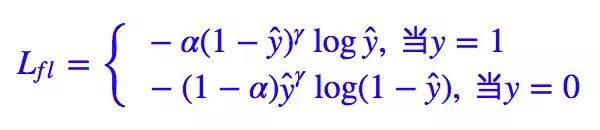
意思是这个正样本如果预测出来的概率很大,那么loss就相对小,如果预测出来概率小,那么相应的loss就大,迫使模型去更加注意那些难区分的样本 (可以自己拿个正样本,预测出来的概率是0.9试试,0.1的平方)
不难理解,α是用来适应正负样本的比例的。(如果正样本少,α为小于0.5的数,这样正样本的loss也会小)
γ称作focusing parameter,控制难易程度。
在他的模型上 α=0.25, γ=2的效果最好
为什么需要对 classification subnet 的最后一层conv设置它的偏置b为-log((1-Π)/Π),Π代表先验概率, 就是类别不平衡中个数少的那个类别占总数的百分比,在检测中就是代表object的anchor占所有anchor的比重。论文中设置的为0.01
一开始最后一层是sigmoid,如果默认初始化情况下即w零均值,b为0,正负样本的输出都是-log(0.5)。刚开始训练的时候,loss肯定要被代表背景的anchor的误差带偏。
这样第一次,代表正样本的loss变成-log(Π), 负样本的loss变成 -log(1-Π)。正样本的loss变大
作者设置成了Π=0.01
focal loss理解与初始化偏置b设置解释 https://zhuanlan.zhihu.com/p/63626711
过拟合¶
如何判断过拟合还是欠拟合¶
