Leetcode¶
这里保存一些我做题的解答和心得
tips
面试写题的时候可以把注释也写上
写题的时候,在最前面写几个例子
二分查找类¶
二分查找¶
迭代
1def binary_search(target, array):
2 l = 0
3 r = len(array)-1
4 while l<=r:
5 mid = (l+r)//2
6 if array[mid]==target:
7 return mid
8 elif array[mid]<target:
9 l = mid + 1
10 else:
11 r = mid – 1
12 return False
递归
1def binary(stand, left, right, potions):
2 mid = (left + right) // 2
3 if left >= right:
4 return left
5 if potions[mid] >= stand:
6 return binary(stand, left, mid, potions)
7 else:
8 return binary(stand, mid + 1, right, potions)
我发现由于//2操作是向下取整,所以涉及谁+1的时候,
都是不包括mid=target的情况下left = mid+1,另一边是 right = mid,保留mid==target的可能性
搜索旋转排序数组¶
leetcode 33.
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
搜索一个给定的目标值,如果数组中存在这个目标值,则返回它的索引,否则返回 -1 。
你可以假设数组中不存在重复的元素。
你的算法时间复杂度必须是 O(log n) 级别。:
1def search(self, nums: List[int], target: int) -> int:
2 left, right = 0, len(nums) - 1
3 while left <= right:
4 mid = (left + right) // 2
5 if left == right:
6 return left if nums[left] == target else -1
7
8 if nums[mid] > nums[right]:
9 # rotate in right
10 if nums[left] <= target <= nums[mid]:
11 right = mid
12 else:
13 left = mid + 1
14 else:
15 # rotate in left
16 if nums[mid] < target <= nums[right]:
17 left = mid + 1
18 else:
19 right = mid
在排序数组中查找元素的第一个和最后一个位置¶
leetcode 34.
给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。
你的算法时间复杂度必须是 O(log n) 级别。
如果数组中不存在目标值,返回 [-1, -1]。:
1class Solution:
2 def searchRange(self, nums: List[int], target: int) -> List[int]:
3 def get_left(nums,target):
4 l,r = 0,len(nums)-1
5 res = -1
6 while l<=r:
7 mid = (l+r)//2
8 if nums[mid]==target:
9 res = mid
10 r = mid - 1
11 if mid==0:
12 return res
13 elif nums[mid]<target:
14 l = mid + 1
15 elif nums[mid]>target:
16 r = mid - 1
17 return res
18
19 def get_right(nums,target):
20 l,r = 0,len(nums)-1
21 find = 0
22 res = -1
23 while l<=r:
24 mid = (l+r)//2
25 if nums[mid]==target:
26 res = mid
27 l = mid + 1
28 if mid==len(nums)-1:
29 return res
30 elif nums[mid]<target:
31 l = mid + 1
32 elif nums[mid]>target:
33 r = mid - 1
34 return res
35
36 left = get_left(nums,target)
37 if left==-1:
38 return [-1,-1]
39 right = get_right(nums,target)
40 return [left,right]
emmmm 上面这样写好蠢啊
剑指53跟这个几乎一样
1def searchRange(self, nums: List[int], target: int) -> List[int]:
2 def get_left(nums,target):
3 l, r = 0, len(nums)-1
4 while l <= r:
5 mid = (l + r)//2
6 if nums[mid]>=target:
7 r = mid -1
8 elif nums[mid] < target:
9 l = mid + 1
10 return l
11
12 def get_right(nums,target):
13 l, r = 0, len(nums)-1
14 while l <= r:
15 mid = (l + r)//2
16 if nums[mid] <= target:
17 l = mid + 1
18 elif nums[mid] > target:
19 r = mid - 1
20 return r
21
22 l = get_left(nums,target)
23 r = get_right(nums,target)
24 if r < l:
25 return [-1, -1]
26 else:
27 return [l, r]
搜索插入位置¶
leetcode 35.
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
你可以假设数组中无重复元素。:
1class Solution:
2 def searchInsert(self, nums: List[int], target: int) -> int:
3 l,r = 0, len(nums)-1
4 while l<=r:
5 mid = (l+r)//2
6 if nums[mid]==target:
7 return mid
8 elif nums[mid]>target:
9 r = mid - 1
10 else:
11 l = mid + 1
12 return l
寻找旋转排序数组中的最小值¶
leetcode 153.
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
请找出其中最小的元素。
你可以假设数组中不存在重复元素。:
1def findMin(self, nums: List[int]) -> int:
2 n = len(nums)
3 l, r = 0, n-1
4 while l <= r:
5 mid = (l + r) // 2
6 # 中值小于右边界
7 if nums[mid] <= nums[-1]:
8 r = mid-1 # 最小值可能移动到中值
9 else: # 中值大于右边界
10 l = mid+1
11 return nums[l]
搜索旋转排序数组 II¶
leetcode 81.

假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,0,1,2,2,5,6] 可能变为 [2,5,6,0,0,1,2] )。
编写一个函数来判断给定的目标值是否存在于数组中。若存在返回 true,否则返回 false。:
1def search(self, nums: List[int], target: int) -> bool:
2 l = 0
3 r = len(nums) - 1
4 while l<=r:
5 mid = (l+r) // 2
6 if nums[mid] == target:
7 return True
8
9 if nums[mid] == nums[l]: # l和mid重复,l加一
10 l += 1
11 elif nums[mid] == nums[r]: # mid和r重复,r减一
12 r -= 1
13 elif nums[mid] > nums[l]: # l到mid是有序的,判断target是否在其中
14 if nums[l] <= target < nums[mid]: # target在其中,选择l到mid这段
15 r = mid - 1
16 else: # target不在其中,扔掉l到mid这段
17 l = mid + 1
18 elif nums[mid] < nums[r]: # mid到r是有序的,判断target是否在其中
19 if nums[mid] < target <= nums[r]:
20 l = mid + 1
21 else:
22 r = mid - 1
23 return False
0~n-1中缺失的数字¶
剑指 Offer 53 - II.
1def missingNumber(self, nums: List[int]) -> int:
2 i, j = 0, len(nums) - 1
3 while i <= j:
4 m = (i + j) // 2
5 if nums[m] == m: i = m + 1
6 else: j = m - 1
7 return i
别人的解法还是很简洁的
相比之下,我的解法有些冗余:
1def missingNumber(self, nums: List[int]) -> int:
2 l, r = 0, len(nums)
3 if nums[0] != 0:
4 return 0
5 if nums[-1] != len(nums):
6 return len(nums)
7 while l <= r:
8 mid = (l + r) // 2
9 if mid == nums[mid]:
10 l = mid
11 else:
12 r = mid
13 if r == l + 1:
14 return (nums[r] + nums[l])//2
x的平方根¶
1def mySqrt(self, x: int) -> int:
2 if x==0 or x==1:
3 return x
4 l, r = 0, x
5 while l <= r:
6 mid = (l + r)//2
7 if mid**2 == x:
8 return mid
9 elif mid**2 > x:
10 r = mid - 1
11 else:
12 l = mid + 1
13 return r
寻找峰值¶
leetcode 162.
峰值元素是指其值严格大于左右相邻值的元素。
给你一个整数数组 nums,找到峰值元素并返回其索引。数组可能包含多个峰值,在这种情况下,返回 任何一个峰值 所在位置即可。
你可以假设 nums[-1] = nums[n] = -∞ 。
你必须实现时间复杂度为 O(log n) 的算法来解决此问题。
1def findPeakElement(self, nums: List[int]) -> int:
2 def binsearch(left, right):
3 if left >= right:
4 return left
5 mid = (left + right) // 2
6 if nums[mid] < nums[mid + 1]:
7 return binsearch(mid + 1, right)
8 else:
9 return binsearch(left, mid)
10 return binsearch(0, len(nums) - 1)
O(log n) 暗示了用二分法。但是为什么可以二分呢?上述做法正确的前提有两个:
378. Kth Smallest Element in a Sorted Matrix¶
Given an n x n matrix where each of the rows and columns is sorted in ascending order, return the kth smallest element in the matrix.
Note that it is the kth smallest element in the sorted order, not the kth distinct element.
You must find a solution with a memory complexity better than O(n2).
之前都是根据index进行二分查找,这题是对值的二分查找
原理:某个m*n的二维矩阵,如果行是递增,列也是递增,那么左上角一定最小,右下角一定最大。 这里的二分不是对index二分,而是对值进行二分
相当于这里是通过left right的区间去逼近一个数,然后一行行的统计小于这个数的cnt。如果cnt < k 意味着这个mid小了,要找更大的数。
因为每次循环中都保证了第 k 小的数在 left ~ right 之间,当left==right 时,第 k 小的数即被找出,等于 right
1def kthSmallest(self, matrix: List[List[int]], k: int) -> int:
2 n = len(matrix)
3 left, right = matrix[0][0], matrix[-1][-1]
4 while left < right:
5 mid = (left + right) // 2
6 count = 0
7 j = n - 1
8 # Count the number of elements less than or equal to mid
9 for i in range(n):
10 # j = n - 1
11 while j >= 0 and matrix[i][j] > mid:
12 j -= 1
13 count += (j + 1)
14 # Adjust left or right boundary based on count
15 if count < k:
16 left = mid + 1
17 else:
18 right = mid
19 return right
小技巧
j = n - 1 这句话写在第7行比第10行要好。因为这里运用到了每列也是递增的这个规律,所以避免了重复运算
用heap堆的方法的解答看 https://knowledge-record.readthedocs.io/zh-cn/latest/leetcode/leetcode.html#id140
排序¶
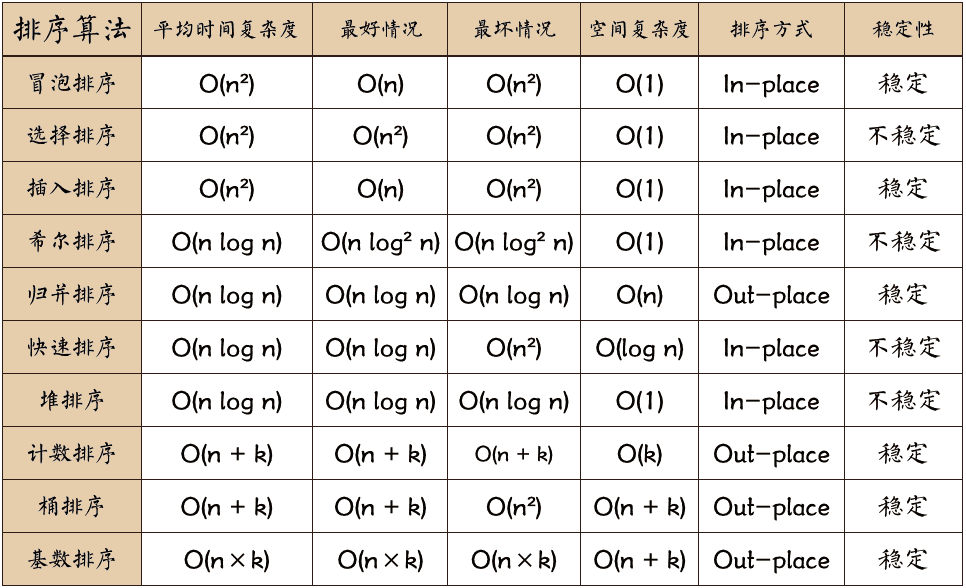
快排¶
https://www.cnblogs.com/Jinghe-Zhang/p/8986585.html
快排:
1def parttion(v, left, right):
2 key = v[left]
3 low = left
4 high = right
5 while low < high:
6 while (low < high) and (v[high] >= key):
7 high -= 1
8 v[low] = v[high]
9 while (low < high) and (v[low] <= key):
10 low += 1
11 v[high] = v[low]
12 v[low] = key
13 return low
14def quicksort(v, left, right):
15 if left < right:
16 p = parttion(v, left, right)
17 quicksort(v, left, p-1)
18 quicksort(v, p+1, right)
19 return v
20
21s = [6, 8, 1, 4, 3, 9, 5, 4, 11, 2, 2, 15, 6]
22print("before sort:",s)
23s1 = quicksort(s, left = 0, right = len(s) - 1)
24print("after sort:",s1)
另一种解答
https://leetcode.cn/problems/sort-an-array/solution/duo-chong-pai-xu-yi-wang-da-jin-kuai-pai-wgz4/
数组中的逆序对¶
剑指 Offer 51.
在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。
1def mergeSort(self, nums, tmp, left, right):
2 if left >= right:
3 return 0
4 mid = (left + right) // 2
5 inv_count = self.mergeSort(nums, tmp, left, mid) + self.mergeSort(nums, tmp, mid + 1, right)
6 i, j, pos = left, mid + 1, left
7 while i <= mid and j <= right:
8 if nums[i] <= nums[j]:
9 tmp[pos] = nums[i]
10 i += 1
11 else:
12 tmp[pos] = nums[j]
13 j += 1
14 inv_count += mid - i + 1
15 pos += 1
16 for k in range(i, mid + 1):
17 tmp[pos] = nums[k]
18 pos += 1
19 for k in range(j, right + 1):
20 tmp[pos] = nums[k]
21 inv_count += mid - i + 1
22 pos += 1
23 nums[left:right+1] = tmp[left:right+1]
24 return inv_count
25
26def reversePairs(self, nums: List[int]) -> int:
27 n = len(nums)
28 tmp = [0] * n
29 return self.mergeSort(nums, tmp, 0, n - 1)
思路是归并排序。 解法和题解可以看 https://leetcode-cn.com/problems/shu-zu-zhong-de-ni-xu-dui-lcof/solution/shu-zu-zhong-de-ni-xu-dui-by-leetcode-solution/ 视频讲解不错。
我这个代码和他的略有一点区别。(他的思路是一种解法,代码是另一种解法)。
这个代码和他的思路都是向前看的思想。 他的代码是向后看的思想
需要维护一个队列/单调栈¶
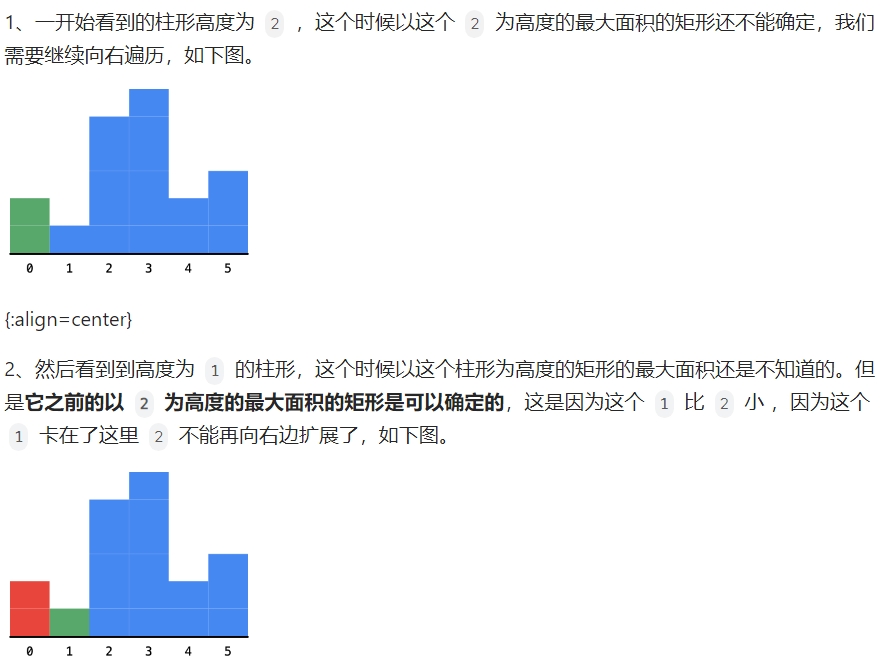
柱状图中最大的矩形¶
leetcode 84.
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
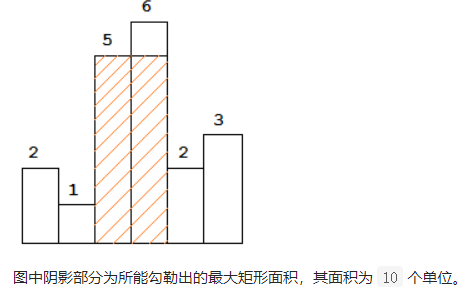
1def largestRectangleArea(self, heights: List[int]) -> int:
2 ans = heights[0]
3 queue = []
4 heights = [0] + heights + [0]
5 for i in range(len(heights)):
6 while queue and heights[i] < heights[queue[-1]]:
7 h = heights[queue.pop()]
8 w = i - queue[-1] - 1
9 ans = max(ans, h * w)
10 queue.append(i)
11 return ans
小技巧
这里有几点需要注意的地方:
- heights = [0] + heights + [0] 相当于前后加了两个“哨兵”
- w = i - queue[-1] - 1 而不是刚刚pop出来的。防止[2, 1, 2]的情况发生,不知道左边界是哪里,因为1会把第一个2给pop掉

至于为什么这里是维护一个递增队列,是为了找到以当前这个柱子的高度为最高高度的矩形面积:
股票价格跨度¶
leetcode 901.
设计一个算法收集某些股票的每日报价,并返回该股票当日价格的 跨度 。
当日股票价格的 跨度 被定义为股票价格小于或等于今天价格的最大连续日数(从今天开始往回数,包括今天)。
例如,如果未来 7 天股票的价格是 [100,80,60,70,60,75,85],那么股票跨度将是 [1,1,1,2,1,4,6] 。
1class StockSpanner:
2 def __init__(self):
3 self.stack = [(0, float(inf))]
4 self.day = 0
5
6 def next(self, price: int) -> int:
7 self.day += 1
8 while price >= self.stack[-1][1]:
9 self.stack.pop()
10 day = self.stack[-1][0]
11 self.stack.append((self.day, price))
12 return self.day - day
小技巧
还是单调栈需要注意的地方!!!其实跟上面一模一样!!!:
- self.stack = [(0, float(inf))] 相当于前面加了“哨兵”防止空栈
- 确定左边的日期标杆时要用栈里的最后一个, 而不是刚刚pop出来的。防止[2, 1, 2, 3]的情况发生,处理3时不知道左边界是哪里
滑动窗口最大值¶
1def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
2 queue = []
3 ans = []
4 for index, num in enumerate(nums):
5 while queue and num >= queue[-1][1]:
6 queue.pop()
7 if queue and queue[0][0] <= index - k:
8 queue.pop(0)
9 queue.append((index, num))
10 if index - k + 1 >= 0:
11 ans.append(queue[0][1])
12 return ans
13 # 这道题看了解析。https://leetcode.cn/problems/sliding-window-maximum/solution/shuang-xiang-dui-lie-jie-jue-hua-dong-chuang-kou-2/ 维护一个递减队列。里面存index
每日温度¶
leetcode 739.
给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。
1def dailyTemperatures(self, temperatures: List[int]) -> List[int]:
2 length = len(temperatures)
3 if length == 1:
4 return [0]
5 stack = []
6 ans = [0] * length
7 for index, temp in enumerate(temperatures):
8 while stack and temp > stack[-1][1]:
9 first = stack.pop()
10 ans[first[0]] = index - first[0]
11 stack.append((index, temp))
12 return ans
下一个更大元素 I¶
leetcode 496.
nums1 中数字 x 的 下一个更大元素 是指 x 在 nums2 中对应位置 右侧 的 第一个 比 x 大的元素。
给你两个 没有重复元素 的数组 nums1 和 nums2 ,下标从 0 开始计数,其中nums1 是 nums2 的子集。
对于每个 0 <= i < nums1.length ,找出满足 nums1[i] == nums2[j] 的下标 j ,并且在 nums2 确定 nums2[j] 的 下一个更大元素 。如果不存在下一个更大元素,那么本次查询的答案是 -1 。
返回一个长度为 nums1.length 的数组 ans 作为答案,满足 ans[i] 是如上所述的 下一个更大元素 。
1def nextGreaterElement(self, nums1: List[int], nums2: List[int]) -> List[int]:
2 store = dict()
3 queue = []
4 for num in nums2:
5 while queue and num > queue[-1]:
6 store[queue.pop()] = num
7 queue.append(num)
8 ans = []
9 for num in nums1:
10 ans.append(store.get(num, -1))
11 return ans
132 模式¶
leetcode 456.
给你一个整数数组 nums ,数组中共有 n 个整数。132 模式的子序列 由三个整数 nums[i]、nums[j] 和 nums[k] 组成,并同时满足:i < j < k 和 nums[i] < nums[k] < nums[j] 。
如果 nums 中存在 132 模式的子序列 ,返回 true ;否则,返回 false 。
1def find132pattern(self, nums: List[int]) -> bool:
2 if len(nums) < 3:
3 return False
4 k = -float(inf) # i,j,k
5 stack = [] # decrease
6 for i in range(len(nums) - 1, -1, -1):
7 if nums[i] < k:
8 return True
9 while stack and stack[-1] < nums[i]:
10 k = max(k, stack.pop())
11 stack.append(nums[i])
12 return False
https://leetcode.cn/problems/132-pattern/solution/xiang-xin-ke-xue-xi-lie-xiang-jie-wei-he-95gt/
stack[-1] < nums[i]: 一定要是< 而不是 <= 因为下一行是要更新k的。不然倒数几位是 [1, -2, 1, 1],1就会更新k了
滑动窗口¶
备注
这篇解析写的很好,总结了滑动窗口的全部题目。 https://leetcode.cn/problems/permutation-in-string/solution/by-flix-ix7f/
窗口定长,和窗口不定长度是有两种模板的。前面基本是一样的,把demand字典给统计好,有多少个字符串need统计好
但是在遍历的时候:
- 定长的时候如果big[r]不在demand中,不能直接continue,因为当窗口是此时这样覆盖的时候,big[l]也有可能在demand里面的,是需要对demand[big[l]] 做加减判断的
不定长的时候,可以continue,因为左边是固定的,还会保留在之前的位置,而不是依赖于右边去做计算
- 定长的左边index是确定的,记得l = r - lenp 这里要特别注意这里不需要l = r - lenp + 1,因为是右边左边都要动,此时处理的是左边开始滑动时刻的情况
不定长的时候,while need <= 0: 再对左边滑出的元素做demand和need的判断
最小覆盖子串¶
1def minWindow(self, s: str, t: str) -> str:
2 lens = len(s)
3 lent = len(t)
4 if lent > lens:
5 return ""
6 ans = s + "#"
7 l = 0
8 demand = dict()
9 for cha in t:
10 demand[cha] = demand.get(cha, 0) + 1
11 need = lent
12 for r in range(lens):
13 if s[r] not in demand:
14 continue
15 if demand[s[r]] > 0:
16 need -= 1
17 demand[s[r]] -= 1
18
19 while need <= 0:
20 if len(ans) > r - l + 1:
21 ans = s[l: r + 1]
22 if s[l] in demand:
23 if demand[s[l]] >= 0:
24 need += 1
25 demand[s[l]] += 1
26 l += 1
27 return ans if len(ans) <= lens else ""
最短超串¶
1def shortestSeq(self, big: List[int], small: List[int]) -> List[int]:
2 lenb = len(big)
3 need = len(small)
4 if lenb < need:
5 return []
6 minlen = lenb + 1
7 left = right = minlen
8 demand = dict()
9 for num in small:
10 demand[num] = 1
11 l = 0
12 for r in range(lenb):
13 if big[r] not in demand:
14 continue
15 if demand[big[r]] == 1:
16 need -= 1
17 demand[big[r]] -= 1
18 while need <= 0:
19 if r - l + 1 < minlen:
20 left, right = l, r
21 minlen = r - l + 1
22 if big[l] in demand:
23 if demand[big[l]] == 0:
24 need += 1
25 demand[big[l]] += 1
26 l += 1
27 return [left, right] if minlen <= lenb else []
或者:
1def shortestSeq(self, big: List[int], small: List[int]) -> List[int]:
2 i, j = 0, 0
3 store = defaultdict(int)
4 nums = len(small)
5 cnt = 0
6 set_small = set(small)
7 length = len(big)
8 ans = [0, length]
9 while j <= length - 1:
10 if big[j] in set_small:
11 store[big[j]] += 1
12 if store[big[j]] == 1:
13 cnt += 1
14 while i <= j and cnt == nums:
15 if cnt == nums and j - i < ans[1] - ans[0]:
16 ans = [i, j]
17 if big[i] not in set_small:
18 i += 1
19 else:
20 if store[big[i]] >= 2:
21 store[big[i]] -= 1
22 i += 1
23 else:
24 break
25 j += 1
26 if ans[1] == length:
27 return []
28 return ans
找到字符串中所有字母异位词¶
1def findAnagrams(self, s: str, p: str) -> List[int]:
2 lens = len(s)
3 lenp = len(p)
4 if lens < lenp:
5 return []
6 ans = []
7 demand = defaultdict(int)
8 for num in p:
9 demand[num] += 1
10 need = lenp
11 for r in range(lens):
12 if s[r] in demand:
13 if demand[s[r]] > 0:
14 need -= 1
15 demand[s[r]] -= 1
16 l = r - lenp # 这里要特别注意这里不需要+1,因为是右边左边都要动,此时处理的是左边开始滑动时刻的情况
17 if l >= 0:
18 if s[l] in demand:
19 if demand[s[l]] >= 0:
20 need += 1
21 demand[s[l]] += 1
22 if need == 0:
23 ans.append(r - lenp + 1)
24 return ans
重要
l = r - lenp 这里要特别注意这里不需要+1,因为是右边左边都要动,此时处理的是左边开始滑动时刻的情况
或者:
1def findAnagrams(self, s: str, p: str) -> List[int]:
2 i, j = 0, 0
3 demand = defaultdict(int)
4 for cha in p:
5 demand[cha] += 1
6 lens = len(s)
7 lenp = len(p)
8 needs = len(demand)
9 ans = []
10 while j <= lens - 1:
11 if s[j] in demand:
12 demand[s[j]] -= 1
13 if demand[s[j]] == 0:
14 needs -= 1
15 if j >= lenp:
16 if s[i] in demand:
17 demand[s[i]] += 1
18 if demand[s[i]] == 1:
19 needs += 1
20 i += 1
21 if needs == 0:
22 ans.append(i)
23 j += 1
24 return ans
不要忘记,只要if j >= lenp的时候,i 每次也要+1 ,与是否s[j] in demand没关系
字符串的排列¶
1def checkInclusion(self, s1: str, s2: str) -> bool:
2 lens1 = len(s1)
3 lens2 = len(s2)
4 if lens2 < lens1:
5 return False
6 need = lens1
7 demand = dict()
8 for i in s1:
9 demand[i] = demand.get(i, 0) + 1
10 for r in range(lens2):
11 if s2[r] in demand:
12 if demand[s2[r]] > 0:
13 need -= 1
14 demand[s2[r]] -= 1
15
16 l = r - lens1
17 if l >= 0:
18 if s2[l] in demand:
19 if demand[s2[l]] >= 0:
20 need += 1
21 demand[s2[l]] += 1
22 if need == 0:
23 return True
24 return False
这和上一题没区别,是简化版,只需要判断True False。代码不改都能过
209. Minimum Size Subarray Sum¶
leetcode 209.
Given an array of positive integers nums and a positive integer target, return the minimal length of a subarray whose sum is greater than or equal to target. If there is no such subarray, return 0 instead.
1def minSubArrayLen(self, target: int, nums: List[int]) -> int:
2 length = len(nums)
3 res = length + 1
4 i, j = 0, 0
5 summ = 0
6 while j <= length - 1:
7 summ += nums[j]
8 while summ >= target:
9 res = min(res, j - i + 1)
10 if res == 1:
11 return 1
12 summ -= nums[i]
13 i += 1
14 if j <= length - 1 and summ < target:
15 j += 1
16 return res if res != length + 1 else 0
3. Longest Substring Without Repeating Characters¶
leetcode 3.
Given a string s, find the length of the longest substring without repeating characters.
1def lengthOfLongestSubstring(self, s: str) -> int:
2 if not s:
3 return 0
4 length = len(s)
5 store = dict()
6 i, j = 0, 0
7 ans = 1
8 while j <= length - 1:
9 if s[j] not in store:
10 store[s[j]] = j
11 ans = max(ans, j - i + 1)
12 j += 1
13 else:
14 index = store[s[j]]
15 while i <= index:
16 del store[s[i]]
17 i += 1
18 store[s[j]] = j
19 j += 1
20 return ans
30. Substring with Concatenation of All Words¶
leetcode 30.
You are given a string s and an array of strings words. All the strings of words are of the same length.
A concatenated substring in s is a substring that contains all the strings of any permutation of words concatenated.
For example, if words = [“ab”,”cd”,”ef”], then “abcdef”, “abefcd”, “cdabef”, “cdefab”, “efabcd”, and “efcdab” are all concatenated strings. “acdbef” is not a concatenated substring because it is not the concatenation of any permutation of words. Return the starting indices of all the concatenated substrings in s. You can return the answer in any order.
简单方法:
1def findSubstring(self, s: str, words: List[str]) -> List[int]:
2 store = defaultdict(int)
3 all_words_len = len(words) * len(words[0])
4 for word in words:
5 store[word] += 1
6 def check_substrings(substrings):
7 temp_store = defaultdict(int)
8 for i in range(len(words)):
9 word = substrings[i * len(words[0]): (i + 1) * len(words[0])]
10 if word in store and temp_store[word] < store[word]:
11 temp_store[word] += 1
12 else:
13 return False
14 return True
15 ans = []
16 if len(s) - all_words_len < 0:
17 return []
18 for i in range(len(s) - all_words_len + 1):
19 if check_substrings(s[i:i + all_words_len]):
20 ans.append(i)
21 return ans
这里有个条件简化,就是所有单词都是一样的长度。这个真是帮大忙了。那么其实就很简单了。先开始统计一下words里面出现的单词及次数,然后在s里面滑动窗口,每个窗口判断是否与words里面出现的单词及次数相同。
优化:
1def findSubstring(self, s: str, words: List[str]) -> List[int]:
2 if not words or not s:
3 return []
4
5 word_length = len(words[0])
6 total_length = word_length * len(words)
7 word_count = {}
8
9 # Create a frequency map for words
10 for word in words:
11 if word in word_count:
12 word_count[word] += 1
13 else:
14 word_count[word] = 1
15
16 result = []
17
18 # Check each possible window in the string
19 for i in range(word_length):
20 left = i
21 count = 0
22 temp_word_count = {}
23
24 for j in range(i, len(s) - word_length + 1, word_length):
25 word = s[j:j + word_length]
26 if word in word_count:
27 temp_word_count[word] = temp_word_count.get(word, 0) + 1
28 count += 1
29
30 while temp_word_count[word] > word_count[word]:
31 left_word = s[left:left + word_length]
32 temp_word_count[left_word] -= 1
33 left += word_length
34 count -= 1
35
36 if count == len(words):
37 result.append(left)
38 else:
39 temp_word_count.clear()
40 count = 0
41 left = j + word_length
42
43 return result
为啥就比我写的快这么多呢…….:
1# 我的方法
2def findSubstring(self, s: str, words: List[str]) -> List[int]:
3 store = defaultdict(int)
4 word_len = len(words[0])
5 all_words_len = len(words) * word_len
6 for word in words:
7 store[word] += 1
8 def check_substrings(i, j):
9 index = i + j * word_len
10 temp_store = defaultdict(list)
11 for i in range(len(words)):
12 word = s[index + i * word_len: index + (i + 1) * word_len]
13 if word not in store:
14 return False, i + 1
15 elif word in store and len(temp_store[word]) < store[word]:
16 temp_store[word].append(i)
17 else:
18 return False, temp_store[word][0] + 1
19 return True, 1
20 ans = []
21 if len(s) - all_words_len < 0:
22 return []
23 for i in range(word_len):
24 times = (len(s) - i) // word_len
25 j = 0
26 while j <= times:
27 flag, steps = check_substrings(i, j)
28 if flag:
29 ans.append(i + j * word_len)
30 j += steps
31 return ans
和为s的连续正数序列¶
剑指 Offer 57 - II.
输入一个正整数 target ,输出所有和为 target 的连续正整数序列(至少含有两个数)。
序列内的数字由小到大排列,不同序列按照首个数字从小到大排列。
1def findContinuousSequence(self, target: int) -> List[List[int]]:
2 if target<=2:
3 return None
4 l,r = 1,1
5 res = []
6 the_sum = 1
7 while l<=target//2:
8 if the_sum<target:
9 r+=1
10 the_sum+=r
11 elif the_sum>target:
12 the_sum-=l
13 l+=1
14 elif the_sum==target:
15 res.append([x for x in range(l,r+1)])
16 the_sum-=l
17 l+=1
18 return res
经典双指针题目
二叉树¶
这个题解里面讲的二叉树说的非常好

https://leetcode.cn/problems/same-tree/solution/xie-shu-suan-fa-de-tao-lu-kuang-jia-by-wei-lai-bu-/
这个题解里面提到的比较通用的模板

前序遍历¶
递归:
1class Solution(object):
2 def preorderTraversal(self, root):
3 """
4 :type root: TreeNode
5 :rtype: List[int]
6 """
7 res = []
8 def helper(root):
9 if not root:
10 return None
11 res.append(root.val)
12 helper(root.left)
13 helper(root.right)
14 helper(root)
15 return res
迭代:
1def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
2 cur, res, stack = root, [], []
3 while cur or stack:
4 while cur:
5 res.append(cur.val)
6 stack.append(cur)
7 cur = cur.left
8 temp = stack.pop()
9 cur = temp.right
10 return res
注意点:
中序遍历¶
递归:
1class Solution:
2 def inorderTraversal(self, root: TreeNode) -> List[int]:
3 res = []
4 def helper(root):
5 if not root:
6 return None
7 helper(root.left)
8 res.append(root.val)
9 helper(root.right)
10 helper(root)
11 return res
迭代:
1class Solution:
2 def inorderTraversal(self, root: TreeNode) -> List[int]:
3 res = []
4 if not root:
5 return res
6 stack = []
7 while root or stack:
8 while root:
9 stack.append(root)
10 root = root.left
11 root = stack.pop()
12 res.append(root.val)
13 root = root.right
14 return res
后续遍历¶
递归:
1class Solution:
2 def postorderTraversal(self, root: TreeNode) -> List[int]:
3 res = []
4 def helper(root):
5 if not root:
6 return None
7 helper(root.left)
8 helper(root.right)
9 res.append(root.val)
10 helper(root)
11 return res
迭代:
1class Solution:
2 def postorderTraversal(self, root: TreeNode) -> List[int]:
3 res = []
4 if not root:
5 return res
6 stack = [root]
7 while stack:
8 node = stack.pop()
9 res.append(node.val)
10 if node.left:
11 stack.append(node.left)
12 if node.right:
13 stack.append(node.right)
14 return res[::-1]
注意点:
后序遍历是 左右中,然后我们使用了stack,所以录入的时候是左右中,(先进后出),然后对结果[::-1] 取逆序就好了。 [::-1]这个操作对 string和list 都适用的
层次遍历¶
leetcode 102. 二叉树的层次遍历:
1class Solution:
2 def levelOrder(self, root: TreeNode) -> List[List[int]]:
3 if not root:
4 return []
5 cur_level, res = [root], []
6 while cur_level:
7 temp = []
8 next_level = []
9 for node in cur_level:
10 temp.append(node.val)
11 if node.left:
12 next_level.append(node.left)
13 if node.right:
14 next_level.append(node.right)
15 res.append(temp)
16 cur_level = next_level
17 return res
相同的树¶
leetcode 100.
给定两个二叉树,编写一个函数来检验它们是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。:
1# Definition for a binary tree node.
2# class TreeNode:
3# def __init__(self, x):
4# self.val = x
5# self.left = None
6# self.right = None
7
8class Solution:
9 def isSameTree(self, p: TreeNode, q: TreeNode) -> bool:
10 if (p==None and q==None):
11 return True
12 if p==None or q == None:
13 return False
14 if p.val!= q.val:
15 return False
16 return self.isSameTree(p.left,q.left) and self.isSameTree(p.right,q.right)
树的子结构¶
剑指 Offer 26.
输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构)
B是A的子结构, 即 A中有出现和B相同的结构和节点值。:
1# Definition for a binary tree node.
2# class TreeNode:
3# def __init__(self, x):
4# self.val = x
5# self.left = None
6# self.right = None
7
8class Solution:
9 def judge(self,a,b):
10 if not b:
11 return True
12 if not a:
13 return False
14 if a.val!= b.val:
15 return False
16 return self.judge(a.left,b.left) and self.judge(a.right,b.right)
17
18 def isSubStructure(self, A: TreeNode, B: TreeNode) -> bool:
19 if (B==None or A==None):
20 return False
21 if self.judge(A,B):
22 return True
23 return self.isSubStructure(A.left,B) or self.isSubStructure(A.right,B)
我的题解
或者在第二个函数用一下伪层次遍历:
1# Definition for a binary tree node.
2# class TreeNode:
3# def __init__(self, x):
4# self.val = x
5# self.left = None
6# self.right = None
7class Solution:
8 def isSubStructure(self, A: TreeNode, B: TreeNode) -> bool:
9 def judge(a,b):
10 if not b:
11 return True
12 if not a:
13 return False
14 if a.val!= b.val:
15 return False
16 return judge(a.left,b.left) and judge(a.right,b.right)
17
18 if (A==None or B==None):
19 return False
20 queue = [A]
21 while queue:
22 node = queue.pop(0)
23 if judge(node,B):
24 return True
25 if node.left:
26 queue.append(node.left)
27 if node.right:
28 queue.append(node.right)
29 return False
二叉树的镜像¶
剑指 Offer 27.
请完成一个函数,输入一个二叉树,该函数输出它的镜像。:
1# Definition for a binary tree node.
2# class TreeNode:
3# def __init__(self, x):
4# self.val = x
5# self.left = None
6# self.right = None
7
8class Solution:
9 def mirrorTree(self, root: TreeNode) -> TreeNode:
10 '''
11 递归
12 '''
13 # if not root:
14 # return None
15 # root.left,root.right = self.mirrorTree(root.right),self.mirrorTree(root.left)
16 # return root
17 '''
18 迭代
19 '''
20 if not root:
21 return None
22 queue = [root]
23 while queue:
24 node = queue.pop(0)
25 if node:
26 node.left,node.right = node.right, node.left
27 queue.append(node.left)
28 queue.append(node.right)
29 return root
对称的二叉树¶
剑指 Offer 28.
请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的:
1# Definition for a binary tree node.
2# class TreeNode:
3# def __init__(self, x):
4# self.val = x
5# self.left = None
6# self.right = None
7
8class Solution:
9 def isSymmetric(self, root: TreeNode) -> bool:
10 if not root:
11 return True
12 this_level = [root]
13 while this_level:
14 temp = []
15 next_level = []
16 for node in this_level:
17 if not node:
18 temp.append(None)
19 else:
20 temp.append(node.val)
21 next_level.append(node.left)
22 next_level.append(node.right)
23 if temp!=temp[::-1]:
24 return False
25 this_level = next_level
26 return True
二叉树中和为某一值的路径¶
剑指 Offer 34.
好题目!!!

输入一棵二叉树和一个整数,打印出二叉树中节点值的和为输入整数的所有路径。从树的根节点开始往下一直到叶节点所经过的节点形成一条路径。:
1def pathSum(self, root: TreeNode, target: int) -> List[List[int]]:
2 res, path = [], []
3 def order(root):
4 if not root:
5 return None
6 path.append(root.val)
7 if sum(path)==target and not root.right and not root.left:
8 res.append(path[:])
9 order(root.left)
10 order(root.right)
11 path.pop()
12 order(root)
13 return res
注意!res.append(path[:]) 这里一定要是 path[:],因为list是可变变量,直接append是浅拷贝,最后res里面只会留下空数组???存疑….
和https://leetcode-cn.com/problems/recover-a-tree-from-preorder-traversal/solution/yu-dao-jiu-shen-jiu-xiang-jie-ke-bian-bu-ke-bian-s/说的不太一致
平衡二叉树¶
剑指 Offer 55 - II.
输入一棵二叉树的根节点,判断该树是不是平衡二叉树。如果某二叉树中任意节点的左右子树的深度相差不超过1,那么它就是一棵平衡二叉树。:
1# Definition for a binary tree node.
2# class TreeNode:
3# def __init__(self, x):
4# self.val = x
5# self.left = None
6# self.right = None
7
8class Solution:
9 def isBalanced(self, root: TreeNode) -> bool:
10 def helper(root):
11 if not root:
12 return 0
13 left = helper(root.left)
14 if left == -1:
15 return -1
16 right = helper(root.right)
17 if right ==-1:
18 return -1
19 if abs(left-right)>1:
20 return -1
21 else:
22 return max(left,right)+1
23 depth = helper(root)
24 if depth ==-1:
25 return False
26 else:
27 return True
从前序与中序遍历序列构造二叉树¶
leetcode 105.
根据一棵树的前序遍历与中序遍历构造二叉树。
注意:
你可以假设树中没有重复的元素。:
1# Definition for a binary tree node.
2# class TreeNode:
3# def __init__(self, x):
4# self.val = x
5# self.left = None
6# self.right = None
7
8class Solution:
9 def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode:
10 # if not (preorder and inorder):
11 # return None
12 # root = TreeNode(preorder[0])
13 # mid_idx = inorder.index(preorder[0])
14 # root.left = self.buildTree(preorder[1:mid_idx+1],inorder[:mid_idx])
15 # root.right = self.buildTree(preorder[mid_idx+1:],inorder[mid_idx+1:])
16 # return root
17 def building(preorder,inorder):
18 if not (preorder and inorder):
19 print(preorder)
20 return None
21 root_val = preorder[0]
22 root = TreeNode(root_val)
23 root_index = inorder.index(root_val)
24
25 root.left = building(preorder[1:root_index+1],inorder[:root_index])
26 root.right = building(preorder[root_index+1:],inorder[root_index+1:])
27 return root
28 return building(preorder,inorder)
从中序与后序遍历序列构造二叉树¶
leetcode 106.
根据一棵树的中序遍历与后序遍历构造二叉树。
注意:
你可以假设树中没有重复的元素。:
1# Definition for a binary tree node.
2# class TreeNode:
3# def __init__(self, x):
4# self.val = x
5# self.left = None
6# self.right = None
7
8class Solution:
9 def buildTree(self, inorder: List[int], postorder: List[int]) -> TreeNode:
10 if not (inorder and postorder):
11 return None
12 root_val = postorder[-1]
13 root = TreeNode(root_val)
14 root_index = inorder.index(root_val)
15 lens = len(inorder)
16 root.right = self.buildTree(inorder[root_index+1:],postorder[root_index:-1])
17 root.left = self.buildTree(inorder[:root_index],postorder[:root_index])
18 return root
二叉树的最近公共祖先¶
1def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
2 if not root or p==root or q==root:
3 return root
4 left = self.lowestCommonAncestor(root.left, p, q)
5 right = self.lowestCommonAncestor(root.right, p, q)
6 if not left and not right:
7 return None
8 if not left:
9 return right
10 if not right:
11 return left
12 return root
这个题解写的很好 https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/solution/236-er-cha-shu-de-zui-jin-gong-gong-zu-xian-hou-xu/ 里面的动图解释的很清楚
由于需要先知道左右子树的情况,然后决定向上返回什么。因此「后序遍历」的思想是很关键。

其实可以延伸一下,如果不止是两个节点,多个节点的也是这么写。代码以及验证如下
1class TreeNode:
2 def __init__(self, val=0, left=None, right=None):
3 self.val = val
4 self.left = left
5 self.right = right
6
7def findLCA(root, nodes_set):
8 if not root or root in nodes_set:
9 return root
10
11 left = findLCA(root.left, nodes_set)
12 right = findLCA(root.right, nodes_set)
13 print(root.val, left!=None, right!=None)
14 if left and right:
15 return root
16 return left if left else right
17
18def findLCAMultipleNodes(root, nodes):
19 if not root or not nodes:
20 return None
21
22 nodes_set = set(nodes)
23 print("需要找的节点的值为:", [node.val for node in nodes_set])
24 return findLCA(root, nodes_set)
25
26root = TreeNode(1)
27
28root.left = TreeNode(2)
29root.right = TreeNode(3)
30
31root.left.left = TreeNode(4)
32root.left.right = TreeNode(5)
33root.right.left = TreeNode(6)
34root.right.right = TreeNode(7)
35
36root.left.left.left = TreeNode(8)
37root.left.left.right = TreeNode(9)
38root.left.right.left = TreeNode(10)
39root.right.left.right = TreeNode(11)
40root.right.right.right = TreeNode(12)
41
42root.left.left.left.left = TreeNode(13)
43root.left.left.left.right = TreeNode(14)
44root.right.right.right.left = TreeNode(15)
45root.right.right.right.right = TreeNode(16)
46
47root.left.left.left.left.left = TreeNode(17)
48root.right.right.right.right.right = TreeNode(18)
49"""
50 1
51 2 3
52 4 5 6 7
53 8 9 10 11 12
54 13 14 15 16
55 17 18
56"""
57# 测试代码
58nodes = [root.left.left.left.left.left, root.left.left.left.right, root.left.left.right, root.left.right]
59lca = findLCAMultipleNodes(root, nodes)
60print("answer: ", lca.val)
路径总和 III¶
leetcode 437.
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
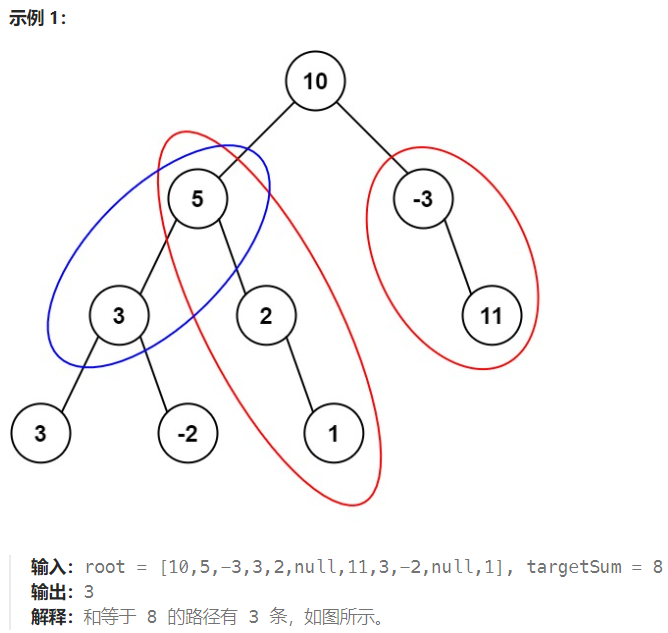
本来还觉得我的解法挺好的:
1def helper(node, sumlist):
2 if not node:
3 return 0
4 sumlist = [i + node.val for i in sumlist] + [node.val]
5 count = sumlist.count(targetSum)
6 return count + helper(node.left, sumlist) + helper(node.right, sumlist)
7return helper(root, [])
1def pathSum(self, root: Optional[TreeNode], targetSum: int) -> int:
2 def dfs(node, presum):
3 nonlocal store
4 if not node:
5 return 0
6 presum += node.val
7 cnt = store[presum - targetSum]
8 store[presum] += 1
9 cnt_all = cnt + dfs(node.left, presum) + dfs(node.right, presum)
10 store[presum] -= 1
11 return cnt_all
12 store = defaultdict(int)
13 store[0] = 1
14 return dfs(root, 0)
所以,其实不用每次遇到一个新的节点,都把所有能得到的组合都列出来。

其次,可以用一个字典,记录的是本路径上前缀和出现的次数(关于前缀和可以看leetcode第560题)
然后当完成这个节点的计算时,需要恢复原本状态,就是这个前缀和出现次数-1就行
一开始初始化字典的时候需要 store[0] = 1 因为如果没有这个的话,如果某条路径下全部的前缀和刚好是target,则无法被识别
然后 第八行的 store[presum] += 1 不能放在 cnt = store[presum - targetSum] 前面。 暂时还没想清楚。这个案例过不了 root=[1], tar=0
????????
Leetcode 426. Convert Binary Search Tree to Sorted Doubly Linked List (BST转换成双链表)¶
tt面试题
将BST结构转化成双链表结构,使得每一个节点连接他的前驱结点和后继节点,并且头,尾两个节点也要相连。要求不开额外空间
1"""
2将BST结构转化成双链表结构,使得每一个节点连接他的前驱结点和后继节点,并且头,尾两个节点也要相连。要求不开额外空间
3"""
4
5class Node():
6 def __init__(self, val=None, left=None, right=None):
7 self.val = val
8 self.left = left
9 self.right = right
10
11def tree2linkedlist(node):
12 def inorder(node):
13 nonlocal last, head
14 if not node:
15 return None
16 inorder(node.left)
17 if not last:
18 head = node
19 else:
20 last.right = node
21 node.left = last
22 last = node
23 inorder(node.right)
24 head, last = None, None
25 inorder(node)
26 return head
27
28node = Node(1)
29node.left = Node(2)
30node.right = Node(3)
31node.left.left = Node(4)
32node.left.right = Node(5)
33node.right.left = Node(6)
34node.right.right = Node(7)
35head = tree2linkedlist(node)
36while head:
37 print(head.val)
38 head = head.right
好吧,下面的内容是我理解错题意了。
将一个二叉树的中序遍历转换成双向链表。要求原地转换,自己写完整的代码,自己构造测试案例:
1class Node():
2 def __init__(self, val=None, left=None, right=None, next=None, prev=None):
3 self.val = val
4 self.left = left
5 self.right = right
6 self.next= next
7 self.prev = prev
8
9def tree2linkedlist(node):
10 def inorder(node):
11 nonlocal head, last
12 if not node:
13 return None
14 inorder(node.left)
15 if not head.val:
16 head = node
17 last = node
18 else:
19 node.prev = last
20 last.next = node
21 last = node
22 inorder(node.right)
23 head, last = Node(), Node()
24 inorder(node)
25 return head
26
27node = Node(1)
28node.left = Node(2)
29node.right = Node(3)
30node.left.left = Node(4)
31node.left.right = Node(5)
32node.right.left = Node(6)
33node.right.right = Node(7)
34head = tree2linkedlist(node)
35while head:
36 print(head.val)
37 head = head.next
我建议每次code interview之前,把常见的模板都背一遍。免得不记得中序遍历
然后if not head.val 这里要注意不是 if not head
不是存上一个节点是谁,而是存中序遍历的上一个节点是谁
请看下一道题。有点像,但别搞混了
114. Flatten Binary Tree to Linked List¶
Given the root of a binary tree, flatten the tree into a “linked list”:
1def flatten(self, root: Optional[TreeNode]) -> None:
2 """
3 Do not return anything, modify root in-place instead.
4 """
5 def preorder(node):
6 nonlocal last
7 if not node:
8 return None
9 preorder(node.right)
10 preorder(node.left)
11 if not last:
12 last = node
13 else:
14 node.right = last
15 node.left = None
16 last = node
17 last = None
18 preorder(root)
这里由于是先序遍历,所以是preorder(node.right),preorder(node.left) 最后再处理当前node。而且和上一题不一样的是,这里还是用right而不是next。 所以直接像上一题一样会出现丢失原本的right的情况。这里可以用后续遍历,这样不影响之前的值
这里要特别注意,last = None 而不是last=TreeNode(None)
或者这样也可以,存一下:
1def flatten(self, root: Optional[TreeNode]) -> None:
2 """
3 Do not return anything, modify root in-place instead.
4 """
5 def preorder(node):
6 nonlocal last
7 if not node:
8 return None
9 l, r = node.left, node.right
10 if not last:
11 last = node
12 else:
13 last.right = node
14 last.left = None
15 last = node
16 preorder(l)
17 preorder(r)
18 last = None
19 preorder(root)
1530. Number of Good Leaf Nodes Pairs¶
You are given the root of a binary tree and an integer distance. A pair of two different leaf nodes of a binary tree is said to be good if the length of the shortest path between them is less than or equal to distance.
Return the number of good leaf node pairs in the tree.
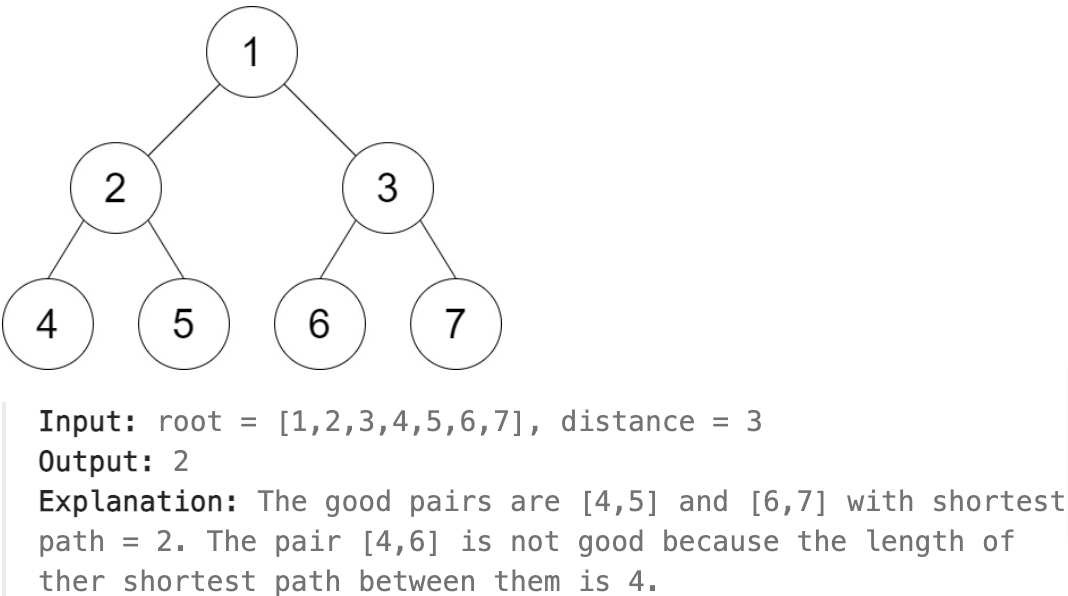
1def countPairs(self, root: TreeNode, distance: int) -> int:
2 def postorder(node):
3 nonlocal cnt
4 if not node:
5 return []
6 if not node.left and not node.right:
7 return [0]
8 left = postorder(node.left)
9 right = postorder(node.right)
10 for i in left:
11 for j in right:
12 if i + j + 2 <= distance:
13 cnt += 1
14 return [n + 1 for n in left] + [m + 1 for m in right]
15 if distance < 2:
16 return 0
17 cnt = 0
18 postorder(root)
19 return cnt
能想到后序遍历就已经成功了一半。注意这里要:
if not node:
return []
if not node.left and not node.right:
return [0]
1028. 从先序遍历还原二叉树¶
我们从二叉树的根节点 root 开始进行深度优先搜索。
在遍历中的每个节点处,我们输出 D 条短划线(其中 D 是该节点的深度),然后输出该节点的值。(如果节点的深度为 D,则其直接子节点的深度为 D + 1。根节点的深度为 0)。
如果节点只有一个子节点,那么保证该子节点为左子节点。
给出遍历输出 S,还原树并返回其根节点 root。
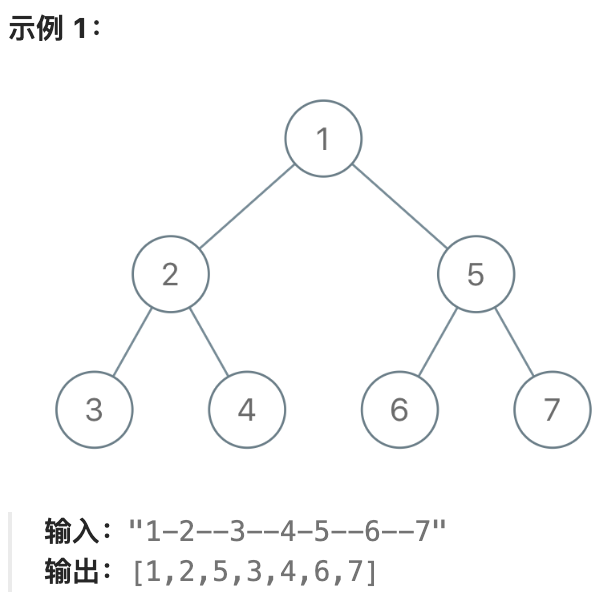
1def recoverFromPreorder(self, traversal: str) -> Optional[TreeNode]:
2 if len(traversal) == 1:
3 return TreeNode(traversal[0])
4 traversal += "-"
5 store = []
6 cnt = 0
7 val = int(traversal[0])
8 for i in range(1, len(traversal)):
9 if traversal[i] == "-":
10 if traversal[i - 1].isdigit():
11 store.append((val, cnt))
12 cnt = 1
13 val = 0
14 else:
15 cnt += 1
16 else:
17 val = val * 10 + int(traversal[i])
18 # print(store) [(1, 0), (2, 1), (3, 2), (4, 2), (5, 1), (6, 2), (7, 2)]
19 head = node = TreeNode(store[0][0])
20 stack = []
21 level = 0
22 for val, cnt in store[1:]:
23 if cnt == level + 1:
24 node.left = TreeNode(val)
25 stack.append((node, level))
26 node = node.left
27 level += 1
28 else:
29 while stack and level + 1 != cnt:
30 node, level = stack.pop()
31 node.right = TreeNode(val)
32 node = node.right
33 level += 1
34 return head
哈哈,我自己做出来的hard题。
建议可以先把先序遍历的模板写上去。这样会更有思路
二叉搜索树 Binary Search Tree¶
Binary Search Tree的性质¶
1、对于 BST 的每一个节点 node,左子树节点的值都比 node 的值要小,右子树节点的值都比 node 的值大。
2、对于 BST 的每一个节点 node,它的左侧子树和右侧子树都是 BST。
因此二叉搜索树的中序遍历,是一个递增的序列. 这个性质能解决绝大部分的题目。而且很多题目不需要用list保存全部的值,只需要一个变量保存上一个就行
230. Kth Smallest Element in a BST¶
Given the root of a binary search tree, and an integer k, return the kth smallest value (1-indexed) of all the values of the nodes in the tree.
这里是中序遍历就行。但是这里不需要用list保存全部的值:
1def kthSmallest(self, root: Optional[TreeNode], k: int) -> int:
2 cur, stack = root, []
3 while cur or stack:
4 while cur:
5 stack.append(cur)
6 cur = cur.left
7 cur = stack.pop()
8 ans = cur.val
9 k -= 1
10 if k == 0:
11 return ans
12 cur = cur.right
follow up: 进阶:如果二叉搜索树经常被修改(插入/删除操作)并且你需要频繁地查找第 k 小的值,你将如何优化算法?