说明网络对于数据集的拟合是不够的。大概率是因为网络还没训练好,应该继续训练。(高偏差)(其实就是train和val效果的数值都不好) | • 增加特征 | • 获得更多的特征 | • 增加多项式特征 | • 减少正则化程度
- 还有一种最坏的情况,就是偏差高,方差也大。大概率就是数据集的问题了。
陷入局部最优解¶
深度学习模型陷入局部最优解时,可以尝试以下一些方法来调整模型的训练:
学习率调整:
减小学习率: 如果你的模型收敛过快并在局部最优解处振荡,尝试减小学习率。较小的学习率可能会使模型更加稳定,但需要更多的迭代次数来收敛。
学习率衰减: 逐渐减小学习率,使模型在训练初期更快地收敛,然后逐渐降低学习率以提高模型的精度。
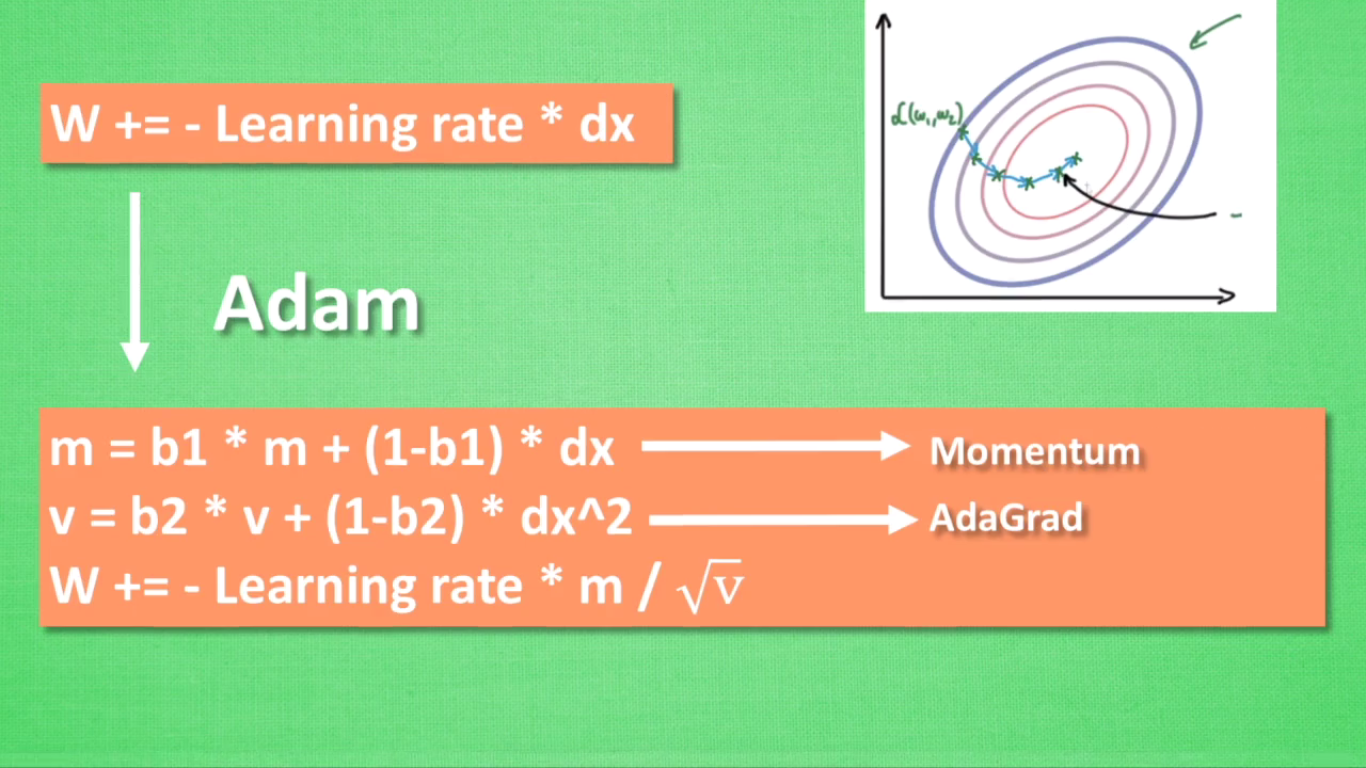
使用不同的优化器:
尝试不同的优化器,例如Adam、SGD(随机梯度下降)、Adagrad等。不同的优化器可能在不同的问题上表现更好。
正则化:
添加正则化项,如L1或L2正则化,以减少模型的复杂性,防止过拟合。
更改网络结构:
调整模型的层数和宽度,有时候增加或减少神经网络的复杂度可以改善模型性能。
数据增强:
对训练数据进行增强,例如旋转、平移、缩放等,以提高模型的泛化能力。
使用预训练模型:
如果问题允许,可以使用预训练模型,这有助于模型更快地收敛到一个好的解决方案。
批次大小调整:
增加或减少批次大小,有时候改变批次大小可以改善模型的训练效果。一般来说是减少batch_size,这样更加容易跳出鞍点
提前停止:
实施提前停止策略,即在验证集性能不再提升时停止训练,以防止过拟合。
调整激活函数:
尝试不同的激活函数,例如ReLU、Leaky ReLU、ELU等,以及使用激活函数之前的归一化操作,如批量归一化。
超参数搜索:
使用网格搜索或随机搜索等方法来搜索超参数的最佳组合。
优化¶



CNN参数计算¶
经过CNN后输出的维度:
(N-F+2P / stride) + 1
N是上一层的image size,比如256*256。 F是filter的size,比如3*3。P是padding
参数量: 假设上一层是 227*227*3 这一层用了96个 11*11的filter 那么参数量是 3*11*11*96 注意要乘上一层的3和这一层的96
RNN LSTM Transformer的参数量见NLP那一页
Inception¶
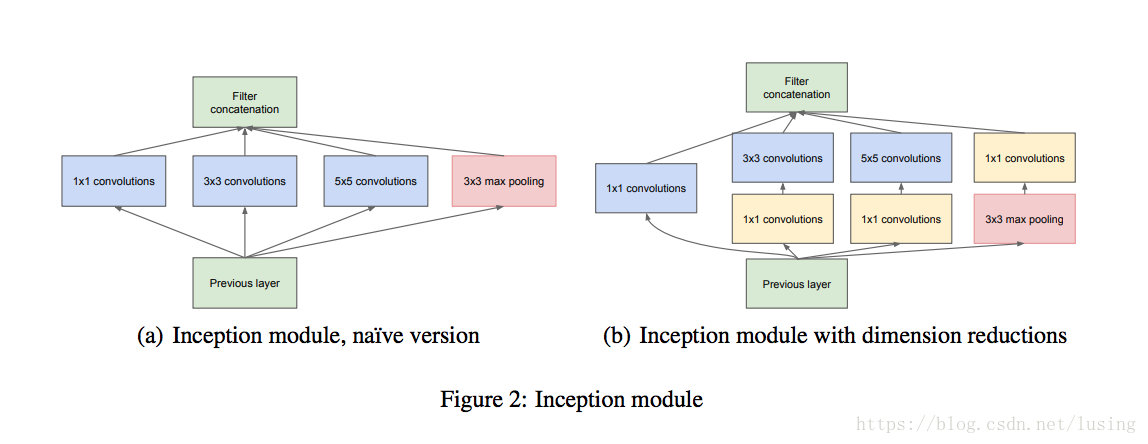
Inception Module基本组成结构有四个成分。1*1卷积,3*3卷积,5*5卷积,3*3最大池化。最后对四个成分运算结果进行通道上组合。这就是Inception Module的核心思想。 通过多个卷积核提取图像不同尺度的信息,最后进行融合,可以得到图像更好的表征。
Inception V2
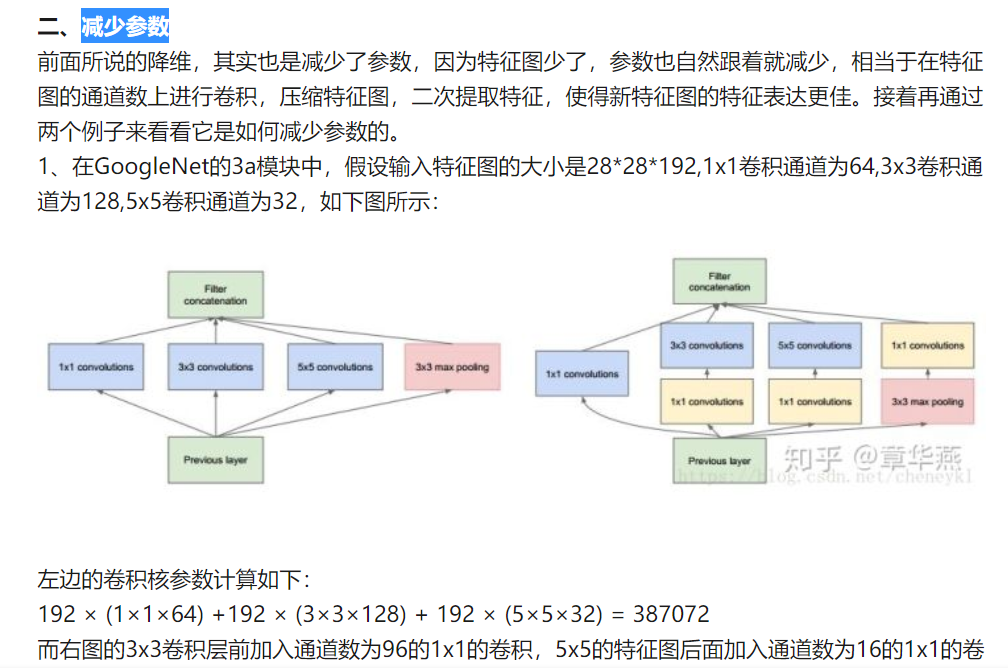
1.学习VGGNet的特点,用两个3*3卷积代替5*5卷积,可以降低参数量。
2.提出BN算法。BN算法是一个正则化方法,可以提高大网络的收敛速度。简单介绍一下BN算法。就是对输入层信息分布标准化处理,使得规范化为N(0,1)的高斯分布,收敛速度大大提高。