538. Convert BST to Greater Tree¶
Given the root of a Binary Search Tree (BST), convert it to a Greater Tree such that every key of the original BST is changed to the original key plus the sum of all keys greater than the original key in BST.
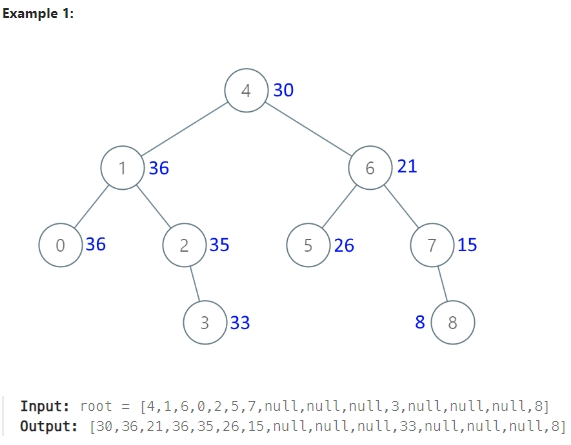
1def convertBST(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
2 def helper(root):
3 nonlocal summ
4 if not root:
5 return
6 helper(root.right)
7 summ += root.val
8 root.val = summ
9 helper(root.left)
10 summ = 0
11 helper(root)
12 return root
不过:
1、helper(root)能否把summ 也变成参数传进去?
2、为什么这里需要nonlocal summ。但是中序遍历的时候不需要:
1def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
2 def helper(root):
3 if not root:
4 return
5 helper(root.left)
6 res.append(root.val)
7 helper(root.right)
8 res = []
9 helper(root)
10 return res
解答:
1、:
1def convertBST(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
2 def helper(root, summ):
3 if not root:
4 return summ
5 summ = helper(root.right, summ)
6 summ += root.val
7 root.val = summ
8 summ = helper(root.left, summ)
9 return summ
10 summ = 0
11 summ = helper(root, summ)
12 return root
那么这里的 第4行,第9行都记得要return summ
2、:
1def convertBST(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
2 def helper(root):
3 if not root:
4 return
5 helper(root.right)
6 root.val += summ[0]
7 summ[0] = root.val
8 helper(root.left)
9 summ = [0]
10 helper(root)
11 return root
这样就可以了。其实正规的写法应该还是需要nonlocal的。中序遍历那里为什么可以不nonlocal:是因为list是可变类型变量,而int是不可变类型变量。所以在小函数里面改变了这个值,会造成混淆,不知道是局部变量还是全局变量
530. Minimum Absolute Difference in BST¶
Given the root of a Binary Search Tree (BST), return the minimum absolute difference between the values of any two different nodes in the tree.
1def getMinimumDifference(self, root: Optional[TreeNode]) -> int:
2 def helper(root):
3 nonlocal pre
4 nonlocal ans
5 if not root:
6 return
7 helper(root.left)
8 ans = min(ans, root.val - pre)
9 pre = root.val
10 helper(root.right)
11 pre = -float(inf)
12 ans = float(inf)
13 helper(root)
14 return ans
这里还是中序遍历。但是不需要用个list保存。只需要储存前一个值就行
173. Binary Search Tree Iterator¶
Implement the BSTIterator class that represents an iterator over the in-order traversal of a binary search tree (BST):
You may assume that next() calls will always be valid. That is, there will be at least a next number in the in-order traversal when next() is called.

这题的题目比较难理解…
最普通的做法就是,先通过中序遍历,把节点都存下来,然后一个个的pop出来:
1class BSTIterator:
2 def __init__(self, root: Optional[TreeNode]):
3 self.queue = []
4 self.inorder(root)
5
6 def inorder(self, root):
7 if not root:
8 return
9 self.inorder(root.left)
10 self.queue.append(root.val)
11 self.inorder(root.right)
12
13 def next(self) -> int:
14 return self.queue.pop(0)
15
16 def hasNext(self) -> bool:
17 return len(self.queue) > 0
还有一种做法是使用单调栈。就是在中序遍历的时候 不实用递归,而是迭代。而且是分步骤进行的。这个对于中序遍历迭代的代码理解比较高。之后再看看
??????
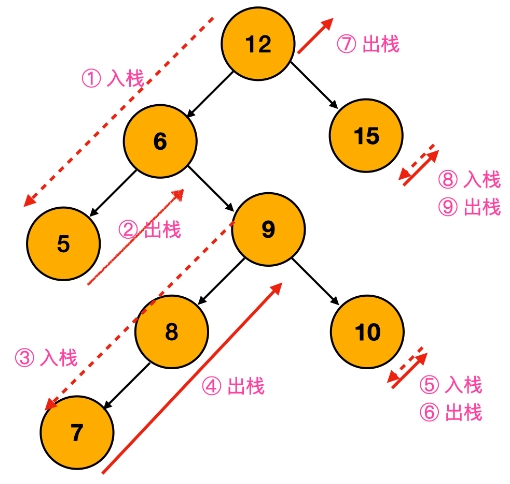
1class BSTIterator:
2 def __init__(self, root: Optional[TreeNode]):
3 self.stack = []
4 while root:
5 self.stack.append(root)
6 root = root.left
7
8 def next(self) -> int:
9 cur = self.stack.pop()
10 node = cur.right
11 while node:
12 self.stack.append(node)
13 node = node.left
14 return cur.val
15
16 def hasNext(self) -> bool:
17 return len(self.stack) > 0
98. Validate Binary Search Tree¶
Given the root of a binary tree, determine if it is a valid binary search tree (BST).
有一种迭代的思想。从上到下可以很好理解。
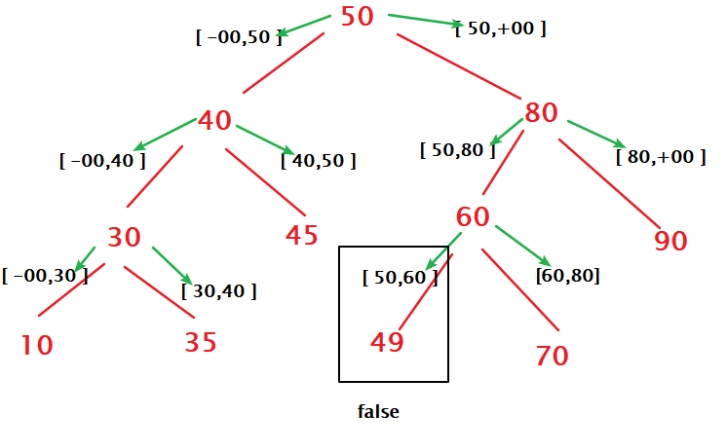
1def isValidBST(self, root: Optional[TreeNode]) -> bool:
2 def helper(root, mini, maxi):
3 if not root:
4 return True
5 if not mini < root.val < maxi:
6 return False
7 return helper(root.left, mini, root.val) and helper(root.right, root.val, maxi)
8 return helper(root, -float(inf), float(inf))
如果从下到上,则是需要判断: (右子树的最小值 < 当前节点) 且 (左子树最大值 > 当前节点):
1def isValidBST(self, root: Optional[TreeNode]) -> bool:
2 def helper(root):
3 nonlocal flag
4 if not flag:
5 return [root.val, root.val]
6 l1, r2 = root.val, root.val
7 l2, r1 = -float(inf), float(inf)
8 if root.left:
9 l1, l2 = helper(root.left)
10 if root.right:
11 r1, r2 = helper(root.right)
12 if not l2 < root.val < r1:
13 flag = False
14 return [l1, r2]
15 flag = True
16 helper(root)
17 return flag
当然,中序遍历一下也是可以的。同样的,这里也不需要用list保存全部,只需要一个pre就行:
1def isValidBST(self, root: Optional[TreeNode]) -> bool:
2 def helper(root):
3 nonlocal pre
4 nonlocal flag
5 if not root or not flag:
6 return
7 helper(root.left)
8 if pre >= root.val:
9 flag = False
10 pre = root.val
11 helper(root.right)
12 pre = -float(inf)
13 flag = True
14 helper(root)
15 return flag
701. Insert into a Binary Search Tree¶
You are given the root node of a binary search tree (BST) and a value to insert into the tree. Return the root node of the BST after the insertion. It is guaranteed that the new value does not exist in the original BST.
Notice that there may exist multiple valid ways for the insertion, as long as the tree remains a BST after insertion. You can return any of them.
之间按照左小右大的性质去找:
1def insertIntoBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:
2 node = root
3 if not root:
4 return TreeNode(val)
5 while node:
6 if node.val > val:
7 if node.left:
8 node = node.left
9 else:
10 node.left = TreeNode(val)
11 return root
12 else:
13 if node.right:
14 node = node.right
15 else:
16 node.right = TreeNode(val)
17 return root
如果利用中序遍历:
1def insertIntoBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:
2 cur, stack, pre = root, [], TreeNode(float(inf))
3 if not root:
4 return TreeNode(val)
5 while stack or cur:
6 while cur:
7 stack.append(cur)
8 cur = cur.left
9 cur = stack.pop()
10 if cur.val > val:
11 break
12 pre = cur
13 cur = cur.right
14 if pre.val == float(inf):
15 cur.left = TreeNode(val)
16 if not pre.right:
17 pre.right = TreeNode(val)
18 else:
19 pre = pre.right
20 while pre.left:
21 pre = pre.left
22 pre.left = TreeNode(val)
23 return root
中序遍历的特性: 1. 是递增的 2.如果节点在pre和cur之间,那么插入以后,遍历的时候也应该先遍历pre,再val,再cur。所以,cur的“虚空”上一个节点是pre.right(如果没有),如果有的话,那就是pre.right再一路往left下走
450. Delete Node in a BST¶
Given a root node reference of a BST and a key, delete the node with the given key in the BST. Return the root node reference (possibly updated) of the BST.
Basically, the deletion can be divided into two stages:
Search for a node to remove.
If the node is found, delete the node.:
1def deleteNode(self, root: Optional[TreeNode], key: int) -> Optional[TreeNode]:
2 if not root:
3 return None
4 if root.val > key:
5 root.left = self.deleteNode(root.left, key)
6 elif root.val < key:
7 root.right = self.deleteNode(root.right, key)
8 else:
9 if not root.left and not root.right:
10 return None
11 elif not root.left:
12 return root.right
13 elif not root.right:
14 return root.left
15 else:
16 temp = root.right
17 while temp.left:
18 temp = temp.left
19 temp.left = root.left
20 root = root.right
21 return root
22 return root
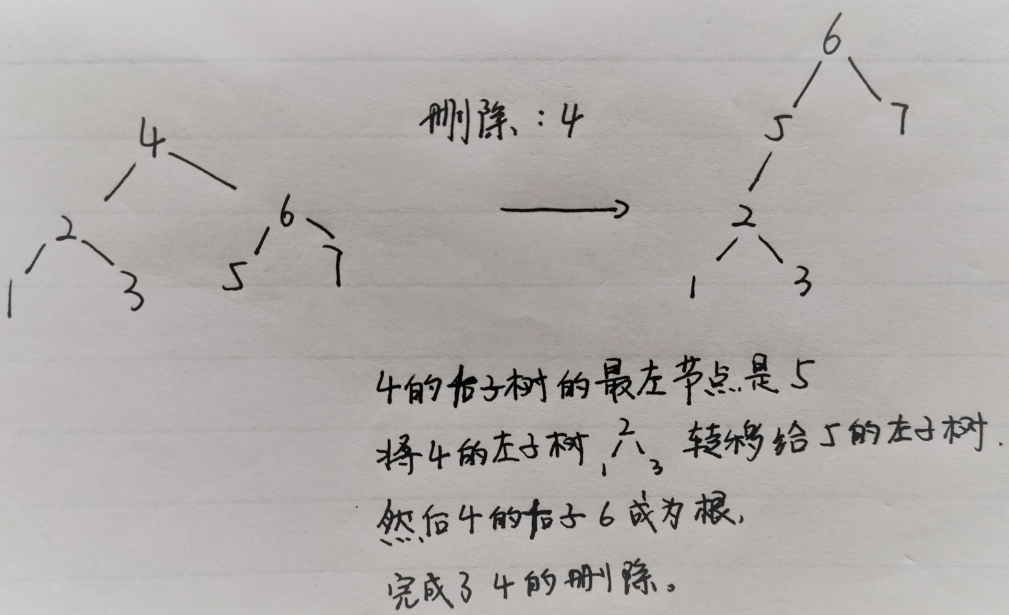
这种自己调用自己的方法我掌握的不好 多看多练
??????
99. Recover Binary Search Tree¶
You are given the root of a binary search tree (BST), where the values of exactly two nodes of the tree were swapped by mistake. Recover the tree without changing its structure.
1def recoverTree(self, root: TreeNode) -> None:
2 """
3 Do not return anything, modify root in-place instead.
4 """
5 x, y = None, None
6 stack, cur, pre = [], root, TreeNode(-float(inf))
7 while stack or cur:
8 while cur:
9 stack.append(cur)
10 cur = cur.left
11 cur = stack.pop()
12 if cur.val < pre.val:
13 if not x:
14 x = pre
15 y = cur
16 pre = cur
17 cur = cur.right
18 x.val, y.val = y.val, x.val
这道题也是用中序遍历的方法。因为两个交换了顺序之后,肯定不满足中序递增的情况了。可以设置x y 来记录
多举几个例子方便理解:
1 2 3 4 5 6
5 2 3 4 1 6
1 2 3 5 4 6
有时候是会有两个值都反常,比如第二行。那么需要交换5和1.分别是之前的pre 和 之后的 cur
但是有时候只有一个值反常,比如第三行,那么也是需要交换pre和cur。所以不管怎样,只要发生了反常,就要记录cur
其他题目¶
剑指 Offer 36 二叉搜索树与双向链表 *(收费)https://leetcode.com/problems/convert-binary-search-tree-to-sorted-doubly-linked-list/ -> (牛客网)https://www.nowcoder.com/practice/947f6eb80d944a84850b0538bf0ec3a5?tpId=13&tqId=11179&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking
剑指 Offer 33 二叉搜索树的后序遍历序列 (收费)https://leetcode.com/problems/verify-preorder-sequence-in-binary-search-tree/ -> (先序遍历)https://leetcode.com/problems/verify-preorder-serialization-of-a-binary-tree/
leetcode 95–99
二叉搜索树的最近公共祖先¶
leetcode 235.
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先:
1def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
2 a = min(p.val,q.val)
3 b = max(p.val,q.val)
4 def helper(root,a,b):
5 if a<= root.val <= b:
6 return root
7 elif root.val <a:
8 return helper(root.right,a,b)
9 else:
10 return helper(root.left,a,b)
11 if not root:
12 return None
13 r = helper(root,a,b)
14 return r
动态规划¶
数组中出现次数超过一半的数字¶
剑指 Offer 39.
数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 1:
1def majorityElement(self, nums: List[int]) -> int:
2 if nums==[]:
3 return []
4 count = 1
5 res = nums[0]
6 for i in range(1,len(nums)):
7 if nums[i]==res:
8 count+=1
9 else:
10 count -=1
11 if count ==0:
12 res = nums[i]
13 count = 1
14 return res
一个漂亮的解法。维护一个res和count。如果当前遍历到的数和res相等,count就+1,不不然就-1。减到0 res就换人。 记得换人后把count重新设为1 !!!
连续子数组的最大和/最大子序和¶
剑指 Offer 42. leetcode 53. (题目一样的)
输入一个整型数组,数组里有正数也有负数。数组中的一个或连续多个整数组成一个子数组。求所有子数组的和的最大值。
要求时间复杂度为O(n)。
示例1:
1def maxSubArray(self, nums: List[int]) -> int:
2 ans = nums[0]
3 for i in range(1, len(nums)):
4 nums[i] = max(0, nums[i - 1]) + nums[i]
5 ans = max(ans, nums[i])
6 return ans
如果前面的累加和已经小于0了,就不要了
更进一步,请看下一题:
乘积最大子数组¶
leetcode 152.
给你一个整数数组 nums ,请你找出数组中乘积最大的连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。
示例 1:
1def maxProduct(self, nums: List[int]) -> int:
2 if not nums: return
3 res = nums[0]
4 pre_max = nums[0]
5 pre_min = nums[0]
6 for num in nums[1:]:
7 cur_max = max(pre_max * num, pre_min * num, num)
8 cur_min = min(pre_max * num, pre_min * num, num)
9 res = max(res, cur_max)
10 pre_max = cur_max
11 pre_min = cur_min
12 return res
还有一种解法暂时没太明白,也先记录下来。
思路三:根据符号的个数 [^2]
1def maxProduct(self, nums: List[int]) -> int:
2 reverse_nums = nums[::-1]
3 for i in range(1, len(nums)):
4 nums[i] *= nums[i - 1] or 1
5 reverse_nums[i] *= reverse_nums[i - 1] or 1
6 return max(nums + reverse_nums)
再看一题
1186. Maximum Subarray Sum with One Deletion¶
!!!??!!???
把数组排成最小的数¶
剑指 Offer 45.
输入一个非负整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。
示例 1:
1def minNumber(self, nums: List[int]) -> str:
2 if nums==[]:
3 return ''
4 nums = [str(x) for x in nums]
5 for i in range(0,len(nums)-1):
6 for j in range(i+1,len(nums)):
7 if int(nums[i] + nums[j] > nums[j] + nums[i]):
8 nums[i], nums[j] = nums[j], nums[i]
9 return ''.join(nums)
O(n2)的解法,类似冒泡排序。
有一种O(nlogn)的解法,类似于快排。暂时不理解,先记录下来:
1def minNumber(self, nums: List[int]) -> str:
2 def fast_sort(l , r):
3 if l >= r: return
4 i, j = l, r
5 while i < j:
6 while strs[j] + strs[l] >= strs[l] + strs[j] and i < j: j -= 1
7 while strs[i] + strs[l] <= strs[l] + strs[i] and i < j: i += 1
8 strs[i], strs[j] = strs[j], strs[i]
9 strs[i], strs[l] = strs[l], strs[i]
10 fast_sort(l, i - 1)
11 fast_sort(i + 1, r)
12
13 strs = [str(num) for num in nums]
14 fast_sort(0, len(strs) - 1)
15 return ''.join(strs)
里面涉及到一些数学推导与证明,评论区和下面其他大佬的解答里面有证明。
买卖股票的最佳时机¶
leetcode 121. / 剑指 Offer 63.
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0
1def maxProfit(self, prices: List[int]) -> int:
2 if len(prices) <= 1:
3 return 0
4 ans = 0
5 temp = float(inf)
6 for num in prices:
7 temp = min(temp, num)
8 ans = max(ans, num - temp)
9 return ans
买卖股票的最佳时机 II¶
leetcode 122.
给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
返回 你能获得的 最大 利润 。
1def maxProfit(self, prices: List[int]) -> int:
2 if len(prices) <= 1:
3 return 0
4 dp = [[0, 0] for _ in range(len(prices))]
5 dp[0][1] = -prices[0]
6 for i in range(1, len(prices)):
7 dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] + prices[i])
8 dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] - prices[i])
9 return dp[-1][0]
这一题和上一题的区别在于,可以多次买卖。所以不是一锤子交易了
在动态规划的时候,每一天都存在两种情况———————手里有一股,手里清仓了。而当天具体能获得的利润其实取决于昨天的两种状态
因此是一个二维的动态规划。dp[i][0]表示为,第i天手里没有股票了的最大利润;dp[i][1]表示为,第i天手里还有1股的最大利润
这里可以理解为,每次就买卖1股,单价是prices[i]
备注
注意这里dp需要是dp = [[0, 0] for _ in range(len(prices))] 而不是 dp = [[0, 0] * (len(prices))]
这样会变成1维数组
这里其实还可以简化: 由于第i天的dp之和第i-1天有关系。可以变成一维数组
1def maxProfit(self, prices: List[int]) -> int:
2 if len(prices) <= 1:
3 return 0
4 dp = [0, -prices[0]]
5 for i in range(1, len(prices)):
6 dp[0], dp[1]= max(dp[0], dp[1] + prices[i]), max(dp[1], dp[0] - prices[i])
7 return dp[0]
所以leetcode 714题还要收手续费的话,变化也就是:
dp[0], dp[1]= max(dp[0], dp[1] + prices[i]), max(dp[1], dp[0] - prices[i] - fee)
买卖股票的最佳时机 III¶
leetcode 123.
给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
1def maxProfit(self, prices: List[int]) -> int:
2 if len(prices) <= 1:
3 return 0
4 dp = [[0, -float(inf), -float(inf), -float(inf)] for _ in range(len(prices))]
5 dp[0][0] = -prices[0]
6 for i in range(1, len(prices)):
7 dp[i][0] = max(dp[i - 1][0], -prices[i])
8 dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i])
9 dp[i][2] = max(dp[i - 1][2], dp[i - 1][1] - prices[i])
10 dp[i][3] = max(dp[i - 1][3], dp[i - 1][2] + prices[i])
11 return max(dp[-1][1], dp[-1][3], 0)
这里dp[i][0、1、2、3]分别指的是 在第i天第一次买、第一次卖、第二次买、第二次卖 时的最大利润
这里其实还有一种解答,暂时还没理解啥意思??????
1def maxProfit(self, prices: List[int]) -> int:
2 ret = [0 for i in range(len(prices))]
3 for i in range(2):
4 currMaxProfit = 0
5 for j in range(1, len(prices)):
6 currMaxProfit = max(ret[j], currMaxProfit + prices[j] - prices[j - 1])
7 ret[j] = max(ret[j - 1], currMaxProfit)
8 return ret[-1]
买卖股票的最佳时机含冷冻期¶
leetcode 309.
给定一个整数数组prices,其中第 prices[i] 表示第 i 天的股票价格 。
设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票):
卖出股票后,你无法在第二天买入股票 (即冷冻期为 1 天)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
1def maxProfit(self, prices: List[int]) -> int:
2 if len(prices) == 1:
3 return 0
4 dp = [[0, 0, 0] for _ in range(len(prices))]
5 dp[0][2] = -prices[0]
6 if len(prices) == 2:
7 return max(0, prices[1] - prices[0])
8 # 今天没卖但是也没持有, 今天刚卖完, 持有股票
9 dp[1][1] = prices[1] - prices[0]
10 dp[1][2] = max(-prices[0], -prices[1])
11 for i in range(2, len(prices)):
12 dp[i][0] = max(dp[i - 1][0], dp[i - 1][1])
13 dp[i][1] = dp[i - 1][2] + prices[i]
14 dp[i][2] = max(dp[i - 1][2], dp[i - 1][0] - prices[i])
15 return max(dp[-1])
由于当天未持有的状态需要拆分成刚刚卖完和本来就没有。
所以这里每天需要三个空格,分别表示 今天没卖但是也没持有, 今天刚卖完, 持有股票
礼物的最大价值¶
剑指 Offer 47.
示例 1:
输入: | [ | [1,3,1], | [1,5,1], | [4,2,1] | ] | 输出: 12 | 解释: 路径 1→3→5→2→1 可以拿到最多价值的礼物
1def maxValue(self, grid: List[List[int]]) -> int:
2 if grid==[]:
3 return 0
4 for j in range(len(grid)):
5 for i in range(len(grid[0])):
6 if i==0 and j==0:
7 continue
8 if j==0 and i!=0:
9 grid[j][i] += grid[j][i-1]
10 if i==0 and j!=0:
11 grid[j][i] += grid[j-1][i]
12 if i!=0 and j!=0:
13 grid[j][i] += max(grid[j-1][i],grid[j][i-1])
14 return grid[-1][-1]
注意,最后一个if(讨论中间的格子),不要写else…..血的教训。依然是if,不然会和第三个if 组成if…else。
除了第一行和第一列,其他的情况: 选择 max(左边,上面)+ 自己那一格
更方便的做法是在左边和上面都补上一列0,这样就不用分四种情况讨论了,公式能通用。
请看下一题:
不同路径 II¶
leetcode 63.

1def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int:
2 m = len(obstacleGrid)
3 n = len(obstacleGrid[0])
4 if obstacleGrid[0][0]==1:
5 return 0
6 res = [[0 for _ in range(n)] for _ in range(m)]
7 res[0][0]=1
8 for i in range(1,m):
9 if obstacleGrid[i-1][0]==0 and res[i-1][0]==1 and obstacleGrid[i][0] == 0:
10 res[i][0]=1
11 for j in range(1,n):
12 if obstacleGrid[0][j-1]==0 and res[0][j-1]==1 and obstacleGrid[0][j] == 0:
13 res[0][j]=1
14 if m==1 or n==1:
15 return res[-1][-1]
16 for i in range(1,m):
17 for j in range(1,n):
18 if obstacleGrid[i][j]==1:
19 res[i][j]=0
20 else:
21 res[i][j]= res[i-1][j] + res[i][j-1]
22 return res[-1][-1]
请再看一题:
最小路径和¶
1def minPathSum(self, grid: List[List[int]]) -> int:
2 if len(grid)==1:
3 return sum(grid[0])
4 if len(grid[0])==1:
5 the_sum = 0
6 for x in grid:
7 the_sum += x[0]
8 return the_sum
9 for i in range(1,len(grid)):
10 grid[i][0] += grid[i-1][0]
11 for j in range(1,len(grid[0])):
12 grid[0][j] += grid[0][j-1]
13 for i in range(1,len(grid)):
14 for j in range(1,len(grid[0])):
15 grid[i][j] += min(grid[i-1][j],grid[i][j-1])
16 return grid[-1][-1]
最长不含重复字符的子字符串¶
剑指 Offer 48.
请从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度。
示例 1:
1def lengthOfLongestSubstring(self, s: str) -> int:
2 if len(s)<=1:
3 return len(s)
4 i = 0
5 res = 1
6 for j in range(1,len(s)):
7 if s[j] not in s[i:j]:
8 pass
9 else:
10 i = s[i:j].index(s[j]) + i + 1
11 res = max(res,j-i+1)
12 return res
丑数¶
leetcode 263.
丑数 就是只包含质因数 2、3 和 5 的正整数。
给你一个整数 n ,请你判断 n 是否为 丑数 。如果是,返回 true ;否则,返回 false 。
1def isUgly(self, n: int) -> bool:
2 if n <= 0:
3 return False
4 while n:
5 if n % 5 == 0:
6 n /= 5
7 continue
8 elif n % 3 == 0:
9 n /= 3
10 continue
11 elif n % 2 == 0:
12 n /= 2
13 continue
14
15 if n == 1:
16 return True
17 return False
丑数 II¶
leetcode 264. / 剑指 Offer 49.
我们把只包含质因子 2、3 和 5 的数称作丑数(Ugly Number)。求按从小到大的顺序的第 n 个丑数。
1def nthUglyNumber(self, n: int) -> int:
2 index= 1
3 ugly = [1]
4 dp2,dp3,dp5 = 0,0,0
5 while index <= n-1:
6 cur = min(2*ugly[dp2], 3*ugly[dp3], 5*ugly[dp5])
7 if cur == 2*ugly[dp2]:
8 dp2 += 1
9 if cur == 3*ugly[dp3]:
10 dp3 += 1
11 if cur == 5*ugly[dp5]:
12 dp5 += 1
13 index += 1
14 ugly.append(cur)
15 return ugly[-1]
Z 字形变换¶
leetcode 6.
将一个给定字符串根据给定的行数,以从上往下、从左到右进行 Z 字形排列。

1def convert(self, s: str, numRows: int) -> str:
2 if numRows<2:
3 return s
4 res = ["" for _ in range(numRows)]
5 i = 0
6 flag = -1
7 for n in range(len(s)):
8 res[i] += s[n]
9 if i==0 or i==numRows-1:
10 flag = -flag
11 i += flag
12 return "".join(res)
多巧妙!常看!
圆圈中最后剩下的数字¶
剑指 Offer 62.
0,1,,n-1这n个数字排成一个圆圈,从数字0开始,每次从这个圆圈里删除第m个数字。求出这个圆圈里剩下的最后一个数字。
例如,0、1、2、3、4这5个数字组成一个圆圈,从数字0开始每次删除第3个数字,则删除的前4个数字依次是2、0、4、1,因此最后剩下的数字是3。
1def lastRemaining(self, n: int, m: int) -> int:
2 i = 0
3 array = list(range(n))
4 while len(array)>1:
5 i = (i + m - 1) % len(array)
6 array.pop(i)
7 return array[0]
以前很怕这种圆圈的题目….因为不知道循环要怎么做。这道题解法不美妙,纯暴力,纯还原仿真,但是提供了一个很好的思路。
圆圈的题目就用取余 %,判断条件就是 while
整数转罗马数字¶
leetcode 12.
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。

1def intToRoman(self, num: int) -> str:
2 search = [(1000, "M"), (900, "CM"), (500, "D"), (400, "CD"), (100, "C"), (90, "XC"),
3 (50, "L"), (40, "XL"), (10, "X"), (9, "IX"), (5, "V"), (4, "IV"), (1, "I")]
4 res = []
5 for value,symbol in search:
6 count = num//value
7 num = num-count*value
8 if count>0:
9 res.append(symbol*count)
10 return "".join(res)
贪心算法。
其实还有另一种解法,就是按照千位,百位这种的去做。但是情况会复杂很多
联动的下一题:
罗马数字转整数¶
leetcode 13.
1def romanToInt(self, s: str) -> int:
2 Roman2Int = {'I':1,'V':5,'X':10,'L':50,'C':100,'D':500,'M':1000}
3 Int = 0
4 n = len(s)
5
6 for index in range(n - 1):
7 if Roman2Int[s[index]] < Roman2Int[s[index + 1]]:
8 Int -= Roman2Int[s[index]]
9 else:
10 Int += Roman2Int[s[index]]
11
12 return Int + Roman2Int[s[-1]]
也还很巧妙
最长公共前缀¶
leetcode 14.
编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 “”。
1def longestCommonPrefix(self, strs: List[str]) -> str:
2 length = 0
3 if strs==[]:
4 return ""
5 for i in range(len(strs[0])):
6 c = strs[0][i]
7 for j in range(len(strs)):
8 if i>len(strs[j])-1 or strs[j][i]!=c:
9 return strs[0][:length]
10 length += 1
11 return strs[0]
纵向查找。
如果还要优化,可以用二分查找而不是第一个for循环的时候用遍历。 https://leetcode-cn.com/problems/longest-common-prefix/solution/zui-chang-gong-gong-qian-zhui-by-leetcode-solution/
有效的括号¶
1def isValid(self, s: str) -> bool:
2 stack = []
3 left = ["(","{","["]
4 right = {")":"(","}":"{","]":"["}
5 for i in range(len(s)):
6 if s[i] in left:
7 stack.append(s[i])
8 elif s[i] in right:
9 if len(stack)==0 or stack[-1] != right[s[i]]:
10 return False
11 stack.pop()
12 if len(stack)>0:
13 return False
14 return True
先入后出,用栈就好了。注意字典的生成方式,和最后要判断一下栈是否为空
括号生成¶
1def generateParenthesis(self, n: int) -> List[str]:
2 ans = []
3 def dfs(path, inp, oup):
4 if len(path) == n * 2:
5 ans.append(path)
6 return
7 if inp < n:
8 dfs(path + "(", inp + 1, oup)
9 if oup < inp:
10 dfs(path + ")", inp, oup + 1)
11 dfs('', 0, 0)
12 return ans
下一个排列¶
leetcode 31.
1def nextPermutation(self, nums: List[int]) -> None:
2 """
3 Do not return anything, modify nums in-place instead.
4 """
5 if len(nums)<=1:
6 return nums
7 pos1 = -1
8 for i in range(0,len(nums)-1):
9 if nums[i] < nums[i+1]:
10 pos1 = i
11 if pos1 == -1:
12 nums[:] = nums[::-1]
13 return
14 pos2 = -1
15 for j in range(pos1,len(nums)):
16 if nums[j]>nums[pos1]:
17 pos2 = j
18 nums[pos1], nums[pos2] = nums[pos2], nums[pos1]
19 if pos1+1<=len(nums)-1:
20 nums[:] = nums[:pos1+1] + nums[pos1+1:][::-1]
思想来自于 https://leetcode-cn.com/problems/next-permutation/solution/xia-yi-ge-pai-lie-by-powcai/

外观数列¶
1def countAndSay(self, n: int) -> str:
2 def count_num(last_level):
3 count = 1
4 num = last_level[0]
5 res = ""
6 for i in range(1,len(last_level)):
7 if last_level[i]==num:
8 count += 1
9 else:
10 res = res + str(count) + num
11 num = last_level[i]
12 count = 1
13 res = res + str(count) + num
14 return res
15 level = ["1"]
16 if n<=1:
17 return "1"
18 for i in range(1,n):
19 temp = count_num(level[-1])
20 level.append(temp)
21 return level[-1]
跳跃游戏¶
1def canJump(self, nums: List[int]) -> bool:
2 temp_max = 0 + nums[0]
3 for i in range(1,len(nums)):
4 if temp_max<i:
5 return False
6 temp_max = max(temp_max,i+nums[i])
7 if temp_max>=len(nums):
8 return True
9 return True
其实只需要弄明白一件事。只要在遍历的时候,维护一个最远能达到的距离就好了。
假设遍历到了n这个结点,然后n这里最远能走5步,那么从n—n+5都是可以到达的。为什么不怕n-3的时候能走的更远呢?因为已经遍历过了….
请看下一题:
跳跃游戏 II¶
1def jump(self, nums: List[int]) -> int:
2 max_arrive = nums[0]
3 last_max = nums[0]
4 if len(nums)==1:
5 return 0
6 if max_arrive >= len(nums)-1:
7 return 1
8 count = 1
9 for i in range(1,len(nums)):
10 max_arrive = max(max_arrive,i+nums[i])
11 if max_arrive >= len(nums)-1:
12 return count + 1
13 if i==last_max:
14 count += 1
15 last_max = max_arrive
16 return count
特殊情况的讨论稍微有点无聊。这一题比上题多了一步。记录达到上次最远的最少跳跃次数。
从第k步(最远距离)到第k+1步(最远距离)。属于贪心算法的思想
不同路径¶
leetcode 62.

1def uniquePaths(self, m: int, n: int) -> int:
2 # 数学法不香吗?总共要做出 m+n-2次选择,在这些选择里面有m-1次(或者n-1次)要做出向下走的选择,直接用C啊!
3 # C m+n-2 m-1
4 def jiecheng(num):
5 res = 1
6 if num==0:
7 return 1
8 while num>0:
9 res *= num
10 num -= 1
11 return res
12 return int(jiecheng(m+n-2)/(jiecheng(m-1)*jiecheng(m+n-2-m+1)))
简化路径¶
1def simplifyPath(self, path: str) -> str:
2 temp = path.split("/")
3 res = []
4 for sym in temp:
5 if sym=="":
6 continue
7 elif sym==".":
8 continue
9 elif sym=="..":
10 if not res:
11 continue
12 else:
13 res.pop()
14 else:
15 res.append(sym+"/")
16 result = "".join(res)
17 if result.endswith("/"):
18 result = result[:-1]
19 return "/"+result
很愚蠢的题目,直接按照规则一条条来就好了
颜色分类¶
leetcode 75.
1def sortColors(self, nums: List[int]) -> None:
2 """
3 Do not return anything, modify nums in-place instead.
4 """
5 cur, p0, p2 = 0, 0, len(nums)-1
6 if p2==-1:
7 return None
8 while cur <= p2:
9 if nums[cur]==0:
10 nums[cur], nums[p0] = nums[p0] , nums[cur]
11 p0 += 1
12 cur += 1
13 elif nums[cur]==1:
14 cur += 1
15 else:
16 nums[cur], nums[p2] = nums[p2] , nums[cur]
17 p2 -= 1
这道题简直太巧妙了!伪三指针。cur 什么时候要 += 1是精髓! 请再想想!以及while cur <= p2:
???
删除排序数组中的重复项 II¶
leetcode 80.
给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素最多出现两次,返回移除后数组的新长度。
不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成。
1def removeDuplicates(self, nums: List[int]) -> int:
2 if not nums:
3 return 0
4 i = 1
5 dup = 1
6 temp = nums[0]
7 # for i in range(1,len(nums)):
8 while i <= len(nums)-1:
9 if nums[i]==temp:
10 if dup==1:
11 dup += 1
12 i += 1
13 else:
14 del(nums[i])
15 else:
16 temp = nums[i]
17 dup = 1
18 i += 1
19 return len(nums)
编辑距离¶
leetcode 72
1def minDistance(self, word1: str, word2: str) -> int:
2 if not word1:
3 return len(word2)
4 if not word2:
5 return len(word1)
6 len1 = len(word1)
7 len2 = len(word2)
8 dp = [[0] * (len2 + 1) for _ in range(len1 + 1)]
9 for i in range(len2 + 1):
10 dp[0][i] = i
11 for i in range(len1 + 1):
12 dp[i][0] = i
13 for i in range(1, len1 + 1):
14 for j in range(1, len2 + 1):
15 if word1[i - 1] == word2[j - 1]:
16 dp[i][j] = dp[i - 1][j - 1]
17 else:
18 dp[i][j] = 1 + min(dp[i - 1][j - 1], dp[i][j - 1], dp[i - 1][j])
19 return dp[-1][-1]

这里 dp = [[0] * (len2 + 1) for _ in range(len1 + 1)] 和 for i in range(len2 + 1):dp[0][i] = i 这几行要搞清楚到底是 len1还是len2!!!!
对“dp[i-1][j-1] 表示替换操作,dp[i-1][j] 表示删除操作,dp[i][j-1] 表示插入操作。”的补充理解:
follow up:
面试 cresta时候的题目:
在此基础上,如果 Transposition: cat –> act 也算作1呢?
1def edit_distance(word1, word2):
2 if not word1:
3 return len(word2)
4 if not word2:
5 return len(word1)
6 len1, len2 = len(word1), len(word2)
7 # initial dp matrix
8 dp = [[0] * (len2 + 1) for _ in range(len1 + 1)]
9 for i in range(len1 + 1):
10 dp[i][0] = i
11 for i in range(len2 + 1):
12 dp[0][i] = i
13 # calculate distance
14 for i in range(1, len1 + 1):
15 for j in range(1, len2 + 1):
16 if word1[i - 1] == word2[j - 1]:
17 dp[i][j] = dp[i - 1][j - 1]
18 else:
19 dp[i][j] = 1 + min(dp[i - 1][j], dp[i][j - 1], dp[i - 1][j - 1])
20 if i >= 2 and j >= 2 and word1[i - 2] == word2[j - 1] and word1[i - 1] == word2[j - 2]:
21 dp[i][j] = min(dp[i][j], dp[i - 2][j - 2] + 1)
22 return dp[-1][-1]
备注
特别注意,第21行这里,必须是 dp[i][j] = min(dp[i][j], dp[i - 2][j - 2] + 1)。因为会出现 dp[i][j] < dp[i - 2][j - 2] + 1 的时候。举例:
word1 = “aba” word2 = “ab”
两个字符串的删除操作¶
leetcode 583.
给定两个单词 word1 和 word2 ,返回使得 word1 和 word2 相同所需的最小步数。
每步 可以删除任意一个字符串中的一个字符。
1def minDistance(self, word1: str, word2: str) -> int:
2 dp = [[0] * (len(word1) + 1) for _ in range(len(word2) + 1)]
3 for i in range(len(word2) + 1):
4 dp[i][0] = i
5 for j in range(len(word1) + 1):
6 dp[0][j] = j
7
8 for i in range(1, len(word2) + 1):
9 for j in range(1, len(word1) + 1):
10 if word1[j - 1] == word2[i - 1]:
11 dp[i][j] = dp[i - 1][j - 1]
12 else:
13 dp[i][j] = min(dp[i][j - 1], dp[i - 1][j]) + 1
14 return dp[-1][-1]
基本类似编辑距离,只不过没有上面的替换功能而已。
重要
dp = [[0] * (len(word1) + 1) for _ in range(len(word2) + 1)] 这个地方,第二个len是需要加上range的!!老忘记
并且,len(word1) + 1 的 +1 不能忘记。总之就是这句话别写错
下面这道题和编辑距离的解题方法很像。
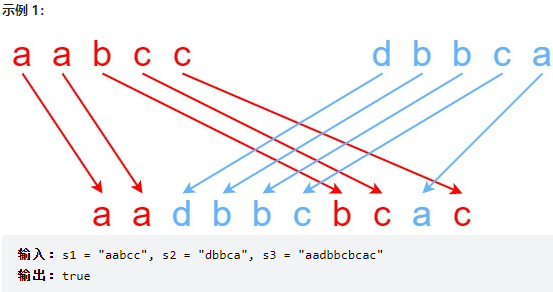
交错字符串¶
leetcode 97.
给定三个字符串 s1、s2、s3,请你帮忙验证 s3 是否是由 s1 和 s2 交错 组成的。
两个字符串 s 和 t 交错 的定义与过程如下,其中每个字符串都会被分割成若干 非空 子字符串:
|n - m| <= 1
1def isInterleave(self, s1: str, s2: str, s3: str) -> bool:
2 lens1 = len(s1)
3 lens2 = len(s2)
4 lens3 = len(s3)
5 if lens1 + lens2 != lens3:
6 return False
7 if lens1 == 0 or lens2 == 0:
8 return s1 + s2 == s3
9
10 dp = [[False] * (lens1 + 1) for _ in range(lens2 + 1)]
11 dp[0][0] = True
12 for i in range(1, lens2 + 1):
13 dp[i][0] = dp[i - 1][0] and s2[i - 1] == s3[i - 1]
14 for j in range(1, lens1 + 1):
15 dp[0][j] = dp[0][j - 1] and s1[j - 1] == s3[j - 1]
16
17 for i in range(1, lens2 + 1):
18 for j in range(1, lens1 + 1):
19 dp[i][j] = (dp[i - 1][j] and s2[i - 1] == s3[i + j - 1]) or (dp[i][j - 1] and s1[j - 1] == s3[i + j - 1])
20 return dp[-1][-1]
解法:
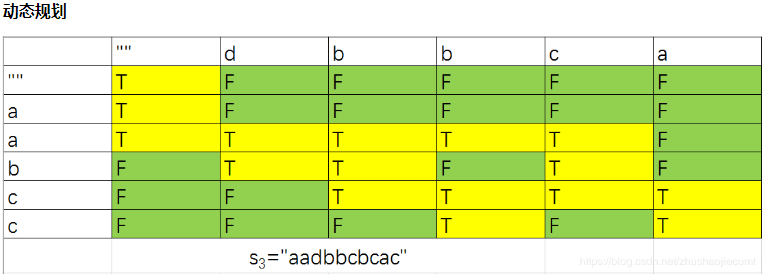

想法:
- 其实不需要管题目中的什么s1连着三四个字母拼下去,然后s2连着两个字母拼下去。其实分解成小问题,就是能不能 s1[i−1]==s3[i−1]
- 以后涉及这种两个字符串一个个去比较,又需要用到动态规划的题目,就把上面那个表格画出来。横纵坐标分别代表什么要搞清楚
不同的子序列¶
leetcode 115.
给你两个字符串 s 和 t ,统计并返回在 s 的 子序列 中 t 出现的个数。
题目数据保证答案符合 32 位带符号整数范围。
1def numDistinct(self, s: str, t: str) -> int:
2 m, n = len(t), len(s)
3 dp = [[0] * (n + 1) for _ in range(m + 1)]
4 for j in range(n + 1):
5 dp[0][j] = 1
6 for i in range(1, m + 1):
7 for j in range(1, n + 1):
8 if t[i - 1] != s[j - 1]:
9 dp[i][j] = dp[i][j - 1]
10 else:
11 dp[i][j] = dp[i - 1][j - 1] + dp[i][j - 1]
12 return dp[-1][-1]
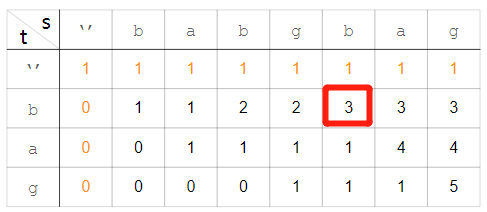

一般这种题目都是有套路的,第一行和第一列都是空字符串,做好初始化
在dp的第一行和第一列,想清楚谁是1谁是0,之后遍历的时候就从第二行和第二列开始了!
首先,在t[i-1] 不等于 s[j-1] 时,这个很好理解,那就是dp[i][j] = dp[i][j - 1],相当于没用上这个新出来的字符串
在t[i-1] 等于 s[j-1] 时。这个理解稍微复杂一点。如上面截图红框处的这个位置。如果用上这个新加的b来匹配需要的b,那么相当于不用之前的内容,为左上角的1 如果不用这个新加的b,那和两个字符不匹配(上面那个一样),为左边的2.所以最后是左上角叠加左边
最长公共子序列¶
leetcode 1143.
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
例如,”ace” 是 “abcde” 的子序列,但 “aec” 不是 “abcde” 的子序列。 两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
1def longestCommonSubsequence(self, text1: str, text2: str) -> int:
2 len1 = len(text1)
3 len2 = len(text2)
4 dp = [[0] * (len2 + 1) for _ in range(len1 + 1)]
5 for i in range(1, len1 + 1):
6 for j in range(1, len2 + 1):
7 if text1[i - 1] == text2[j - 1]:
8 dp[i][j] = dp[i - 1][j - 1] + 1
9 else:
10 dp[i][j] = max(dp[i][j - 1], dp[i - 1][j])
11 return dp[-1][-1]

通配符匹配¶
leetcode 44.
给你一个输入字符串 (s) 和一个字符模式 (p) ,请你实现一个支持 ‘?’ 和 ‘*’ 匹配规则的通配符匹配:
判定匹配成功的充要条件是:字符模式必须能够 完全匹配 输入字符串(而不是部分匹配)。
1def isMatch(self, s: str, p: str) -> bool:
2 lens = len(s)
3 lenp = len(p)
4 dp = [[False] * (lenp + 1) for _ in range(lens + 1)]
5 dp[0][0] = True
6 flag = True
7 for j in range(1, lenp + 1):
8 if p[j - 1] == "*" and flag:
9 dp[0][j] = True
10 elif p[j - 1] != "*":
11 flag = False
12
13 for i in range(1, lens + 1):
14 for j in range(1, lenp + 1):
15 if p[j - 1] == s[i - 1] or p[j - 1] == "?":
16 dp[i][j] = dp[i - 1][j - 1]
17 elif p[j - 1] == "*":
18 if dp[i][j - 1] or dp[i - 1][j]:
19 dp[i][j] = True
20 return dp[-1][-1]
单词接龙¶
leetcode 127.
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列 beginWord -> s1 -> s2 -> … -> sk:
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,返回 从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0 。
1def ladderLength(self, beginWord: str, endWord: str, wordList: List[str]) -> int:
2 wordset = set(wordList)
3 if endWord not in wordset:
4 return 0
5 queue = [beginWord]
6 if beginWord in wordset:
7 wordset.remove(beginWord)
8 step = 1
9 while queue:
10 store = []
11 for word in queue:
12 for i in range(len(word)):
13 # temp = word
14 for j in range(26):
15 temp = word[:i] + chr(j + ord("a")) + word[i + 1:]
16 if temp == endWord:
17 return step + 1
18 if temp in wordset:
19 wordset.remove(temp)
20 store.append(temp)
21 step += 1
22 queue = store
23 return 0
第二种的复杂度是O(N * len Word)。而且可以用BFS来进行优化
bfs:从begin开始,找到所有能替换一个字母就达到的单词,存在queue里面。一层层的来找。最短路径是需要用bfs而不是dfs的
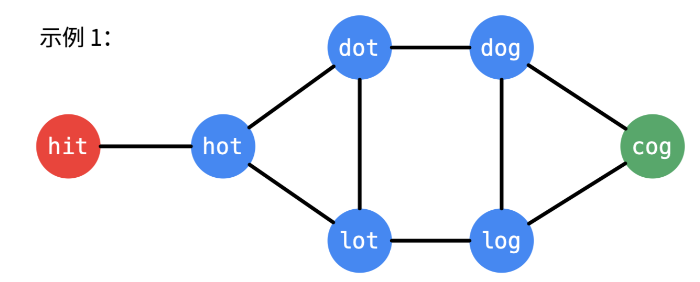
最长上升子序列¶
1def lengthOfLIS(self, nums: List[int]) -> int:
2 temp = [1]*len(nums)
3 if len(nums)<=1:
4 return len(nums)
5 for i in range(1,len(nums)):
6 for j in range(i):
7 if nums[i]>nums[j]:
8 temp[i] = max(temp[i],temp[j]+1)
9 return max(temp)