Inception V3
学习Factorization into small convolutions的思想,将一个二维卷积拆分成两个较小卷积,例如将7*7卷积拆成1*7卷积和7*1卷积。这样做的好处是降低参数量。paper中指出,通过这种非对称的卷积拆分,比对称的拆分为几个相同的卷积效果更好,可以处理更多,更丰富的空间特征。
Inception V4
resnet有关
1x1卷积核的作用¶
一维卷积尺寸选取¶
主要说我们心电的项目
第一层1*15,第二层1*7,第三层1*5,后面都是1*3
理由:
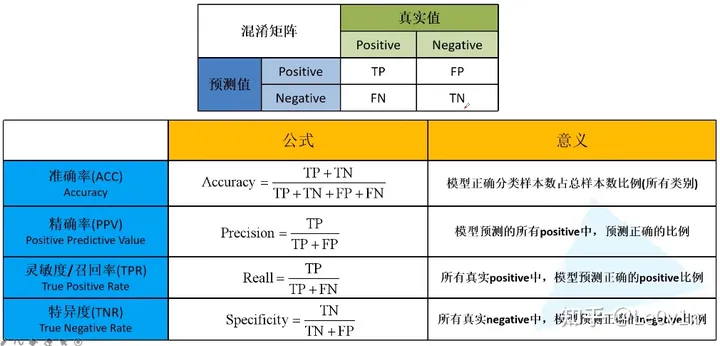
Accuracy、Precision、Recall、AUC F1 等分类问题评价指标¶
在ROC_AUC曲线中,横轴是False Positive Rate(FPR,假阳性率),纵轴是True Positive Rate(TPR,真阳性率)。
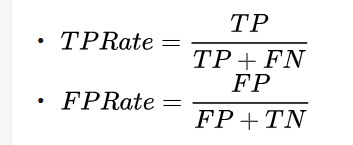
AUC ,Area Under Curve
AUC其实也分为 PR_AUC和ROC_AUC 至少这两种。一般说的多的是ROC_AUC
在二元分类问题中,模型通过输出实例属于正类的概率来进行预测。 然后对该概率应用阈值以进行最终预测:如果概率高于阈值,则预测该实例为正;否则,该实例被预测为正。 否则,预测结果为负。