还有一种解法:
1def lengthOfLIS(self, nums: List[int]) -> int:
2 sub = [nums[0]]
3 for num in nums[1:]:
4 if num > sub[-1]:
5 sub.append(num)
6 else:
7 i = bisect_left(sub, num)
8 sub[i] = num
9 return len(sub)
这里bisect_left 的作用是,如果想插入一个数到list中,找到他的位置
之前有种维护一个stack的做法,是需要pop或者push的。 0,1,0,3 这个例子就不对了. 因为不要求相邻,所以不需要pop干净,这里的替换就行
打家劫舍¶
如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。 | 给定一个代表每个房屋存放金额的非负整数数组,计算你不触动警报装置的情况下,一夜之内能够偷窃到的最高金额。
1def rob(self, nums: List[int]) -> int:
2 if len(nums)==0:
3 return 0
4 if len(nums)<=2:
5 return max(nums)
6 temp = [0]*len(nums)
7 temp[0], temp[1] = nums[0], max(nums[0],nums[1])
8 for i in range(2,len(nums)):
9 temp[i] = max(temp[i-1],temp[i-2]+nums[i])
10 return max(temp)
思考: 为什么这样可以避免我之前设想的 7,2,3,9 取最前最后的问题呢? 因为取到2的时候就已经避免这个问题了,因为2比7小,所以根本就没用取2
请看下一题
打家劫舍 II¶
同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。 给定一个代表每个房屋存放金额的非负整数数组,计算你在不触动警报装置的情况下,能够偷窃到的最高金额。
1def rob(self, nums: List[int]) -> int:
2 def steal(array):
3 temp = [0]*len(array)
4 temp[0], temp[1] = array[0], max(array[0],array[1])
5 for i in range(2,len(array)):
6 temp[i] = max(temp[i-1],temp[i-2]+array[i])
7 return max(temp)
8 if len(nums)==0:
9 return 0
10 if len(nums)<=2:
11 return max(nums)
12 return max(steal(nums[1:]),steal(nums[:-1]))
把环拆成两个数组。不取第一个和不取最后一个
打家劫舍 III¶
一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果两个直接相连的房子在同一天晚上被打劫,房屋将自动报警。 计算在不触动警报的情况下,小偷一晚能够盗取的最高金额。
1def rob(self, root: TreeNode) -> int:
2 def helper(root):
3 if not root:
4 return 0, 0
5 left = helper(root.left)
6 right = helper(root.right)
7 v1 = root.val + left[1] + right[1]
8 v2 = max(left) + max(right)
9 return v1, v2
10 return max(helper(root))
01背包问题¶
假设有一组物品,w的list是他们的weight,v的list是他们的value,tar是背包的重量。求能带上的最大价值
1w = [2,2,6,5,4]
2v = [6,3,5,4,6]
3tar = 10
4
5# i 是是否用物品
6# j 是背包的重量
7temp = [[0 for _ in range(tar+1)] for _ in range(len(w)+1)]
8for i in range(1,len(w)+1):
9 for j in range(1,tar+1):
10 if j < w[i-1]:
11 temp[i][j] = temp[i-1][j]
12 else:
13 temp[i][j] = max(temp[i-1][j-w[i-1]]+v[i-1],temp[i-1][j])
请看下一题
分割等和子集¶
1def canPartition(self, nums: List[int]) -> bool:
2 if sum(nums)%2 != 0:
3 return False
4 tar = sum(nums)//2
5 store = [[False for _ in range(tar+1)] for _ in range(len(nums)+1)]
6 for i in range(len(nums)+1):
7 store[i][0] = True
8 for i in range(1,len(nums)+1):
9 for j in range(1,tar+1):
10 store[i][j] = store[i-1][j]
11 if j >= nums[i-1]:
12 store[i][j] = store[i-1][j] or store[i-1][j-nums[i-1]]
13 return store[-1][-1]
目标和¶
leetcode 494. 给定一个非负整数数组,a1, a2, …, an, 和一个目标数,S。现在你有两个符号 + 和 -。对于数组中的任意一个整数,你都可以从 + 或 -中选择一个符号添加在前面。
返回可以使最终数组和为目标数 S 的所有添加符号的方法数。
1def findTargetSumWays(self, nums: List[int], S: int) -> int:
2 P = (sum(nums) + S) // 2
3 if (sum(nums) + S) % 2 != 0 or sum(nums) < S:
4 return 0
5 count0 = 0
6 while 0 in nums:
7 nums.remove(0)
8 count0 += 1
9 dp = [[0 for _ in range(P+1)] for _ in range(len(nums)+1)]
10 for i in range(len(nums)+1):
11 dp[i][0] = 1
12 for i in range(1, len(nums) + 1):
13 for j in range(1, P + 1):
14 dp[i][j] = dp[i - 1][j]
15 if dp[i-1][j - nums[i-1]] != 0:
16 dp[i][j] += dp[i-1][j-nums[i-1]]
17 return dp[-1][-1]*2**(count0)
这个也是模仿的01背包的解法。P = (sum(nums) + S) // 2 这个思路十分的巧妙。

count0这里是会有一些0的情况,0取不取所以乘二
然后这种初始化的方式不可以: dp = [[[1] + [0] * P] * (len(nums) + 1)]
这样的话,* (len(nums) + 1)]部分会变成浅拷贝的复制,下一行改了之后上一行也会变。虽然 [0] * P 这里没问题
https://leetcode-cn.com/problems/target-sum/solution/python-dfs-xiang-jie-by-jimmy00745/ 题解里面这种一维的就能解决了,解法也放上来
1def findTargetSumWays(self, nums: List[int], S: int) -> int:
2 if sum(nums) < S or (sum(nums) + S) % 2 == 1: return 0
3 P = (sum(nums) + S) // 2
4 dp = [1] + [0 for _ in range(P)]
5 for num in nums:
6 for j in range(P,num-1,-1):dp[j] += dp[j - num]
7 return dp[P]
零钱兑换¶
1def coinChange(self, coins: List[int], amount: int) -> int:
2 temp = [float('inf') for _ in range(amount + 1)]
3 temp[0] = 0
4 for i in range(1, amount + 1):
5 for j in range(len(coins)):
6 if coins[j] > i:
7 continue
8 else:
9 temp[i] = min(temp[i], temp[i - coins[j]] + 1)
10 if temp[-1]==float('inf'):
11 return -1
12 else:
13 return temp[-1]
最长有效括号¶
1def longestValidParentheses(self, s: str) -> int:
2 res = 0
3 stack = [-1]
4 for i,v in enumerate(s):
5 if s[i]=="(":
6 stack.append(i)
7 else:
8 if len(stack)>1:
9 stack.pop()
10 res = max(res, i-stack[-1])
11 else:
12 stack = [i]
13 return res
这个题的思路和最开始想的不太一样。因为()括号一左一右是两个,最开始想的是每次遇到右括号就长度加2.但是会遇到种种问题。
所以这里记录一下上一次的非法右括号。 所以初始化的时候是stack = [-1] 。 stack打空了之后再遇到右括号就当成非法右括号,stack = [i]
所以从 i-j+1 变成了 i- j的上一个
和为 K 的子数组¶
leetcode 560.
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的连续子数组的个数 。
子数组是数组中元素的连续非空序列。
1def subarraySum(self, nums: List[int], k: int) -> int:
2 ans = 0
3 store = {0:1}
4 temp = 0
5 for num in nums:
6 temp += num
7 if temp - k in store:
8 ans += store[temp - k]
9 store[temp] = store.get(temp, 0) + 1
10 return ans
11 # 这道题看了解析的。前缀和+类似2sum的解法真牛啊!
49. Group Anagrams¶
leetcode 49.

1def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
2 store = defaultdict(list)
3 for word in strs:
4 count = [0] * 26
5 for cha in word:
6 count[ord(cha) - ord("a")] += 1
7 # str_count = ""
8 # for i in range(26):
9 # if count[i] != 0:
10 # str_count += chr(i + ord("a")) + str(count[i])
11 store[tuple(count)].append(word) # 直接使用tuple
12 return list(store.values())
list不能当字典里的key的时候,使用tuple当字典的key
128. Longest Consecutive Sequence¶
leetcode 128.
Given an unsorted array of integers nums, return the length of the longest consecutive elements sequence.
You must write an algorithm that runs in O(n) time.
1def longestConsecutive(self, nums: List[int]) -> int:
2 max_length = 0
3 temp = {}
4 for num in nums:
5 if num not in temp:
6 left = temp.get(num - 1, 0)
7 right = temp.get(num + 1, 0)
8 length = left + right + 1
9 max_length = max(max_length, length)
10
11 temp[num - left] = length
12 temp[num + right] = length
13 temp[num] = length # 这里也要更新一下,免得有重复数字
14 return max_length
思路是:利用了必须要求连续整数这一特点。当来一个新数时,看看他的左边-1 和右边+1.获得左右的翅膀长度。计算整个的长度,然后要更新左边和右边代表的长度。同时也要更新自己,以免有重复数字,进行重复计算 为什么只需要更新左右端点呢?因为这里判断新数的时候,只会从他的左边-1 和右边+1.获得左右的翅膀长度,不需要从中间找了
这样写是不行的:
1def longestConsecutive(self, nums: List[int]) -> int:
2 store = defaultdict(int)
3 ans = 0
4 for num in nums:
5 if num not in store:
6 left = store[num - 1]
7 right = store[num + 1]
8 length = right + left + 1
9 store[num - left] = length
10 store[num + right] = length
11 store[num] = length
12 ans = max(ans, length)
13 return ans
原因是,这里使用了defaultdict(int),那么在 left = store[num - 1]的时候,尽管之前left没出现过,但是也会被生成一个0存在字典里面。所以下次要判断left的时候,会被if num not in store拒绝
遍历(Traversal)¶
125. Valid Palindrome¶
leetcode 125.
A phrase is a palindrome if, after converting all uppercase letters into lowercase letters and removing all non-alphanumeric characters, it reads the same forward and backward. Alphanumeric characters include letters and numbers.
Given a string s, return true if it is a palindrome, or false otherwise.
1def isPalindrome(self, s: str) -> bool:
2 i, j = 0, len(s) - 1
3 while i <= j:
4 if not s[i].isalnum():
5 i += 1
6 elif not s[j].isalnum():
7 j -= 1
8 elif s[i].lower() == s[j].lower():
9 # 这里要特别注意,为什么这里可以直接用s[i].lower() != s[j].lower() 而不用担心数字
10 # 是因为这里s[i] s[j] 永远都是字符串。哪怕s[i]是9,那也是string 9 而不是int 9
11 i += 1
12 j -= 1
13 else:
14 return False
15 return True
最长回文子串¶
leetcode 5.
给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。:
1def longestPalindrome(self, s: str) -> str:
2 def check(string,index):
3 i=0
4 while index-i>=0 and index+i<=len(string)-1:
5 if string[index-i]==string[index+i]:
6 i+=1
7 else:
8 return i-1
9 return i-1
10 res = []
11 if len(s)<=1:
12 return s
13 for i in range(len(s)):
14 temp = check(s,i)
15 if 2*temp +1>len(res):
16 res = s[i-temp:i]+s[i:i+temp+1]
17 temp = check(s[:i]+'#'+s[i:],i)
18 if 2*temp +1>len(res):
19 res = s[i-temp:i]+s[i:i+temp]
20 return res
盛最多水的容器¶
leetcode 11.
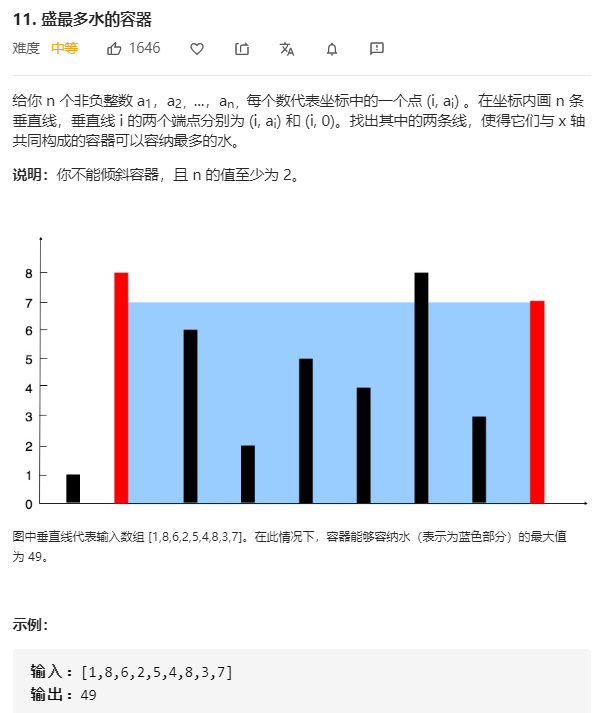
1def maxArea(self, height: List[int]) -> int:
2 if len(height)<=1:
3 return 0
4 l, r = 0, len(height)-1
5 res = 0
6 while l<r:
7 res = max(res,(r-l)*min(height[l],height[r]))
8 if height[l]<=height[r]:
9 l += 1
10 else:
11 r -= 1
12 return res
典型的双指针
三数之和 & 最接近的三数之和¶
leetcode 15. 和 leetcode 16
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有满足条件且不重复的三元组。
给定一个包括 n 个整数的数组 nums 和 一个目标值 target。找出 nums 中的三个整数,使得它们的和与 target 最接近。返回这三个数的和。假定每组输入只存在唯一答案。
(注意,都是无序的)
都是先排序,再做双指针。第一个for循环是遍历,然后在他后面的元素里面,左指针是左边第一个,右指针是最右边。
2340 - Minimum Adjacent Swaps to Make a Valid Array¶
You are given a 0-indexed integer array nums.
Swaps of adjacent elements are able to be performed on nums.
1def minimumSwaps(nums):
2 # 找到最小元素及其索引
3 min_val = min(nums)
4 min_index = nums.index(min_val)
5
6 # 找到最大元素及其最后一个索引(从右侧开始)
7 max_val = max(nums)
8 max_index = len(nums) - 1 - nums[::-1].index(max_val)
9
10 # 如果最小元素已经在最左边且最大元素已经在最右边
11 if min_index == 0 and max_index == len(nums) - 1:
12 return 0
13
14 # 计算最小的交换次数
15 if min_index < max_index:
16 return min_index + (len(nums) - 1 - max_index)
17 else:
18 return min_index + (len(nums) - 1 - max_index) - 1
amazon面经题目
1031. Maximum Sum of Two Non-Overlapping Subarrays(list前缀和)¶
- Maximum Sum of Two Non-Overlapping Subarrays
Given an integer array nums and two integers firstLen and secondLen, return the maximum sum of elements in two non-overlapping subarrays with lengths firstLen and secondLen.
The array with length firstLen could occur before or after the array with length secondLen, but they have to be non-overlapping.
A subarray is a contiguous part of an array.
1def maxSumTwoNoOverlap(self, nums: List[int], firstLen: int, secondLen: int) -> int:
2 pre_sum = []
3 temp = 0
4 for i in range(len(nums)):
5 temp += nums[i]
6 pre_sum.append(temp)
7 def help(firstLen, secondLen, symbol):
8 if symbol == "reverse":
9 firstLen, secondLen = secondLen, firstLen
10 max_ans = sum(nums[:firstLen + secondLen])
11 max_left = sum(nums[:firstLen])
12 for j in range(firstLen + secondLen, len(nums)):
13 # j=3, j - secondLen=1, j - secondLen - firstLen=0
14 max_left = max(max_left, pre_sum[j - secondLen] - pre_sum[j - secondLen - firstLen])
15 max_ans = max(max_ans, max_left + pre_sum[j] - pre_sum[j - secondLen])
16 return max_ans
17 ans1 = help(firstLen, secondLen, " ")
18 ans2 = help(firstLen, secondLen, "reverse")
19 return max(ans1, ans2)
这个参考了解析。用list中的前缀和
如果在写代码的时候搞不清index,就像我这样# j=3, j - secondLen=1, j - secondLen - firstLen=0 写下来。然后带入数值去看 对不对
1124. Longest Well-Performing Interval¶
We are given hours, a list of the number of hours worked per day for a given employee.
A day is considered to be a tiring day if and only if the number of hours worked is (strictly) greater than 8.
A well-performing interval is an interval of days for which the number of tiring days is strictly larger than the number of non-tiring days.
Return the length of the longest well-performing interval.
1def longestWPI(self, hours: List[int]) -> int:
2 cnt = 0
3 ans = 0
4 store = dict()
5 for i in range(len(hours)):
6 if hours[i] > 8:
7 cnt += 1
8 else:
9 cnt -= 1
10 if cnt not in store:
11 store[cnt] = i
12 if cnt > 0:
13 ans = max(ans, i + 1)
14 if cnt - 1 in store:
15 ans = max(ans, i - store[cnt - 1])
16 return ans
也是前缀和:
if cnt > 0:
ans = max(ans, i + 1)
这一步很重要,不然处理不了[9,9,9]的情况
搓哥面试题哈哈哈
135. Candy¶
There are n children standing in a line. Each child is assigned a rating value given in the integer array ratings.
You are giving candies to these children subjected to the following requirements:
1def candy(self, ratings: List[int]) -> int:
2 def allocate(ratings):
3 ans = [1] * len(ratings)
4 for i in range(1, len(ratings)):
5 if ratings[i] > ratings[i - 1]:
6 ans[i] = ans[i - 1] + 1
7 return ans
8 left = allocate(ratings)
9 right = allocate(ratings[::-1])[::-1]
10 for i in range(len(ratings)):
11 left[i] = max(left[i], right[i])
12 return sum(left)

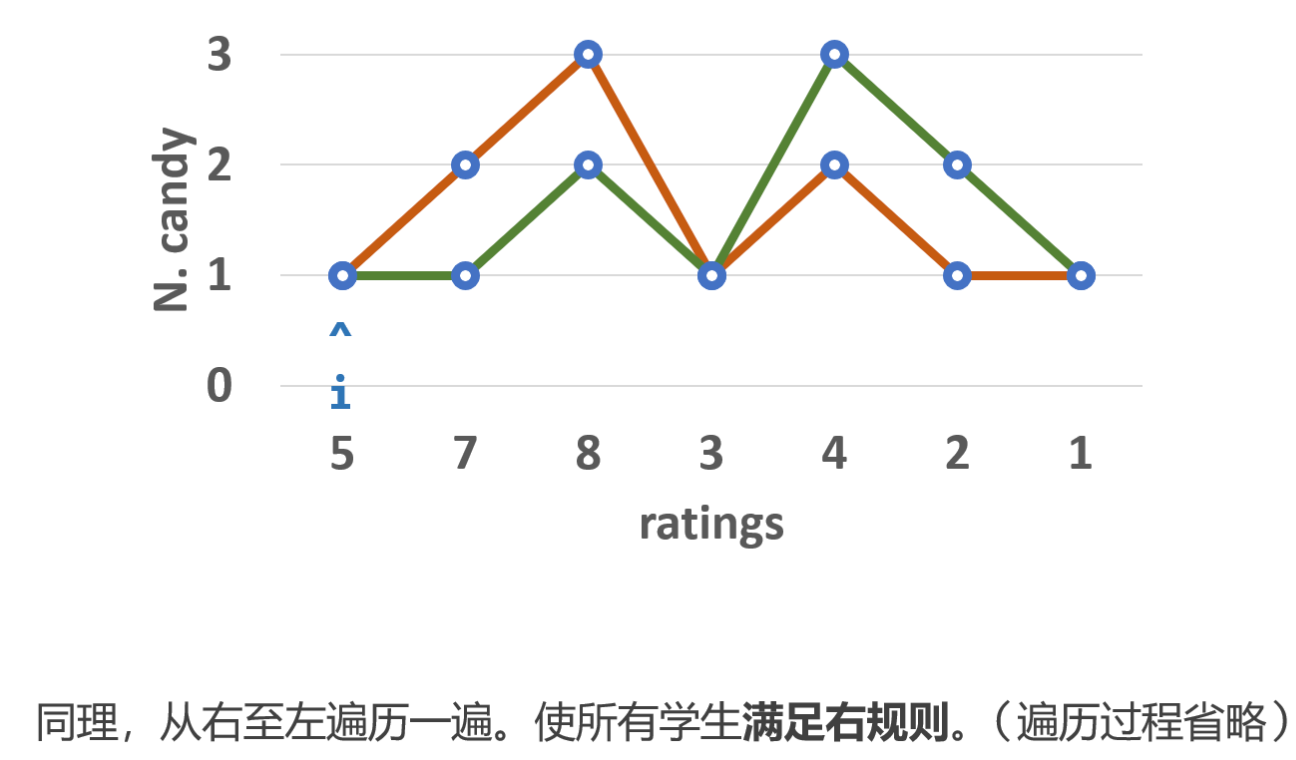
下面评论区有个老哥写的,为什么取最大值是正确的思考:
很多人说这个问题显而易见,不值得讨论,但我相信还是有人像我一样不理解,在这里说一下我的想法
我疑惑的问题不是取最大值为啥是最优解,而是取最大值后为啥不影响某一规则的成立。
我们取序列中的任意两点,A B
区间问题¶
合并区间¶
1def merge(self, intervals: List[List[int]]) -> List[List[int]]:
2 if len(intervals)<=1:
3 return intervals
4 intervals.sort()
5 res = [intervals[0]]
6 for i in range(1,len(intervals)):
7 if intervals[i][0]>res[-1][-1]:
8 res.append(intervals[i])
9 else:
10 res[-1][-1] = max(res[-1][-1],intervals[i][-1])
11 return res
或者:
1def merge(self, intervals: List[List[int]]) -> List[List[int]]:
2 intvs = sorted(intervals, key = lambda x: x[0])
3 ans = []
4 start, end = intvs[0][0], intvs[0][1]
5 for i in range(1, len(intvs)):
6 s, e = intvs[i][0], intvs[i][1]
7 if s > end:
8 ans.append([start, end])
9 start, end = s, e
10 else:
11 end = max(end, e)
12 ans.append([start, end])
13 return ans
只要明白一件事就好了,先排序(sort以后先按第一个排序,再按第二个排序)。排序后的列表,如果说新判断的区间,左边的区间都比上一个的右区间大,那么一定不重合
请看下一题:
插入区间¶
leetcode 57.
1def insert(self, intervals: List[List[int]], newInterval: List[int]) -> List[List[int]]:
2 i= 0
3 while i<len(intervals) and intervals[i][1]<newInterval[0]:
4 i += 1
5 if i<=len(intervals)-1: # 防止i越界
6 newInterval[0] = min(newInterval[0],intervals[i][0])
7 j = i
8 while j<len(intervals) and intervals[j][0]<=newInterval[1]:
9 newInterval[1] = max(newInterval[1],intervals[j][1])
10 j+=1
11 del(intervals[i:j])
12 intervals.insert(i,newInterval)
13 return intervals
请再次深思,为什么i那里是intervals[i][1]<newInterval[0],而j那里是intervals[j][0]<=newInterval[1]
同时,del的话是可以越界的。比如the_list只有3长度,可以del(the_list[7:9])
1def insert(self, intervals: List[List[int]], newInterval: List[int]) -> List[List[int]]:
2 if not intervals:
3 return [newInterval]
4 start, end = newInterval[0], newInterval[1]
5 if start > intervals[-1][1]:
6 return intervals + [newInterval]
7 if end < intervals[0][0]:
8 return [newInterval] + intervals
9 length = len(intervals)
10 ans = []
11 flag = 0
12 for i in range(length):
13 s, e = intervals[i][0], intervals[i][1]
14 if e < start:
15 # not in process
16 ans.append([s, e])
17 elif s > end:
18 # finish
19 # record the temp
20 if flag == 1:
21 ans.append([start, end])
22 flag = 2
23 elif flag == 0:
24 ans.append([start, end])
25 flag = 2
26 ans.append([s, e])
27 else:
28 start = min(s, start)
29 end = max(e, end)
30 flag = 1
31 if flag == 1:
32 ans.append([start, end])
33 return ans
会议室¶
1def merge(intervals):
2 if len(intervals)==1:
3 return True
4 intervals.sort()
5 for i in range(1,len(intervals)):
6 if intervals[i][0]>=intervals[i-1][1]:
7 return False
8 return True
仿照leetcode56 写的。 没在leetcode上测过….因为这是锁定题目,要收费…
lintcode上倒是有一道同名题目, 数据结构略有点小坑
920 · 会议室
给定一系列的会议时间间隔,包括起始和结束时间[[s1,e1],[s2,e2],…(si < ei),确定一个人是否可以参加所有会议。 (0,8),(8,10)在8这一时刻不冲突
1"""
2Definition of Interval:
3class Interval(object):
4 def __init__(self, start, end):
5 self.start = start
6 self.end = end
7"""
8class Solution:
9 """
10 @param intervals: an array of meeting time intervals
11 @return: if a person could attend all meetings
12 """
13 def can_attend_meetings(self, intervals: List[Interval]) -> bool:
14 end_time = -1
15 for interval in sorted(intervals, key = lambda interval: interval.start):
16 if interval.start < end_time:
17 return False
18 end_time = interval.end
19 return True
这里的Interval是interval.start和interval.end
疑惑
我发现这里在排序的时候,下面这两种方式都行??????为啥呢 intvs = sorted(intervals, key = lambda x:x.end) intvs = sorted(intervals, key = lambda x:x.start)
请看下一题
会议室II¶
1def min_meeting_rooms(self, intervals: List[Interval]) -> int:
2 start_times = sorted(Interval.start for Interval in intervals)
3 end_times = sorted(Interval.end for Interval in intervals)
4 rooms = 0
5 length = len(intervals)
6 i, j = 0, 0
7 while i < length:
8 if start_times[i] >= end_times[j]:
9 i += 1
10 j += 1
11 else:
12 # start_times[i] < end_times[j]
13 rooms += 1
14 i += 1
15 return rooms
这种解析的思路是这样的: | 假设三段会议安排是: | [0, 10] | [1, 5] [6, 9]
当我们遇到“会议结束”事件时,意味着一些较早开始的会议已经结束。我们并不关心到底是哪个会议结束。我们所需要的只是 一些 会议结束,从而提供一个空房间。
这里有点像从开始到结束遍历时间,然后看这个时间点上到底需要几个会议室。那么这里遍历时间是以会议开始为标志的,就是这个会议开始的时候,到底需要几个会议室
或者这么看是不是更直观:
1def min_meeting_rooms(self, intervals: List[Interval]) -> int:
2 rooms = []
3 for x in intervals:
4 rooms.append([x.start, 1])
5 rooms.append([x.end, -1])
6 rooms.sort()
7 cnt = 0
8 tmp = 0
9 for _, delta in rooms:
10 tmp += delta
11 cnt = max(cnt, tmp)
12 return cnt
直接就是 按照时间线扫描过去 开会议室就+1 结束一个就-1。推荐这种思路写法
还有一种方法:
1import heapq
2def minMeetingRooms(self, intervals):
3 intervals.sort(key = lambda x: x.start)
4 heap = []
5 for interval in intervals:
6 if heap and interval.start >= heap[0]:
7 heapq.heapreplace(heap, interval.end)
8 else:
9 heapq.heappush(heap, interval.end)
10 return len(heap)
这个需要import heapq 堆
无重叠区间¶
leetcode 435.
给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。
注意: 可以认为区间的终点总是大于它的起点。 区间 [1,2] 和 [2,3] 的边界相互“接触”,但没有相互重叠。 示例 1: 输入: [ [1,2], [2,3], [3,4], [1,3] ] 输出: 1 解释: 移除 [1,3] 后,剩下的区间没有重叠。
1def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:
2 if len(intervals)<=1:
3 return 0
4 intervals = sorted(intervals, key = lambda x: x[1])
5 temp = intervals[0]
6 count = 0
7 for i in range(1,len(intervals)):
8 if intervals[i][0] < temp[1]:
9 count += 1
10 else:
11 temp = intervals[i]
12 return count
这里是按照结束时间排序。因为这里的重要性是按照结束时间来定的:选择区间组成无重叠区间,为使区间数量尽可能多, 被选区间的右端点应尽可能小,留给后面的区间的空间就大,那么后面能够选择的区间个数也就大。 贪心思想,其实也有点像是动态规划,到目前为止,我能安排多少个会议。是以截止时间来衡量的。
可以自己拿示例试试。排完序后是[[1, 11], [2, 12], [11, 22], [1, 100]]。那么很明显,第二个[2, 12]是没有用的
如果是以左端点来排序的话,那么情况会复杂一些。需要在有重叠的时候 end选择右端点最小的那个(相当于是丢弃了右端点大的那个)
# 这样是错的
inters = sorted(sorted(intervals, key = lambda x: x[1]), key = lambda x: x[0])
这样肯定不行。这样的意思其实是我最开始的意思,先排左边,左边相同的情况下右边小的为准。例子:[[-100, 100], [-90, -80], [-20, 0], [1, 10]] 其实是需要移除第一个
1def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:
2 cnt = 0
3 intervals.sort()
4 end = intervals[0][1]
5 length = len(intervals)
6 for i in range(1, length):
7 if intervals[i][0] < end:
8 cnt += 1
9 end = min(end, intervals[i][1])
10 else:
11 end = intervals[i][1]
12 return cnt
用最少数量的箭引爆气球¶
开始坐标总是小于结束坐标。平面内最多存在104个气球。 一支弓箭可以沿着x轴从不同点完全垂直地射出。在坐标x处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被引爆。 可以射出的弓箭的数量没有限制。 弓箭一旦被射出之后,可以无限地前进。我们想找到使得所有气球全部被引爆,所需的弓箭的最小数量。
1def findMinArrowShots(self, points: List[List[int]]) -> int:
2 points.sort(key = lambda x: x[1])
3 if len(points) <= 1:
4 return len(points)
5 count = 1
6 end = points[0][1]
7 for i in range(1,len(points)):
8 if points[i][0] > end:
9 count += 1
10 end = points[i][1]
11 return count
思路和上一题leetcode 435. 很像。就是一定要按照结束时间排序。什么时候开始不重要,什么时候结束才重要。只要后一个的开始小于前一个的结束,则在结束的那一刻一箭都能洞穿
举例如下
```````````````````````````
`````````````
````````
`````
这种的是可以一箭洞穿的
1def findMinArrowShots(self, points: List[List[int]]) -> int:
2 intvs = sorted(points)
3 length = len(intvs)
4 start, end = intvs[0][0], intvs[0][1]
5 cnt = 1
6 for i in range(1, length):
7 s, e = intvs[i][0], intvs[i][1]
8 if s > end:
9 cnt += 1
10 end = e
11 else:
12 end = min(end, e)
13 return cnt
汇总区间¶
1def summaryRanges(self, nums: List[int]) -> List[str]:
2 nums += [float(inf)]
3 length = len(nums)
4 ans = []
5 for i in range(length):
6 if i == 0:
7 start = nums[i]
8 end = nums[i]
9 elif nums[i] - nums[i - 1] == 1:
10 end = nums[i]
11 elif nums[i] - nums[i - 1] > 1:
12 if end == start:
13 interval = str(start)
14 else:
15 interval = str(start) + "->" + str(end)
16 start = nums[i]
17 end = nums[i]
18 ans.append(interval)
19 return ans
leetcode 163 759 986 630
矩阵/二维数组¶
旋转二维数组总结¶
类似这种题目,一个n x n的二维数组进行旋转。做一个总结。
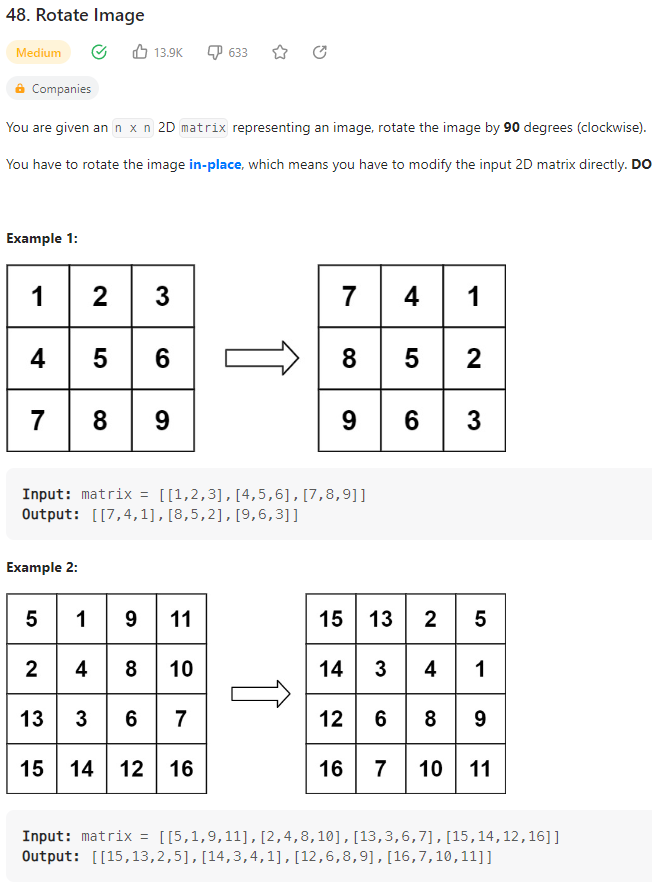
无外乎四种旋转进行组合:
1// 上下对称
2void upDownSymmetry(vector<vector<int>>& matrix) {
3 for (int i = 0; i < n/2; ++i) {
4 for (int j = 0; j < n; ++j) {
5 swap(matrix[i][j], matrix[n-i-1][j]);
6 }
7 }
8}
9
10// 左右对称
11void leftRightSymmetry(vector<vector<int>>& matrix) {
12 for (int i = 0; i < n; ++i) {
13 for (int j = 0; j < n/2; ++j) {
14 swap(matrix[i][j], matrix[i][n-j-1]);
15 }
16 }
17}
18
19// 主对角线对称
20void mainDiagSymmetry(vector<vector<int>>& matrix) {
21 for (int i = 0; i < n-1; ++i) {
22 for (int j = i + 1; j < n; ++j) {
23 swap(matrix[i][j], matrix[j][i]);
24 }
25 }
26}
27
28// 副对角线对称
29void subdiagSymmetry(vector<vector<int>>& matrix) {
30 for (int i = 0; i < n-1; ++i) {
31 for (int j = 0; j < n-i-1; ++j) {
32 swap(matrix[i][j], matrix[n-j-1][n-i-1]);
33 }
34 }
35}
注意这里的 交换,和 i,j的范围
例题解答看下面
旋转图像¶
建议使用:
1def rotate(self, matrix: List[List[int]]) -> None:
2 """
3 Do not return anything, modify matrix in-place instead.
4 """
5 def updown(matrix, n):
6 for i in range(n // 2):
7 for j in range(n):
8 matrix[i][j], matrix[n - i - 1][j] = matrix[n - i - 1][j], matrix[i][j]
9 return matrix
10
11 def diagonal(matrix, n):
12 for i in range(n):
13 for j in range(i, n):
14 matrix[i][j], matrix[j][i] = matrix[j][i], matrix[i][j]
15 return matrix
16 n = len(matrix)
17 matrix = updown(matrix, n)
18 matrix = diagonal(matrix, n)
19 return matrix
1def rotate(self, matrix: List[List[int]]) -> None:
2 """
3 Do not return anything, modify matrix in-place instead.
4 """
5 for i in range(len(matrix)):
6 for j in range(i,len(matrix[0])):
7 matrix[i][j],matrix[j][i] = matrix[j][i], matrix[i][j]
8 for i in range(len(matrix)):
9 matrix[i] = matrix[i][::-1]
这里上下翻转为何不能使用 matrix = matrix[::-1]? 因为这里需要in-place。这种方法会开辟一个额外空间。然后题目还是会去检测之前的matrix所在空间的值
螺旋矩阵/顺时针打印矩阵¶
leetcode 54. / 剑指 Offer 29.
输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。
示例 1:
示例 2:
这种方式更加科学:
1def spiralOrder(self, matrix: List[List[int]]) -> List[int]:
2 up, down, left, right = 0, len(matrix) - 1, 0, len(matrix[0]) - 1
3 ans = []
4 while True:
5 for i in range(left, right + 1):
6 ans.append(matrix[up][i])
7 up += 1
8 if up > down:
9 break
10 for i in range(up, down + 1):
11 ans.append(matrix[i][right])
12 right -= 1
13 if right < left:
14 break
15 for i in range(right, left - 1, -1):
16 ans.append(matrix[down][i])
17 down -= 1
18 if up > down:
19 break
20 for i in range(down, up - 1, -1):
21 ans.append(matrix[i][left])
22 left += 1
23 if left > right:
24 break
25 return ans
另一种很憨憨的解法,一板一眼的去做:
1class Solution:
2 def spiralOrder(self, matrix: List[List[int]]) -> List[int]:
3 res = []
4 def turn_right(matrix,res):
5 res+=matrix[0]
6 matrix = matrix[1:]
7 return matrix, res
8
9 def turn_down(matrix,res):
10 new_matrix = []
11 for line in matrix:
12 res.append(line[-1])
13 line = line[:-1]
14 new_matrix.append(line)
15 return new_matrix,res
16
17 def turn_left(matrix,res):
18 res+=matrix[-1][::-1]
19 matrix = matrix[:-1]
20 return matrix, res
21
22 def turn_up(matrix,res):
23 new_matrix = []
24 temp = []
25 for line in matrix:
26 temp.append(line[0])
27 line = line[1:]
28 new_matrix.append(line)
29 res += temp[::-1]
30 return new_matrix,res
31 i = 0
32 while len(matrix)>0 and len(matrix[0])>0:
33 if i%4==0:
34 matrix,res = turn_right(matrix,res)
35 i+=1
36 continue
37 if i%4==1:
38 matrix,res = turn_down(matrix,res)
39 i+=1
40 continue
41 if i%4==2:
42 matrix,res = turn_left(matrix,res)
43 i+=1
44 continue
45 if i%4==3:
46 matrix,res = turn_up(matrix,res)
47 i+=1
48 continue
49 return res
螺旋矩阵 II¶
1def generateMatrix(self, n: int) -> List[List[int]]:
2 left, right, up, down = 0, n - 1, 0, n - 1
3 i, j = 0, 0
4 dp = [[0] * n for _ in range(n)]
5 num = 1
6 while num <= n ** 2:
7 for j in range(left, right + 1):
8 dp[i][j] = num
9 num += 1
10 up += 1
11 for i in range(up, down + 1):
12 dp[i][j] = num
13 num += 1
14 right -= 1
15 for j in range(right, left - 1, -1):
16 dp[i][j] = num
17 num += 1
18 down -= 1
19 for i in range(down, up - 1, -1):
20 dp[i][j] = num
21 num += 1
22 left += 1
23 return dp
289. Game of Life¶
According to Wikipedia’s article: “The Game of Life, also known simply as Life, is a cellular automaton devised by the British mathematician John Horton Conway in 1970.”
The board is made up of an m x n grid of cells, where each cell has an initial state: live (represented by a 1) or dead (represented by a 0). Each cell interacts with its eight neighbors (horizontal, vertical, diagonal) using the following four rules (taken from the above Wikipedia article):
Any live cell with fewer than two live neighbors dies as if caused by under-population. Any live cell with two or three live neighbors lives on to the next generation. Any live cell with more than three live neighbors dies, as if by over-population. Any dead cell with exactly three live neighbors becomes a live cell, as if by reproduction. The next state is created by applying the above rules simultaneously to every cell in the current state, where births and deaths occur simultaneously. Given the current state of the m x n grid board, return the next state.
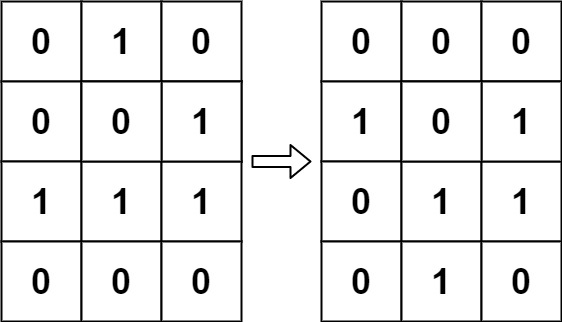
1def gameOfLife(self, board: List[List[int]]) -> None:
2 """
3 Do not return anything, modify board in-place instead.
4 """
5 m = len(board)
6 n = len(board[0])
7 def check(i, j):
8 count = 0
9 for (a, b) in [(i + 1, j), (i + 1, j + 1), (i + 1, j - 1), (i, j - 1), (i, j + 1), (i - 1, j), (i - 1, j + 1), (i - 1, j - 1)]:
10 if 0 <= a <= m - 1 and 0 <= b <= n - 1 and (board[a][b] == 1 or board[a][b] == 2):
11 count += 1
12 return count
13
14 for i in range(m):
15 for j in range(n):
16 live = check(i, j)
17 if board[i][j] == 1 and live < 2:
18 board[i][j] = 2
19 if board[i][j] == 1 and live > 3:
20 board[i][j] = 2
21 if board[i][j] == 0 and live == 3:
22 board[i][j] = 3
23
24 for i in range(m):
25 for j in range(n):
26 if board[i][j] == 2:
27 board[i][j] = 0
28 if board[i][j] == 3:
29 board[i][j] = 1
73. Set Matrix Zeroes¶
Given an m x n integer matrix matrix, if an element is 0, set its entire row and column to 0’s.
You must do it in place.
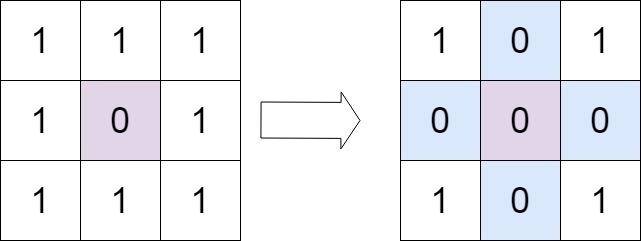
如果要用O(1)的空间复杂度:
1def setZeroes(self, matrix: List[List[int]]) -> None:
2 """
3 Do not return anything, modify matrix in-place instead.
4 """
5 row = len(matrix)
6 col = len(matrix[0])
7 row0_flag = 0
8 col0_flag = 0
9 for j in range(col):
10 if matrix[0][j] == 0:
11 row0_flag = 1
12 break
13 for i in range(row):
14 if matrix[i][0] == 0:
15 col0_flag = 1
16 break
17
18 for i in range(1, row):
19 for j in range(1, col):
20 if matrix[i][j] == 0:
21 matrix[i][0] = matrix[0][j] = 0
22
23 for i in range(1, row):
24 for j in range(1, col):
25 if matrix[i][0] == 0 or matrix[0][j] == 0:
26 matrix[i][j] = 0
27 if row0_flag == 1:
28 for j in range(col):
29 matrix[0][j] = 0
30 if col0_flag == 1:
31 for i in range(row):
32 matrix[i][0] = 0
33
34 return matrix
35
36
37 """
38 参考了https://leetcode.cn/problems/set-matrix-zeroes/solution/o1kong-jian-by-powcai/
39 为什么要从第二行(1)和第二列(1)开始遍历,这个很重要!!
40
41
42 因为[0][0]这个位置太重要了,如果只是第一行中间有0,会把第一列也变零
43 """
黑白棋翻转¶
1def solution(arr):
2 if not arr:
3 return []
4 queue = []
5 m = len(arr)
6 for i in range(m):
7 if arr[i][0] == 0:
8 queue.append((i, 0))
9 if arr[i][m - 1] == 0:
10 queue.append((i, m - 1))
11 if arr[0][i] == 0:
12 queue.append((0, i))
13 if arr[m - 1][i] == 0:
14 queue.append((m - 1, i))
15
16 while queue:
17 r, c = queue.pop()
18 if 0 <= r < m and 0 <= c < m and arr[r][c] == 0:
19 arr[r][c] = "#"
20 for (i,j) in [(r + 1, c),(r - 1, c),(r, c + 1),(r, c - 1)]:
21 if 0 <= i < m and 0 <= j < m and arr[i][j]==0:
22 queue.append((i,j))
23
24 for i in range(m):
25 for j in range(m):
26 if arr[i][j] == 0:
27 arr[i][j] = 1
28 elif arr[i][j] == "#":
29 arr[i][j] = 0
30
31 return arr
扫描三次就好了。第一次把四条边上的0计入队列,准备变成’#’
第二次把这些#的四周以及能够蔓延到的地方全部变#
第三次把剩下的0变1,然后把#再变回0.
注意,第二次遍历的时候需要用这个队列,而不能直接从左上到右下去扫描,不然矩阵靠右的会有点问题。 比如有一行是1000,那么第一个0是看不到最右边的#的
好吧其实遍历两次就行。和下题基本一样
被围绕的区域¶
leetcode 130.
给你一个 m x n 的矩阵 board ,由若干字符 ‘X’ 和 ‘O’ ,找到所有被 ‘X’ 围绕的区域,并将这些区域里所有的 ‘O’ 用 ‘X’ 填充。
1def solve(self, board: List[List[str]]) -> None:
2 """
3 Do not return anything, modify board in-place instead.
4 """
5 direct = [(0, 1), (0, -1), (1, 0), (-1, 0)]
6 m, n = len(board), len(board[0])
7 def expand(i, j):
8 for x, y in direct:
9 if 0 <= i + x <= m - 1 and 0 <= j + y <= n - 1 and board[i + x][j + y] == "O":
10 board[i + x][j + y] = "#"
11 expand(i + x, j + y)
12 for i in range(m):
13 if board[i][0] == "O":
14 board[i][0] = "#"
15 expand(i, 0)
16 if board[i][n-1] == "O":
17 board[i][n-1] = "#"
18 expand(i, n-1)
19 for j in range(n):
20 if board[0][j] == "O":
21 board[0][j] = "#"
22 expand(0, j)
23 if board[m-1][j] == "O":
24 board[m-1][j] = "#"
25 expand(m-1, j)
26 for i in range(m):
27 for j in range(n):
28 if board[i][j] == "O":
29 board[i][j] = "X"
30 if board[i][j] == "#":
31 board[i][j] = "O"
从边缘的”O”找起,这些肯定是不能被同化的,标记为”#”。然后开始感染,这些被感染到的也不能被同化,标记为”#”
第二次遍历,判断一下,如果当前是”O”,则被同化为”x”。如果被标记为”#”则还原回”O”。这里注意先后顺序就行
注意!!!
这里不能图省事,写成expand(i, -1),不然传进去的index在做+1 -1操作的时候是不对的:
if board[i][n-1] == "O":
board[i][n-1] = "#"
expand(i, n-1)
如果不用递归,这种方式也很好,找一个数组存起来,然后一个个的pop出来:
1def solve(self, board: List[List[str]]) -> None:
2 """
3 Do not return anything, modify board in-place instead.
4 """
5 m, n = len(board), len(board[0])
6 queue = deque([])
7 # 将边缘上的 'O' 入队
8 for i in range(m):
9 if board[i][0] == "O":
10 queue.append((i, 0))
11 if board[i][n-1] == "O":
12 queue.append((i, n-1))
13 for j in range(n):
14 if board[0][j] == "O":
15 queue.append((0, j))
16 if board[m-1][j] == "O":
17 queue.append((m-1, j))
18 # BFS 遍历边缘上的 'O',将其标记
19 while queue:
20 i, j = queue.popleft()
21 if 0 <= i < m and 0 <= j < n and board[i][j] == "O":
22 board[i][j] = "#"
23 queue.extend([(i-1, j), (i+1, j), (i, j-1), (i, j+1)])
24 # 最终遍历,对标记过的 'O' 进行修改
25 for i in range(m):
26 for j in range(n):
27 if board[i][j] == "O":
28 board[i][j] = "X"
29 if board[i][j] == "#":
30 board[i][j] = "O"
最大矩形¶
1def maximalRectangle(self, matrix: List[List[str]]) -> int:
2 if not matrix:
3 return 0
4
5 def largestRectangleArea(heights):
6 heights.append(0)
7 stack = [-1]
8 max_area = 0
9 for i in range(len(heights)):
10 while heights[i] < heights[stack[-1]]:
11 h = heights[stack.pop()]
12 w = i - stack[-1] - 1
13 max_area = max(max_area, h*w)
14 stack.append(i)
15 return max_area
16
17 cur = [0] * len(matrix[0])
18 ans = 0
19 for i in range(len(matrix)):
20 for j in range(len(matrix[0])):
21 if matrix[i][j] == "0":
22 cur[j] = 0
23 else:
24 cur[j] += 1
25 ans = max(ans, largestRectangleArea(cur))
26 return ans
这个题需要结合上一题(leetcode 84)
基本思路是这样:以行为单位,遍历到某行的时候,向上看,形成类似上一题的一个个矩形。如果当前是1,那么就一直到上一个0为止,如果本身是0,那么当前位置的矩形也是0。 然后再调用上一题的代码求面积。
https://leetcode-cn.com/problems/maximal-rectangle/solution/zhong-die-fa-kuai-su-jie-ti-by-my10yuan/ 这个老哥的思路不错,摘抄如下:
最大子矩阵¶
1def getMaxMatrix(self, matrix: List[List[int]]) -> List[int]:
2 def max_1d(array):
3 if not array:
4 return float('-inf')
5 ans = temp = float('-inf')
6 start_temp, start_final, end_final = 0, 0, 0
7 for i in range(len(array)):
8 if temp + array[i] > array[i]:
9 temp = temp + array[i]
10 else:
11 start_temp = i
12 temp = array[i]
13
14 if temp > ans:
15 start_final, end_final = start_temp, i
16 ans = temp
17 return start_final, end_final, ans
18
19 row = len(matrix)
20 col = len(matrix[0])
21 maxArea = float('-inf') #最大面积
22 res = [0, 0, 0, 0]
23
24 for left in range(col): #从左到右,从上到下,滚动遍历
25 colSum = [0] * row #以left为左边界,每行的总和
26 for right in range(left, col): #这一列每一位为右边界
27 for i in range(row): #遍历列中每一位,计算前缀和
28 colSum[i] += matrix[i][right]
29
30 startX, endX, maxAreaCur= max_1d(colSum)#在left,right为边界下的矩阵中,前缀和colSum的最大值
31 if maxAreaCur > maxArea:
32 res = [startX, left, endX, right] #left是起点y轴坐标,right是终点y轴坐标
33 maxArea = maxAreaCur
34 return res
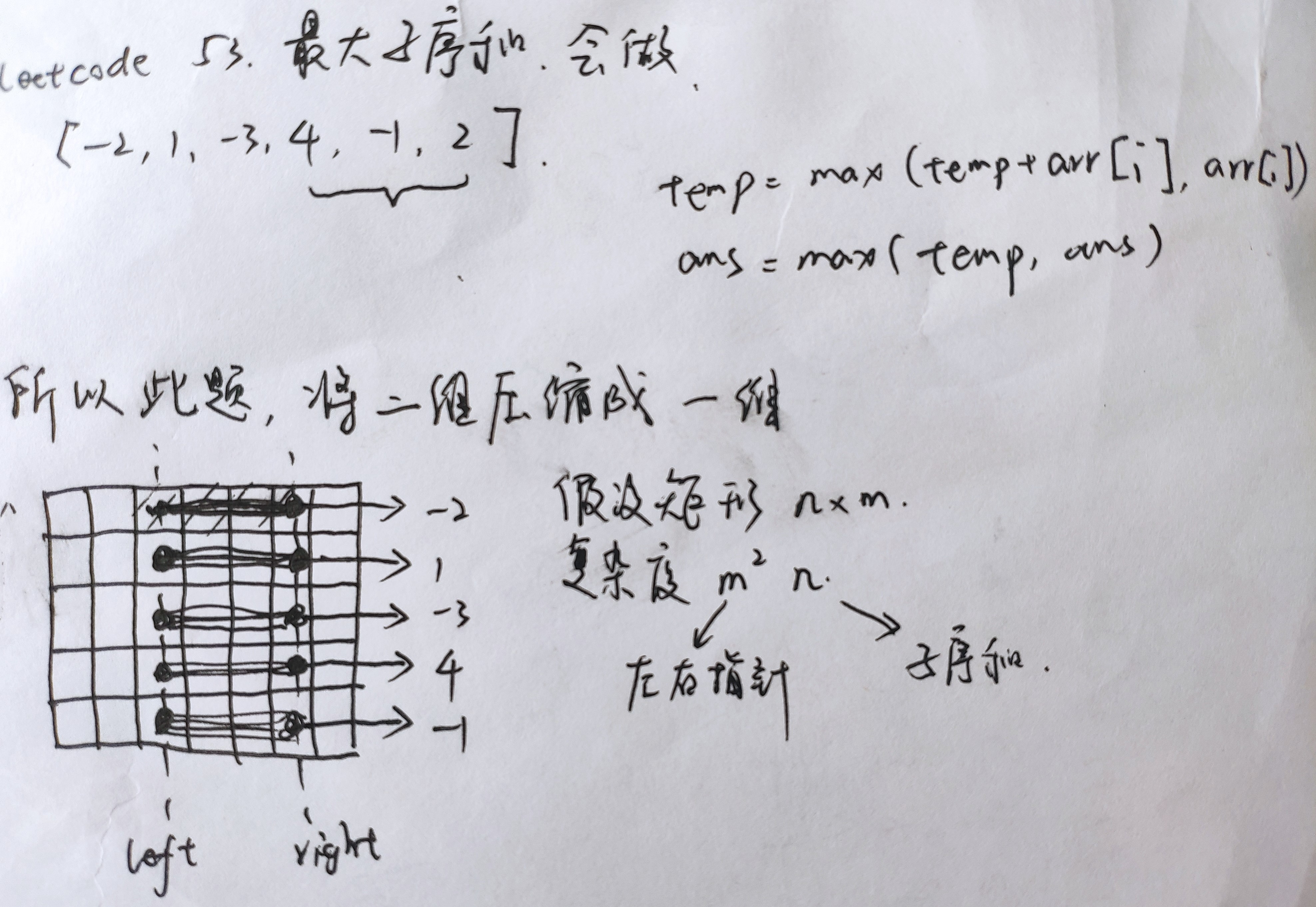
为什么是以列来两个指针遍历? 因为按照行的话不好求和
329. Longest Increasing Path in a Matrix¶
Given an m x n integers matrix, return the length of the longest increasing path in matrix.
From each cell, you can either move in four directions: left, right, up, or down. You may not move diagonally or move outside the boundary (i.e., wrap-around is not allowed).