现在,根据您选择的阈值,您将获得不同的精度和召回值。 例如,高阈值将导致较少的阳性预测,这可能会导致高精度(因为您对标记为阳性的内容非常有选择性),但召回率较低(因为您可能会错过很多实际的阳性) 。 相反,低阈值可能导致高召回率但低精度。
当我们说“在每个可能的阈值处绘制精度和召回率”时,我们的意思是创建一个图表,其中 x 轴代表召回率,y 轴代表精度,并且图表上的每个点对应于不同的阈值。 该图称为精确率-召回率曲线。 该曲线下的面积 (PR AUC) 为我们提供了模型在所有阈值上的性能的单一衡量标准,值越高表示性能越好。
默认情况下,许多分类模型使用阈值 0.5。 这意味着,如果模型估计正类的概率大于或等于 0.5,则将该实例分类为正类; 否则,将其分类为负数。
然而,这个阈值可以根据当前问题的具体要求进行调整。 例如,在欺诈检测场景中,漏报(漏掉的欺诈交易)的成本非常高,您可能希望降低阈值,以便更多交易被归类为欺诈交易并进一步审查。 这会增加召回率(正确识别的实际阳性的比例),但也可能导致更多的误报(合法交易被错误地标记为欺诈)。

F1 score
top1 error, top5 error
MSE、RMSE、MAE、R2 等回归问题评价指标¶
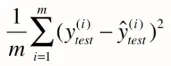
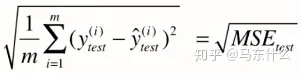
MAE(Mean Absolute Error)平均绝对误差¶
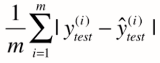