1def longestIncreasingPath(self, matrix: List[List[int]]) -> int:
2 path = [(1, 0), (-1, 0), (0, 1), (0, -1)]
3 m, n = len(matrix), len(matrix[0])
4 store = [[0] * n for _ in range(m)]
5 def dfs(i, j):
6 if store[i][j] != 0:
7 return store[i][j]
8 store[i][j] = 1
9 for x, y in path:
10 x += i
11 y += j
12 if 0 <= x <= m - 1 and 0 <= y <= n - 1 and matrix[i][j] > matrix[x][y]:
13 store[i][j] = max(store[i][j], dfs(x, y) + 1)
14 return store[i][j]
15 cnt = 0
16 for i in range(m):
17 for j in range(n):
18 cnt = max(cnt, dfs(i, j))
19 return cnt
dfs + 记忆化搜索
一直找,找到最小的1为止
请看下一题
最长波动路径¶
Tiktok面试题
给定一个矩阵,比如[[2,1,3],[4,2,1],[3,5,5]], 一个valid sequence[a,b,c,d,e…..]需要满足a < b > c < d > e <……,假设可以从矩阵任意一个点出发,只能上下左右移动,让longest length of all valid sequences.
答案from Claude 3.5 Sonnet
1def longestValidSequence(matrix):
2 if not matrix or not matrix[0]:
3 return 0
4
5 m, n = len(matrix), len(matrix[0])
6 dp_up = [[1] * n for _ in range(m)]
7 dp_down = [[1] * n for _ in range(m)]
8
9 def dfs(i, j, prev, is_up):
10 if i < 0 or i >= m or j < 0 or j >= n:
11 return 0
12 if is_up and matrix[i][j] <= prev:
13 return 0
14 if not is_up and matrix[i][j] >= prev:
15 return 0
16
17 dp = dp_down if is_up else dp_up
18 if dp[i][j] > 1:
19 return dp[i][j]
20
21 max_len = 1
22 for di, dj in [(0, 1), (1, 0), (0, -1), (-1, 0)]:
23 new_i, new_j = i + di, j + dj
24 max_len = max(max_len, 1 + dfs(new_i, new_j, matrix[i][j], not is_up))
25
26 dp[i][j] = max_len
27 return max_len
28
29 result = 0
30 for i in range(m):
31 for j in range(n):
32 result = max(result, dfs(i, j, -float('inf'), True), dfs(i, j, float('inf'), False))
33
34 return result
这里多一点:需要递增矩阵和递减矩阵。需要传上一个值。需要传递增还是递减
找规律&斐波拉契&数学¶
跳台阶—斐波拉契¶
剪绳子¶
剑指 Offer 14- I.
数字序列中某一位的数字¶
剑指 Offer 44.
数字以0123456789101112131415…的格式序列化到一个字符序列中。在这个序列中,第5位(从下标0开始计数)是5,第13位是1,第19位是4,等等。
请写一个函数,求任意第n位对应的数字。
1def findNthDigit(self, n: int) -> int:
2 digit, start, count = 1, 1, 9
3 while n > count: # 1.
4 n -= count
5 start *= 10
6 digit += 1
7 count = 9 * start * digit
8 num = start + (n - 1) // digit # 2.
9 return int(str(num)[(n - 1) % digit]) # 3.

把数字翻译成字符串¶
剑指 Offer 46.
给定一个数字,我们按照如下规则把它翻译为字符串:0 翻译成 “a” ,1 翻译成 “b”,……,11 翻译成 “l”,……,25 翻译成 “z”。一个数字可能有多个翻译。请编程实现一个函数,用来计算一个数字有多少种不同的翻译方法。
1def translateNum(self, num: int) -> int:
2 num = str(num)
3 if len(num)<=1:
4 return len(num)
5 if len(num)>=2:
6 if int(num[:2])<=25:
7 res = [1,2]
8 else:
9 res = [1,1]
10
11 for i in range(2,len(num)):
12 if int(num[i-1]+num[i])<=25 and num[i-1]!="0":
13 res.append(res[-1] + res[-2])
14 else:
15 res.append(res[-1])
16 return res[-1]
num[i-1]!=”0” 这里要注意,否则处理 506 这样带0的数据会出错
请看下一题
解码方法¶
1def numDecodings(self, s: str) -> int:
2 if s[0]=="0":
3 return 0
4 if len(s)==1:
5 return 1
6 res = [1,2]
7 if s[1] == "0" and int(s[0])>2:
8 return 0
9 if int(s[:2])>26 or s[:2]=="10" or s[:2]=="20":
10 res = [1, 1]
11 for i in range(2,len(s)):
12 if s[i]=="0":
13 temp1 = 0
14 if s[i-1]=="0" or int(s[i-1])>2:
15 return 0
16 else:
17 temp1 = res[-1]
18 if s[i-1]!="0" and int(s[i-1]+s[i])<=26:
19 temp2 = res[-2]
20 else:
21 temp2 = 0
22 res.append(temp1 + temp2)
23 return res[-1]
情况的讨论还比较复杂,比上一题难在0没有对应,所以初始化包括之后会要多讨论。
而且注意这是字符串,所以s[i]==str(xxx)这里的str不能忘
n个骰子的点数¶
剑指 Offer 60.
把n个骰子扔在地上,所有骰子朝上一面的点数之和为s。输入n,打印出s的所有可能的值出现的概率。
你需要用一个浮点数数组返回答案,其中第 i 个元素代表这 n 个骰子所能掷出的点数集合中第 i 小的那个的概率。
1def twoSum(self, n: int) -> List[float]:
2 if n==0:
3 return []
4 probs =[0]*6 + [1]*6
5 count = 1
6 while count < n:
7 temp = []
8 for i in range(len(probs)+6):
9 left = max(0,i-6)
10 right = min(len(probs),i)
11 cur = sum(probs[left:right])
12 temp.append(cur)
13 probs = temp
14 count +=1
15 res = []
16 for x in probs:
17 if x > 0:
18 res.append(x/(6**n))
19 return res
我的憨憨解法思想如下: 下一轮在更新的时候,达到这个值的数量是上一轮前六个数的相加。
要特别注意边界条件。所以我在第一轮前面加了六个0,前几轮要判断左边界。 然后在这一轮能够新生成的6个数,要判断右边界。
阶乘后的零¶
leetcode 172.
给定一个整数 n ,返回 n! 结果中尾随零的数量。
提示 n! = n * (n - 1) * (n - 2) * … * 3 * 2 * 1
1def trailingZeroes(self, n: int) -> int:
2 ans = 0
3 while n >= 1:
4 ans += n // 5
5 n /= 5
6 return int(ans)
注意 这里是末尾的0,所以7!=4020 只有一个0

小于n的最大整数¶
字节面试题 https://leetcode.cn/circle/discuss/BlvA0l/
通过给定的数字列表A和整数n,生成一个小于n的最大整数,其中每一位数字都属于列表A。例如A={1, 2, 4, 9},n=2533,返回2499
1def solve(A, n):
2 A.sort()
3 nums = list(map(int, str(n))) # 拆分位数
4 length = len(nums)
5 i = 0
6 while i < length - 1:
7 if nums[i] not in A or nums[i + 1] <= A[0]:
8 break
9 i += 1
10
11 # 找到一个小的,然后再找大的
12
13 ## 如果出现最小的可选数都比当前位数的要大,则缺一位
14 if nums[i] <= A[0]:
15 return [A[-1]] * (length - 1)
16
17 ## 正常返回 前面能匹配上的 + 小一点的 + 后面全选最大的
18 for j in range(len(A) - 1, -1 , -1):
19 if A[j] < nums[i]:
20 break
21 return nums[:i] + [A[j]] + [A[-1]] * (length - i - 1)
总体思路:
小于n的最大整数可以这样构造:前x位数相等,第 x+1 位数更小,剩下的数字尽可能大。因此可以枚举 x(0 <= x < n的位数),如果
n的前x位数字都在数组A中;
数组A中存在比 n的第x+1位数字 更小的数字,
注意:
while i < length - 1:
if nums[i] not in A or nums[i + 1] <= A[0]:
break
i += 1
关于while和for
这里还只能用while不能用for。 因为假设 solve([4, 5, 6, 9], 4956) == [4, 9, 5, 5] 这种情况。如果是for,到了倒数第二位会停下来,但此时并不知道这一位也是可以的。 只有用while,才能做到已经遍历过的i都是符合条件的。
备:测试案例:
1assert solve([1, 2, 4, 9], 2533) == [2, 4, 9, 9]
2assert solve([4, 2, 5, 9], 2451) == [2, 4, 4, 9]
3assert solve([2], 1111) == [2, 2, 2]
4assert solve([2], 33333) == [2, 2, 2, 2, 2]
5assert solve([1,2,3], 321) == [3, 1, 3]
6assert solve([1,2,3], 3) == [2]
7assert solve([4,3,9], 44321) == [4, 3, 9, 9, 9]
8assert solve([2,4,5], 24131) == [2, 2, 5, 5, 5]
9assert solve([1, 2, 4, 9], 2409) == [2, 2, 9, 9]
10assert solve([1, 2, 4, 9], 4921) == [4, 9, 1, 9]
11assert solve([1, 2, 4, 9], 2100) == [1, 9, 9, 9]
12assert solve([1, 2, 4, 9], 1) == []
13assert solve([4, 5, 6, 9], 4956) == [4, 9, 5, 5]
14assert solve([0, 4, 9], 4956) == [4, 9, 4, 9]
15assert solve([6, 9], 589) == [9, 9]
16assert solve([1], 4956) == [1, 1, 1, 1]
17assert solve([6,7,8], 1200) == [8, 8, 8]
18assert solve([2,3,5], 3211) == [2,5,5,5]
19assert solve([1,2,9], 1201) == [1,1,9,9]
20assert solve([1,2,4,9],999) == [9,9,4]
21assert solve([1,2,4,9],1111) == [9,9,9]
22assert solve([1,2,4,9],2533) == [2,4,9,9]
23assert solve([1,2,4,9],4921) == [4,9,1,9]
24assert solve([1,2,4,9],1249) == [1,2,4,4]
25assert solve([2,4,5],24131) == [2,2,5,5,5]
链表¶
前置学习内容¶
https://www.youtube.com/watch?v=0czlvlqg5xw
这个视频说的很好。链表的题目其实不复杂。基本上就是双指针(快慢指针or前后指针)或者递归. 而且链表只能前进不能后退,是缺点也是优点,简化了很多思路,导致基本上都需要用双指针来解决
有这样一些小技巧:
- dummy = ListNode(0, head) 虚拟头节点是真的好用
- 实在不行就需要保存的地方就设置一个变量,然后充分利用python的同时交换的特性,大力出奇迹
反转链表¶
leetcode 206./ 剑指 Offer 24.
定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。
示例:
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
双指针方法一,这个需要当成模板背下来!!!
1def reverseList(self, head):
2 """
3 :type head: ListNode
4 :rtype: ListNode
5 """
6 pre = None
7 cur = head
8 # 遍历链表,while循环里面的内容其实可以写成一行
9 # 这里只做演示,就不搞那么骚气的写法了
10 while cur:
11 # 记录当前节点的下一个节点
12 tmp = cur.next
13 # 然后将当前节点指向pre
14 cur.next = pre
15 # pre和cur节点都前进一位
16 pre = cur
17 cur = tmp
18 return pre
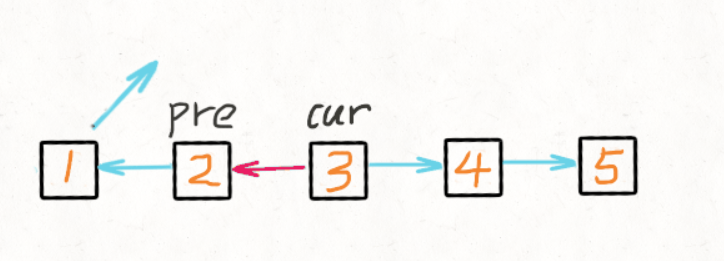
递归recursion
1def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:
2 if not head:
3 return
4 def helper(cur, pre):
5 if not cur:
6 return pre
7 res = helper(cur.next, cur)
8 cur.next = pre
9 return res
10 return helper(head, None)
这个递归比较难理解。但其实我们应该从后往前看。 假设是12345。这里的res通过层层往下,最后会固定在5这里。我们本身想返回的也就是5这个头。 然后在每一层里面,做的事情就是把后面指向前面.第7行的这个代码其实是阻止我们先反转顺序,而是让我们先找到头。然后再一层层的反转顺序
请看下一题
反转链表 II¶
方法一:递归(先得看懂上一题):
1def reverseBetween(self, head: Optional[ListNode], left: int, right: int) -> Optional[ListNode]:
2 def reverseN(node, n):
3 if n == right:
4 self.successor = node.next
5 return node
6 new_head = reverseN(node.next, n + 1)
7 node.next.next = node
8 node.next = self.successor
9 return new_head
10 if not head.next:
11 return head
12 if left == 1:
13 return reverseN(head, 1)
14 head.next = self.reverseBetween(head.next, left - 1, right - 1)
15 return head
参考了 这个解析
如果我们明白了上一个简单题目的递归,那么我们知道,其实递归最后得到的是 “new_head”.
在此基础上,可以将题目稍微升级成 “反转链表前 N 个节点”。解决思路差不多,但是需要额外保存一个后续节点successor。因为之前是直接把最后的尾巴指向None了,现在需要指向后续节点successor.
这里 self.successor 的写法就很有灵性,把successor当作一个属性,这样整个类中都可以调用。避免到处定义局部变量全局变量
明白这个 “反转链表前 N 个节点” 之后,那么问题只需要变成,从哪个节点开始进行这个操作。这个也可以递归解决!本来假设left, right是3,6. 那么挪一挪 以left为1 就会变成1,4
方法二:双指针-头插法:
1def reverseBetween(self, head: Optional[ListNode], left: int, right: int) -> Optional[ListNode]:
2 dummy = ListNode(0, head)
3 pre = dummy
4 cnt = 0
5 while cnt < left - 1:
6 pre = pre.next
7 cnt += 1
8 cur = pre.next
9 while cnt < right - 1:
10 temp = cur.next
11 cur.next, pre.next, temp.next = temp.next, temp, pre.next
12 cnt += 1
13 return dummy.next
参考了 这个解析
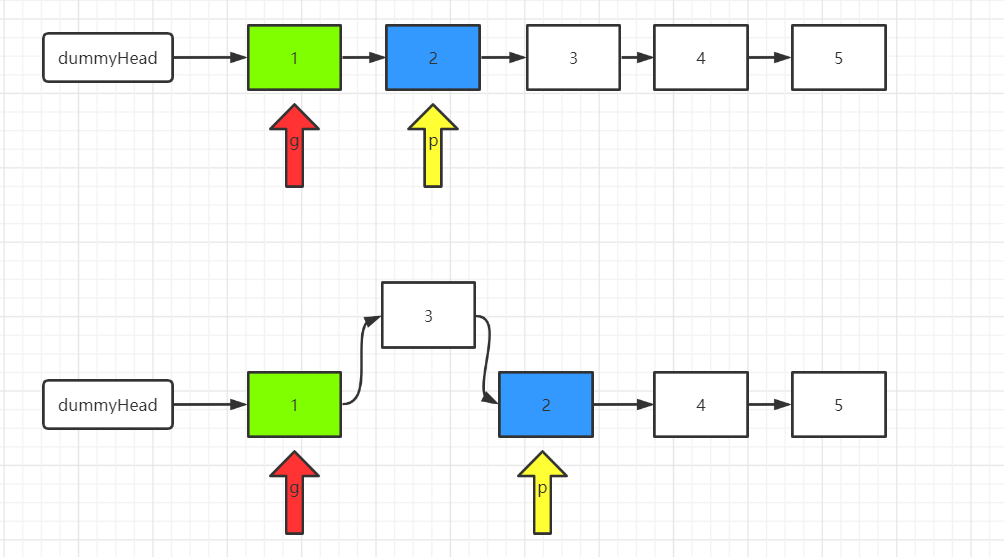
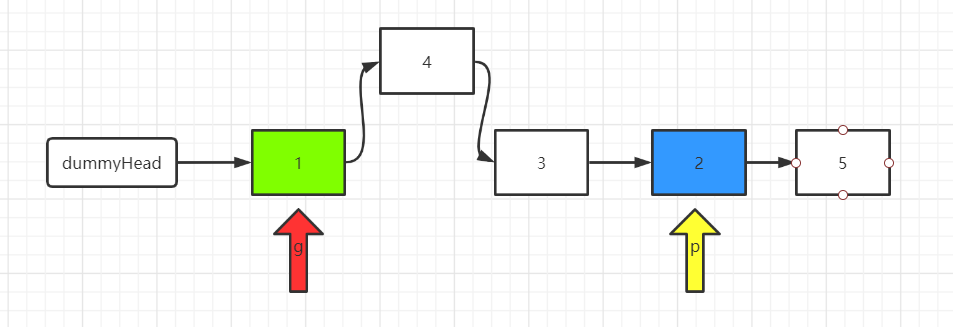
主要是对着这个图来进行操作。要先画图出来
dummy = ListNode(0, head) 虚拟头节点是真的好用, 凡是需要考虑左右边界的问题, 加个虚拟头节点准没错.
实在不行就需要保存的地方就设置一个变量,然后充分利用python的同时交换的特性,大力出奇迹:
1while cnt < right - 1:
2 temp1 = cur.next
3 temp2 = pre.next
4 cur.next, pre.next, temp1.next = temp1.next, temp1, temp2
5 cnt += 1
<table border=”1” class=”docutils”> <thead> <tr> <th></th> </tr> </thead> <tbody> <tr> <td></td> </tr> </tbody> </table>
这个是自己很早之前写的代码
1def reverseBetween(self, head: ListNode, m: int, n: int) -> ListNode:
2 res = pre = ListNode(-1)
3 pre.next = head
4 count = 0
5 while count<m-1:
6 pre = pre.next
7 count += 1
8 temp1 = pre
9 tail = pre.next
10 after = None
11 pre = pre.next
12 count += 1
13 while count <= n:
14 temp2 = pre
15 temp = pre.next
16 pre.next = after
17 after = pre
18 pre = temp
19 count += 1
20 temp1.next = temp2
21 tail.next = temp
22 return res.next
141. Linked List Cycle¶
Given head, the head of a linked list, determine if the linked list has a cycle in it.
There is a cycle in a linked list if there is some node in the list that can be reached again by continuously following the next pointer. Internally, pos is used to denote the index of the node that tail’s next pointer is connected to. Note that pos is not passed as a parameter.
Return true if there is a cycle in the linked list. Otherwise, return false.
1def hasCycle(self, head: Optional[ListNode]) -> bool:
2 p = ListNode(0, head)
3 q = head
4 while q and q.next:
5 if p != q:
6 p = p.next
7 q = q.next.next
8 else:
9 return True
10 return False
简单的快慢指针。注意一开始不要让p q 都是head。不然 [1, 2] 这种情况就直接判定 p == q 然后就true了
两数相加¶
leetcode 2.
1# Definition for singly-linked list.
2# class ListNode:
3# def __init__(self, x):
4# self.val = x
5# self.next = None
6
7class Solution:
8 def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:
9 res = head = ListNode(0)
10 temp = 0
11 while l1 or l2 or temp:
12 x = l1.val if l1 else 0
13 y = l2.val if l2 else 0
14 head.next = ListNode((x + y + temp) % 10)
15 temp = (x + y + temp) // 10
16 if l1:
17 l1 = l1.next
18 if l2:
19 l2 = l2.next
20 head = head.next
21 return res.next
25. Reverse Nodes in k-Group¶
leetcode 25.
Given the head of a linked list, reverse the nodes of the list k at a time, and return the modified list.
k is a positive integer and is less than or equal to the length of the linked list. If the number of nodes is not a multiple of k then left-out nodes, in the end, should remain as it is.
You may not alter the values in the list’s nodes, only nodes themselves may be changed.
1def reverseKGroup(self, head: ListNode, k: int) -> ListNode:
2 def reverse(a, b): # 翻转从a到b的节点,左闭右开
3 pre, cur = None, a
4 while cur != b:
5 temp = cur.next
6 cur.next = pre
7 pre, cur = cur, temp
8 return pre
9
10 if not head:
11 return None
12 a = b = head
13 # b往前k步
14 for i in range(k):
15 if not b: return head # 不足k个的话说明翻转完成,直接返回head
16 b = b.next
17 # 翻转从a到b的节点,左闭右开
18 new_head = reverse(a, b)
19 a.next = self.reverseKGroup(b, k) # 这里要是a.next而不是b.next 因为已经翻转过,现在尾巴是a
20 return new_head
写的真的太好了,要多仔细研究
链表中倒数第k个节点¶
剑指 Offer 22.
输入一个链表,输出该链表中倒数第k个节点。
为了符合大多数人的习惯,本题从1开始计数,即链表的尾节点是倒数第1个节点。
例如,一个链表有6个节点,从头节点开始,它们的值依次是1、2、3、4、5、6。这个链表的倒数第3个节点是值为4的节点。:
1def getKthFromEnd(self, head: ListNode, k: int) -> ListNode:
2 l, r = head, head
3 i = 0
4 while i<k and r:
5 if not r:
6 return False
7 r = r.next
8 i+=1
9
10 while r:
11 r = r.next
12 l = l.next
13
14 return l
明显的双指针题目。请看下一题
19. Remove Nth Node From End of List¶
leetcode 19.
Given the head of a linked list, remove the nth node from the end of the list and return its head.
Example 1:
1def removeNthFromEnd(self, head: ListNode, n: int) -> ListNode:
2 pre = cur = head
3 for i in range(n):
4 cur = cur.next
5 if not cur:
6 return head.next
7 while cur.next:
8 pre = pre.next
9 cur = cur.next
10 pre.next = pre.next.next
11 return head
合并两个排序的链表¶
leetcode 21 / 剑指 Offer 25.
输入两个递增排序的链表,合并这两个链表并使新链表中的节点仍然是递增排序的。
示例1:
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4
1def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
2 res = temp = ListNode(0)
3 while l1 and l2:
4 if l1.val>=l2.val:
5 temp.next = l2
6 l2 = l2.next
7 else:
8 temp.next = l1
9 l1 = l1.next
10 temp = temp.next
11 if l1:
12 temp.next = l1
13 if l2:
14 temp.next = l2
15 return res.next
注意: temp = temp.next 这句话千万不能忘,然后开头的res = temp = ListNode(0) 也很关键!
递归:
1def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
2 def helper(l1, l2):
3 if not l1 and not l2:
4 return None
5 elif not l1:
6 return l2
7 elif not l2:
8 return l1
9 elif l1.val <= l2.val:
10 node = ListNode(l1.val)
11 node.next = helper(l1.next, l2)
12 else:
13 node = ListNode(l2.val)
14 node.next = helper(l1, l2.next)
15 return node
16 return helper(l1, l2)
另外:不用额外空间合并两个排序的list
不用额外空间合并两个排序的list¶
1list1 = [1,3,5,7,8,9,13]
2list2 = [0,3,5,8,13,16]
3
4i,j = 0,0
5while i<=len(list1)-1 and list2:
6 print(i)
7 if list2[0]<=list1[i]:
8 num = list2.pop(0)
9 list1.insert(i,num)
10 else:
11 i+=1
12if list2:
13 list1+=list2
还有下面这道题
合并两个有序数组¶
leetcode88.
1def merge(self, nums1: List[int], m: int, nums2: List[int], n: int) -> None:
2 """
3 Do not return anything, modify nums1 in-place instead.
4 """
5 p1, p2 = m-1, n-1
6 p = m + n -1
7 while p1>=0 and p2>=0:
8 if nums1[p1]>=nums2[p2]:
9 nums1[p] = nums1[p1]
10 p1 -= 1
11 else:
12 nums1[p] = nums2[p2]
13 p2 -= 1
14 p -= 1
15 if p2>=0:
16 nums1[:p2 + 1] = nums2[:p2 + 1]
从后往前排序。三个指针
两个链表的第一个公共节点¶
剑指 Offer 52.
好题!经典!常看!
输入两个链表,找出它们的第一个公共节点。