在推导a,b的式子时(对train数据集),没用求绝对值的方法是因为其不是处处可导,不方便用来求极值。但评价模型时,对test数据集我们完全可以使用求绝对值的方式。
P.S. 评价模型的标准和训练模型时最优化的目标函数是可以完全不一样的。
R2(R-Square)决定系数¶
对于上述的衡量方法,都存在的问题在于,没有一个上下限,比如我们使用auc,其上限为1,则越接近1代表模型越好,0.5附近代表模型和随机猜测基本差不多性能很差,实际上回归中也是存在这样一中指标的。
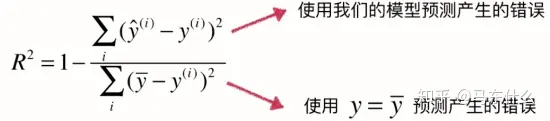
(上:y预测-y真,our model,下:y真平均-y真,baseline model).意思是,上面是我们的方法,下面是就用均值这种最拉的方法,两者来对比测评

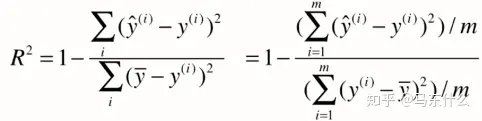
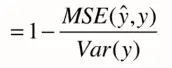
我们可发现,上面其实就是MSE,下面就是方差
如何评估一个模型的好坏¶



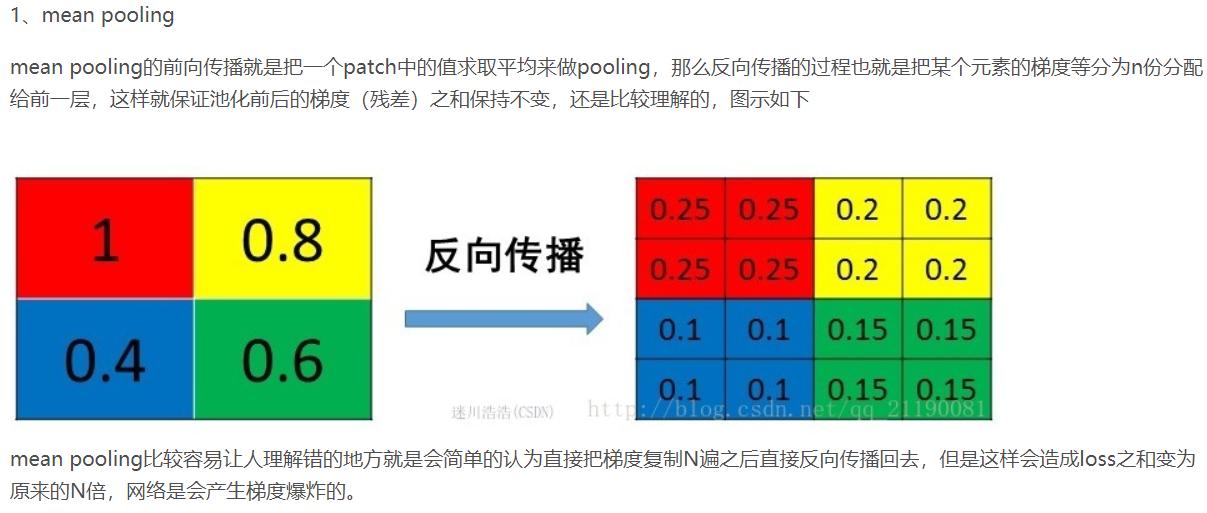
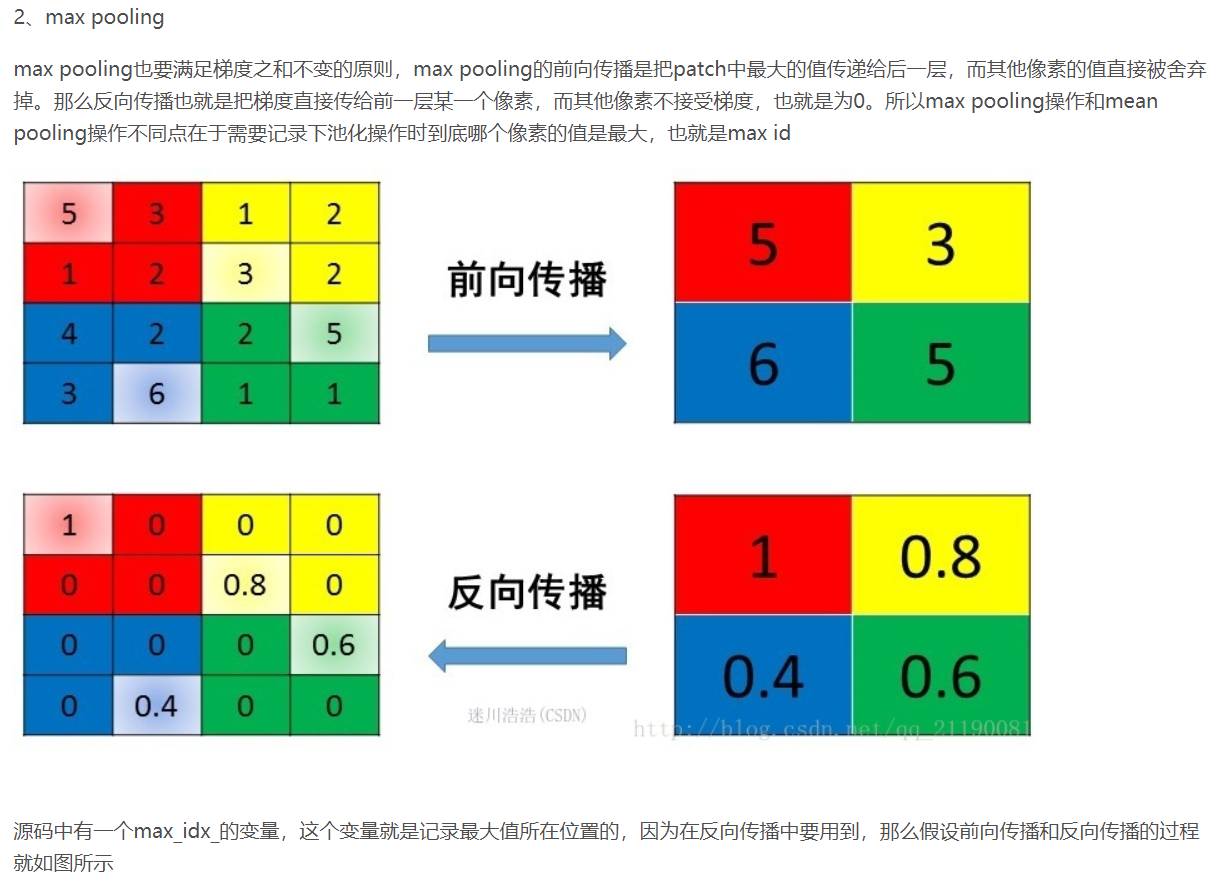
梯度爆炸 梯度消失¶
反向传播时,如果网络过深,每层梯度连乘小于1的数,值会趋向0,发生梯度消失。大于1则趋向正无穷,发生梯度爆炸。
梯度爆炸 — 梯度剪裁 :如果梯度过大则投影到一个较小的尺度上
梯度消失 — 使用ReLU, Batch Norm,Xavier初始化和He初始化