优秀解法:
1def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:
2 alist, blist = headA, headB
3 while headA != headB:
4 if headA:
5 headA = headA.next
6 else:
7 headA = blist
8 if headB:
9 headB = headB.next
10 else:
11 headB = alist
12 return headA
1def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:
2 alist, blist = headA, headB
3 if not headA or not headB:
4 return None
5 while headA != headB:
6 if headA.next==None and headB.next==None:
7 return None
8 if headA.next:
9 headA = headA.next
10 else:
11 headA = blist
12 if headB.next:
13 headB = headB.next
14 else:
15 headB = alist
16 return headA
所以上面那种优秀的解法完美的避开了我下面的这些坑。如果两个链表完全没有相同的结点,他会循环到两个人都是None,然后headA==headB,返回headA,恰好是None
当然,像他们那样写成这种形式的也可以
1def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:
2 node1, node2 = headA, headB
3 while node1 != node2:
4 node1 = node1.next if node1 else headB
5 node2 = node2.next if node2 else headA
6 return node1
看着简洁,但是可读性没有最开始的好。我还是建议分开写
环形链表¶
leetcode 141.
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false
1def hasCycle(self, head: Optional[ListNode]) -> bool:
2 p = ListNode(0, head)
3 q = head
4 while q and q.next:
5 if p != q:
6 p = p.next
7 q = q.next.next
8 else:
9 return True
10 return False
两两交换链表中的节点¶
1def swapPairs(self, head: ListNode) -> ListNode:
2 i = 0
3 res = m = ListNode(0)
4 m.next = head
5 while m:
6 if m.next and m.next.next and i%2==0:
7 temp_a = m.next
8 temp_b = m.next.next
9 temp_bnext = m.next.next.next
10 m.next, m.next.next, m.next.next.next = temp_b, temp_a, temp_bnext
11 m = m.next
12 i+=1
13 return res.next
碰到这种结点交换的题目,手画一个,然后分清前后关系。最开始做题的时候如果怕做错,就拿temp变量把他们都保存下来。
旋转链表¶
leetcode 61.
给定一个链表,旋转链表,将链表每个节点向右移动 k 个位置,其中 k 是非负数。
1def rotateRight(self, head: Optional[ListNode], k: int) -> Optional[ListNode]:
2 if not head or not head.next or k == 0:
3 return head
4 p = head
5 cnt = 1
6 while p.next:
7 cnt += 1
8 p = p.next
9 index = k % cnt
10
11 if index == 0:
12 return head
13 pre, cur = head, head
14 for i in range(index):
15 cur = cur.next
16 while cur and cur.next:
17 cur = cur.next
18 pre = pre.next
19 new_head = pre.next
20 pre.next = None
21 cur.next = head
22 return new_head
第一次遍历获得深度,取余。然后第二次遍历就是双指针了。记得处理一下特殊情况
方法二:首尾相接:
1def rotateRight(self, head: ListNode, k: int) -> ListNode:
2 if not head:
3 return None
4 pre = head
5 count = 0
6 while head and head.next:
7 count += 1
8 head = head.next
9
10 k = k % count
11 move = count - k
12 head.next = pre
13 while move:
14 head = head.next
15 pre = pre.next
16 move -= 1
17 head.next = None
18 return pre
删除排序链表中的重复元素 II¶
leetcode 82.
给定一个排序链表,删除所有含有重复数字的节点,只保留原始链表中 没有重复出现 的数字。
1def deleteDuplicates(self, head: ListNode) -> ListNode:
2 res = ListNode(-1)
3 res.next = head
4 l, r = res, head
5 while r and r.next:
6 if l.next.val != r.next.val:
7 l = l.next
8 r = r.next
9 elif l.next.val == r.next.val:
10 while r.next and l.next.val == r.next.val:
11 r = r.next
12 l.next = r.next
13 r = r.next
14 return res.next
多漂亮的解法!先来个伪头节点,然后双指针。注意while r.next and l.next.val == r.next.val: 这里的循环判断条件
请看下一题
删除排序链表中的重复元素¶
1def deleteDuplicates(self, head: ListNode) -> ListNode:
2 pre = ListNode(-1)
3 pre.next = head
4 l, r = pre, head
5 while r and r.next:
6 if l.next.val != r.next.val:
7 l = l.next
8 r = r.next
9 else:
10 while r.next and l.next.val == r.next.val:
11 r = r.next
12 l.next.next = r.next
13 l = l.next
14 r = r.next
15 return pre.next
分隔链表¶
方法一:搞两个listnode队列,分别填充大的和小的:
1def partition(self, head: ListNode, x: int) -> ListNode:
2 res1 = small = ListNode(-1)
3 res2 = big = ListNode(-1)
4 while head:
5 if head.val<x:
6 small.next = head
7 small = small.next
8 else:
9 big.next = head
10 big = big.next
11 head = head.next
12 big.next = None
13 small.next = res2.next
14 return res1.next
big.next = None这个不要忘了,不然没有尾结点
方法二:在原本的队列里面使用双指针:
1def partition(self, head: Optional[ListNode], x: int) -> Optional[ListNode]:
2 dummy = ListNode(-1, head)
3 pre = dummy # 在这之前的都小于x,队列的尾巴
4 cur = dummy # 用来判断下一个
5 while cur.next:
6 if cur.next.val < x:
7 if pre == cur: # 如果一直没遇到比x大的节点 就不需要交换节点 更新指针往后就行了
8 cur = cur.next
9 pre = pre.next
10 else:
11 temp = cur.next # 先暂存判断的节点
12 cur.next = temp.next # cur跳过下一个
13 temp.next = pre.next # 把temp插入 pre和下一个的中间
14 pre.next = temp # 把temp插入 pre和下一个的中间
15 pre = temp # 更新小队列的尾巴pre。
16 # 但是不能更新cur,因为cur的下一个已经换人了,还未判断过
17 else: # 只需要更新cur
18 cur = cur.next
19 return dummy.next
这个相对有技术含量。需要认真学习!!!
大致的意思是,pre,cur这俩双指针。pre是小队列的尾巴,那么在pre以及之前的都要小于x, cur永远是用来判断处理下一个的指针。需要注意的是,如果一直没遇到比x大的节点 就不需要交换节点 更新指针往后就行了,这段很重要,我之前没写导致内部循环 然后什么时候该更新pre和cur都要注意,不是每次两个指针都要更新。至于交换,那就是判断的下一个小的节点需要插入到pre的后面。然后原先的cur跳过这个节点就行。
排序链表¶
1def sortList(self, head: ListNode) -> ListNode:
2 # 快速排序
3 if not head: return None
4 # small equal large 的缩写
5 # 都指向相应链表的 head
6 s = e = l = None
7 target = head.val
8 while head:
9 nxt = head.next
10 if head.val>target:
11 head.next = l
12 l = head
13 elif head.val==target:
14 head.next = e
15 e = head
16 else:
17 head.next = s
18 s = head
19 head = nxt
20
21 s = self.sortList(s)
22 l = self.sortList(l)
23 # 合并 3 个链表
24 dummy = ListNode(0)
25 cur = dummy # cur: 非 None 的尾节点
26 # p: 下一个需要连接的节点
27 for p in [s, e, l]:
28 while p:
29 cur.next = p
30 p = p.next
31 cur = cur.next
32 return dummy.next
146. LRU Cache¶
Design a data structure that follows the constraints of a Least Recently Used (LRU) cache.
1class Node:
2 def __init__(self, key=0, value=0, prev=None, next=None):
3 self.key = key
4 self.value = value
5 self.prev = prev
6 self.next = next
7
8class LRUCache:
9
10 def __init__(self, capacity: int):
11 self.capacity = capacity
12 self.key_to_node = dict()
13 self.head, self.tail = Node(), Node()
14 self.tail.prev = self.head
15 self.head.next = self.tail
16
17 def remove(self, node):
18 node.prev.next, node.next.prev = node.next, node.prev
19
20 def put_first(self, node):
21 node.prev = self.head
22 node.next = self.head.next
23 self.head.next.prev = node
24 self.head.next = node # 这里顺序很重要!
25
26 def get(self, key: int) -> int:
27 if key not in self.key_to_node:
28 return -1
29 node = self.key_to_node[key]
30 self.remove(node)
31 self.put_first(node)
32 return node.value
33
34 def put(self, key: int, value: int) -> None:
35 if key not in self.key_to_node:
36 node = Node(key, value)
37 self.key_to_node[key] = node
38 if len(self.key_to_node) > self.capacity:
39 node = self.tail.prev
40 self.remove(node)
41 del self.key_to_node[node.key]
42 node = self.key_to_node[key]
43 self.put_first(node)
44 else:
45 node = self.key_to_node[key]
46 node.value = value
47 self.remove(node)
48 self.put_first(node)
参考了解析https://leetcode.cn/problems/lru-cache/solutions/12711/lru-ce-lue-xiang-jie-he-shi-xian-by-labuladong/
设置一个头节点和尾节点。实现 remove、put_first操作
Heap堆¶
Heap堆解题套路 https://www.youtube.com/watch?v=vIXf2M37e0k
datastream、online等 类似dp的输入特别适合堆而不是快排,因为是动态的
我查了一下,基本上面试的时候是能够import heapq的
python heapq用法¶
https://docs.python.org/zh-cn/3/library/heapq.html
我放几个常用的:
要创建一个堆,可以新建一个空列表 [],或者用函数 heapify() 把一个非空列表变为堆。
heapq.heappush(heap, item)
将 item 的值加入 heap 中,保持堆的不变性。
heapq.heappop(heap)
弹出并返回 heap 的最小的元素,保持堆的不变性。如果堆为空,抛出 IndexError 。 使用 heap[0]可以只访问最小的元素而不弹出它
heapq.heappushpop(heap, item)
将 item 放入堆中,然后弹出并返回 heap 的最小元素。该组合操作比先调用 heappush() 再调用 heappop() 运行起来更有效率。
heapq.heapify(x)
将list x 转换成堆,原地,线性时间内。注意,这里直接 store = [1,2,4,5,5] heapq.heapify(store) 就行,不需要找个变量来接住
如果是最大堆的话,取个负号就行。但是记得最后输出的时候也要再负回来
215. Kth Largest Element in an Array¶
leetcode 215.
Given an integer array nums and an integer k, return the kth largest element in the array.
Note that it is the kth largest element in the sorted order, not the kth distinct element.
构建最小堆:
1def findKthLargest(self, nums: List[int], k: int) -> int:
2 import heapq
3 store = []
4 for num in nums:
5 if len(store) < k:
6 heapq.heappush(store, num)
7 elif num > store[0]:
8 heapq.heappushpop(store, num)
9 return store[0]
构建一个k大小的最小堆。如果堆不满或者来的数比堆顶还大,那么就push。如果超出了k个就pop。这样堆顶总是保持在第k个最大的数。相当于比这个数大的都在堆里面,比他小的都没入堆。 时间复杂度为O(nlogk)
差一点的方法,构建最大堆:
1def findKthLargest(self, nums: List[int], k: int) -> int:
2 import heapq
3 store = [-num for num in nums]
4 heapq.heapify(store)
5 while k > 0:
6 ans = heapq.heappop(store)
7 k -= 1
8 return -ans
这个就是先构建一个最大堆,然后往外pop k-1 次
295. Find Median from Data Stream¶
The median is the middle value in an ordered integer list. If the size of the list is even, there is no middle value, and the median is the mean of the two middle values.
1class MedianFinder:
2 def __init__(self):
3 import heapq
4 self.lager = []
5 self.smaller = []
6
7 def addNum(self, num: int) -> None:
8 if not self.smaller or num < -self.smaller[0]:
9 heapq.heappush(self.smaller, -num)
10 else:
11 heapq.heappush(self.lager, num)
12
13 if len(self.lager) - len(self.smaller) > 1:
14 temp = heapq.heappop(self.lager)
15 heapq.heappush(self.smaller, -temp)
16 elif len(self.smaller) - len(self.lager) > 1:
17 temp = -heapq.heappop(self.smaller)
18 heapq.heappush(self.lager, temp)
19
20 def findMedian(self) -> float:
21 if (len(self.lager) + len(self.smaller)) % 2 == 0:
22 return (self.lager[0] - self.smaller[0]) / 2
23 else:
24 if len(self.smaller) > len(self.lager):
25 return -self.smaller[0]
26 else:
27 return self.lager[0]
一句话题解:左边大顶堆,右边小顶堆,小的加左边,大的加右边,平衡俩堆数,新加就弹出,堆顶给对家,奇数取多的,偶数取除2.
小技巧
一开始的时候可以构造一些例子:
[1,1,3,4,5,2,3,8]
[1,3,4] min lager
[1] max smaller
小技巧
这里不能写成这样:
1def addNum(self, num: int) -> None:
2 self.cnt += 1
3 if not self.smaller:
4 heapq.heappush(self.smaller, -num)
5 self.cnt_sm += 1
6 elif not self.lager:
7 heapq.heappush(self.lager, num)
8 self.cnt_lag += 1
9 elif num > self.lager[0]:
10 heapq.heappush(self.lager, num)
11 self.cnt_lag += 1
12 else:
13 heapq.heappush(self.smaller, -num)
14 self.cnt_sm += 1
因为还是需要使得 lager里面的内容大于smaller。所以lager的初始化应该是由smaller弹出去的
Follow up:
If all integer numbers from the stream are in the range [0, 100], how would you optimize your solution?
If 99% of all integer numbers from the stream are in the range [0, 100], how would you optimize your solution?
答案:
- 构造一个[0, 100]的计数筒
- 构造一个[0, 100]的计数筒。超出的部分单独排序和计数
373. Find K Pairs with Smallest Sums¶
You are given two integer arrays nums1 and nums2 sorted in non-decreasing order and an integer k.
Define a pair (u, v) which consists of one element from the first array and one element from the second array.
Return the k pairs (u1, v1), (u2, v2), …, (uk, vk) with the smallest sums.
1def kSmallestPairs(self, nums1: List[int], nums2: List[int], k: int) -> List[List[int]]:
2 import heapq
3 store = defaultdict(list)
4 compare = []
5 for i in range(len(nums1)):
6 for j in range(len(nums2)):
7 summ = nums1[i] + nums2[j]
8 if len(compare) <= k or summ < -compare[0]:
9 heapq.heappush(compare, -summ)
10 store[summ].append([nums1[i], nums2[j]])
11 if len(compare) > k:
12 num = -heapq.heappop(compare)
13 ans = []
14 used = set()
15 while compare:
16 num = -heapq.heappop(compare)
17 if num in used:
18 continue
19 else:
20 used.add(num)
21 combine = store[num]
22 for pair in combine:
23 ans.append(pair)
24 return ans[::-1][:k]
这种做法会导致Memory Limit Exceeded。当nums1和nums2都是很长一串list的时候。因为这个做法其实忽略了一件事,就是入栈的顺序,不应是i,j横扫过来进行遍历的。是需要选择的
1def kSmallestPairs(self, nums1: List[int], nums2: List[int], k: int) -> List[List[int]]:
2 import heapq
3 ans = []
4 temp = [[nums1[0] + nums2[0], 0, 0]]
5 while len(ans) < k:
6 value, i, j = heapq.heappop(temp)
7 ans.append([nums1[i], nums2[j]])
8 if i <= len(nums1) - 2 and j == 0:
9 heapq.heappush(temp, [nums1[i + 1] + nums2[0], i + 1, 0])
10 if j <= len(nums2) - 2:
11 heapq.heappush(temp, [nums1[i] + nums2[j + 1], i, j + 1])
12 return ans
但其实我有个更好的解释。如果当前最小值是nums1[i] + nums2[j]的时候,下一个要考虑的应该是nums1[i + 1] + nums2[j] 或者 nums1[i] + nums2[j + 1]
为了避免nums1[i + 1] + nums2[j + 1] 这个数被两次录入(i+1之后录入或者j+1之后录入),干脆舍弃一边
每次一定会向右走(j+=1),但是不一定会向下走(i+=1),除非是处理第一列的时候。只有此时才能确保下一行的左边没有待考虑的点了,不然由于每次向下走的时候都会继续向下,所以下一行的左边永远有黄点
举例,当处于步骤三的时候,[0,2]这个点不用考虑[1,2],因为此时[1,0]都还在,意味着下方的左边还有待确定的点。这些点一定比当前这个下方的点要小
相似题目(第 k 小/大)
- 查找和最小的 K 对数字
- 有序矩阵中第 K 小的元素
- 找出第 K 小的数对距离
- 第 K 个最小的素数分数
- 两个有序数组的第 K 小乘积
- 找出数组的第 K 大和
378. Kth Smallest Element in a Sorted Matrix¶
这个是上一题的简化版。
Given an n x n matrix where each of the rows and columns is sorted in ascending order, return the kth smallest element in the matrix.
Note that it is the kth smallest element in the sorted order, not the kth distinct element.
You must find a solution with a memory complexity better than O(n2).
用heapq的做法:
1def kthSmallest(self, matrix: List[List[int]], k: int) -> int:
2 cnt = 0
3 temp = [[matrix[0][0], 0, 0]]
4 while cnt < k:
5 value, i, j = heapq.heappop(temp)
6 cnt += 1
7 if i <= len(matrix) - 2 and j == 0:
8 heapq.heappush(temp, [matrix[i + 1][0], i + 1, 0])
9 if j <= len(matrix[0]) - 2:
10 heapq.heappush(temp, [matrix[i][j + 1], i, j + 1])
11 if cnt == k:
12 return value
先把第一列全部放进去,然后从左向右找,pop出来一个,这个数的右边就push进去一个
这种方法解答上一题也是可以的。
统计结果上来看,效果更好的是 二分搜索法
原理:某个m*n的二维矩阵,如果行是递增,列也是递增,那么左上角一定最小,右下角一定最大。 这里的二分不是对index二分,而是对值进行二分
相当于这里是通过left right的区间去逼近一个数,然后一行行的统计小于这个数的cnt。如果cnt < k 意味着这个mid小了,要找更大的数。
因为每次循环中都保证了第 k 小的数在 left ~ right 之间,当left==right 时,第 k 小的数即被找出,等于 right
1def kthSmallest(self, matrix: List[List[int]], k: int) -> int:
2 n = len(matrix)
3 left, right = matrix[0][0], matrix[-1][-1]
4 while left < right:
5 mid = (left + right) // 2
6 count = 0
7 j = n - 1
8 # Count the number of elements less than or equal to mid
9 for i in range(n):
10 # j = n - 1
11 while j >= 0 and matrix[i][j] > mid:
12 j -= 1
13 count += (j + 1)
14 # Adjust left or right boundary based on count
15 if count < k:
16 left = mid + 1
17 else:
18 right = mid
19 return right
小技巧
j = n - 1 这句话写在第7行比第10行要好。因为这里运用到了每列也是递增的这个规律,所以避免了重复运算
502. IPO¶
Suppose LeetCode will start its IPO soon. In order to sell a good price of its shares to Venture Capital, LeetCode would like to work on some projects to increase its capital before the IPO. Since it has limited resources, it can only finish at most k distinct projects before the IPO. Help LeetCode design the best way to maximize its total capital after finishing at most k distinct projects.
You are given n projects where the ith project has a pure profit profits[i] and a minimum capital of capital[i] is needed to start it.
Initially, you have w capital. When you finish a project, you will obtain its pure profit and the profit will be added to your total capital.
Pick a list of at most k distinct projects from given projects to maximize your final capital, and return the final maximized capital.
The answer is guaranteed to fit in a 32-bit signed integer.
Since you can choose at most 2 projects, you need to finish the project indexed 2 to get the maximum capital. Therefore, output the final maximized capital, which is 0 + 1 + 3 = 4.
1def findMaximizedCapital(self, k: int, w: int, profits: List[int], capital: List[int]) -> int:
2 choice = []
3 store = []
4 prof = 0
5 for i in range(len(capital)):
6 if capital[i] <= w:
7 heapq.heappush(choice, -profits[i])
8 else:
9 store.append((capital[i], profits[i]))
10 store.sort()
11 while choice and k > 0:
12 prof += -heapq.heappop(choice)
13 cap = w + prof
14 k -= 1
15 while store and store[0][0] <= cap:
16 heapq.heappush(choice, -store.pop(0)[1])
17 return w + prof
堆的思想。存一下就好,用max heap。每次pop出来一个最大的。然后符合标准的再push进去
位运算¶
我菜狗,暂时不会
数组中数字出现的次数 II¶
剑指 Offer 56 - II.
在一个数组 nums 中除一个数字只出现一次之外,其他数字都出现了三次。请找出那个只出现一次的数字。
数组中数字出现的次数¶
剑指 Offer 56 - I.
一个整型数组 nums 里除两个数字之外,其他数字都出现了两次。请写程序找出这两个只出现一次的数字。要求时间复杂度是O(n),空间复杂度是O(1)。
格雷编码¶
1def grayCode(self, n: int) -> List[int]:
2 res = ["0","1"]
3 if n == 0:
4 return [0]
5 for i in range(1,n):
6 temp0 = []
7 temp1 = []
8 for j in range(len(res)):
9 temp0.append("0"+res[j])
10 temp1.append("1"+res[::-1][j])
11 res = temp0 + temp1
12 result = [int(x,2) for x in res]
13 return result
我这样做不是位运算,是动态规划
解法的思想来自 https://leetcode-cn.com/problems/gray-code/solution/gray-code-jing-xiang-fan-she-fa-by-jyd/
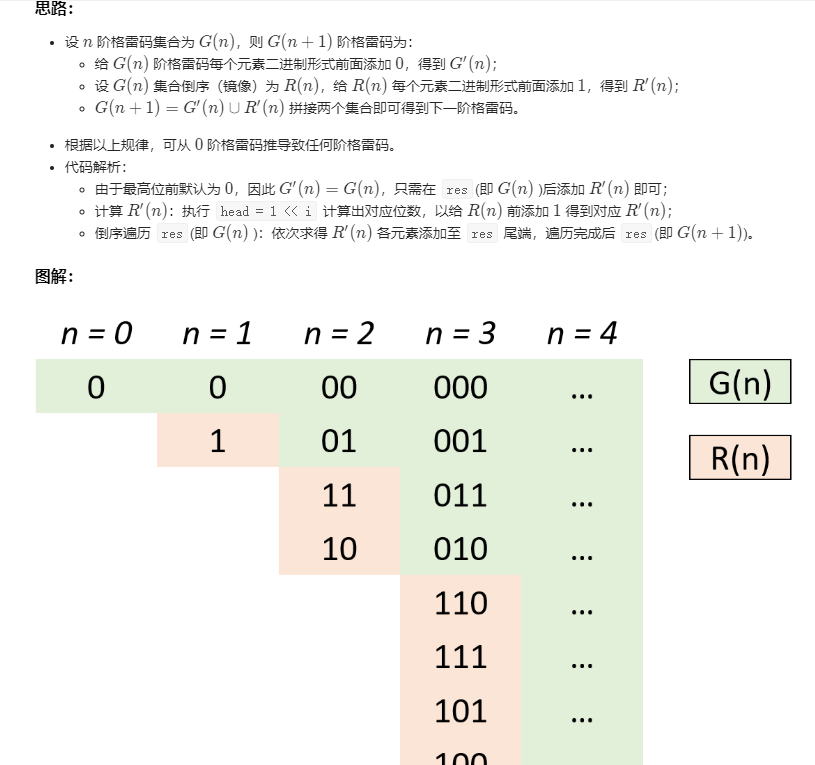
回溯/递归¶
思路模仿自 https://leetcode-cn.com/problems/permutations/solution/hui-su-suan-fa-xiang-jie-by-labuladong-2/
回溯模板
回溯模板¶
1result = []
2def backtrack(路径, 选择列表):
3 if 满足结束条件:
4 result.add(路径)
5 return
6
7 for 选择 in 选择列表:
8 做选择
9 backtrack(路径, 选择列表)
10 撤销选择
https://leetcode-cn.com/problems/combination-sum-ii/solution/hui-su-xi-lie-by-powcai/
leetcode 60. 第k个排列
组合总和¶
1def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
2 res, path = [], []
3 candidates.sort()
4 start = 0
5 def calculate(res,path,start):
6 for i in range(start,len(candidates)):
7 path.append(candidates[i])
8 if sum(path)==target:
9 res.append(path[:])
10 path.pop()
11 break
12 elif sum(path)>target:
13 path.pop()
14 break
15 calculate(res,path,i)
16 path.pop()
17 calculate(res,path,start)
18 return res
倒数第三行的path.pop()值得再好好思考!
用标准的回溯模板写出来:
1def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
2 res, path = [], []
3 candidates.sort()
4 start = 0
5 def calculate(res,path,start):
6 if sum(path)==target:
7 res.append(path[:])
8 return
9 for i in range(start,len(candidates)):
10 path.append(candidates[i])
11 if sum(path)>target:
12 path.pop()
13 break
14 calculate(res,path,i)
15 path.pop()
16 calculate(res,path,start)
17 return res
1def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
2 ans = []
3 def dfs(path, i, summ):
4 if summ == target:
5 ans.append(path[:])
6 return
7 for j in range(i, len(candidates)):
8 new_summ = summ + candidates[j]
9 if new_summ <= target:
10 dfs(path + [candidates[j]], j, new_summ)
11 dfs([], 0, 0)
12 return ans
组合总和 II¶
1def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:
2 res, path = [], []
3 candidates.sort()
4 def findit(res,path,start):
5 for i in range(start,len(candidates)):
6 if i>start and candidates[i]==candidates[i-1]:
7 continue
8 path.append(candidates[i])
9 total = sum(path)
10 if total==target:
11 res.append(path[:])
12 path.pop()
13 break
14 elif total > target:
15 path.pop()
16 break
17 findit(res,path,i+1)
18 path.pop()
19 findit(res,path,0)
20 return res
if i>start and candidates[i]==candidates[i-1]:这里要仔细思考
按照标准的回溯模板来写:
1def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:
2 res, path = [], []
3 candidates.sort()
4 def findit(res,path,start):
5 if sum(path)==target:
6 res.append(path[:])
7 return
8 for i in range(start,len(candidates)):
9 if i>start and candidates[i]==candidates[i-1]:
10 continue
11 path.append(candidates[i])
12 if sum(path) > target:
13 path.pop()
14 break
15 findit(res,path,i+1)
16 path.pop()
17 findit(res,path,0)
18 return res
全排列¶
1def permute(self, nums: List[int]) -> List[List[int]]:
2 res, path = [], []
3 def all_sort(res, path):
4 if len(path)==len(nums):
5 res.append(path[:])
6 return
7 for i in range(0,len(nums)):
8 if nums[i] not in path:
9 path.append(nums[i])
10 all_sort(res, path)
11 path.pop()
12 all_sort(res, path)
13 return res
或者:
1def permute(nums):
2 ans = []
3 def dfs(path, store):
4 nonlocal ans
5 print(path, store)
6 if len(path) == len(nums):
7 ans.append(path[:])
8 return
9 for i in range(len(store)):
10 dfs(path + [store[i]], store[:i] + store[i + 1:])
11 # dfs(path.append(store[i]), store[:i] + store[i + 1:])
12 dfs([], nums)
13 return ans
为什么这里要 dfs(path + [store[i]], store[:i] + store[i + 1:]) 而不是 dfs(path.append(store[i]), store[:i] + store[i + 1:])
因为path.append() 会改变append, 那在本次for循环里,后面的path都会带上前面append的内容了。甚至这样写都不行,:
for i in range(len(store)):
dfs(path.append(store[i]), store[:i] + store[i + 1:])
path.pop()
The bug in the code dfs(path.append(store[i]), store[:i] + store[i + 1:]) is because the append method returns None, and you’re passing that None value as the first argument to the dfs function.
In Python, the append method modifies the list in-place and returns None. So, when you call path.append(store[i]), it appends store[i] to the path list, but the expression itself evaluates to None.
重要
所以,append 操作只能单独做,不能在传参时候做,不然就是None!!!
全排列 II¶
1def permuteUnique(self, nums: List[int]) -> List[List[int]]:
2 res, path = [], []
3 nums.sort()
4 used = [0 for i in range(len(nums))]
5 def backtrack(res,path,used):
6 if len(path)==len(nums):
7 res.append(path[:])
8 return
9 for i in range(len(nums)):
10 if used[i] == 1:
11 continue
12 if i>0 and nums[i]==nums[i-1] and used[i-1]:
13 continue
14 path.append(nums[i])
15 used[i] = 1
16 backtrack(res,path,used)
17 path.pop()
18 used[i] = 0
19 backtrack(res,path,used)
20 return res
关键点
if used[i] == 1:
if i>0 and nums[i]==nums[i-1] and used[i-1]:
组合¶
1def combine(self, n: int, k: int) -> List[List[int]]:
2 nums = [x for x in range(1,n+1)]
3 res, path = [], []
4 def backtrack(res, path, start):
5 if len(path)==k:
6 res.append(path[:])
7 return
8 for i in range(start, len(nums)):
9 path.append(nums[i])
10 backtrack(res, path, i+1)
11 path.pop()
12 backtrack(res, path, 0)
13 return res
子集¶
1def subsets(self, nums: List[int]) -> List[List[int]]:
2 res, path = [], []
3 def backtrack(res, path, length, start):
4 if len(path)==length:
5 res.append(path[:])
6 return
7 for i in range(start,len(nums)):
8 path.append(nums[i])
9 backtrack(res, path, length, i+1)
10 path.pop()
11 for i in range(0,len(nums)+1):
12 backtrack(res, path, i, 0)
13 return res
思想是借鉴的上一题。不算很优秀的解法,因为重复点在于最后那个for循环,并没有用上上一次循环的结果
为什么官方的那个解答也是这么写的…….以后有时间再优化吧
子集 II¶
1def subsetsWithDup(self, nums: List[int]) -> List[List[int]]:
2 nums.sort()
3 res = []
4 def backtrack(path, res, start, length):
5 if len(path)==length:
6 res.append(path[:])
7 return
8 for i in range(start,len(nums)):
9 if i>start and nums[i]==nums[i-1]:
10 continue
11 path.append(nums[i])
12 backtrack(path, res, i+1, length)
13 path.pop()
14 for length in range(0,len(nums)+1):
15 path = []
16 backtrack(path, res, 0, length)
17 return res
单词搜索¶
1def exist(self, board: List[List[str]], word: str) -> bool:
2 directions = [(1,0),(-1,0),(0,1),(0,-1)]
3 used = [[0 for j in range(len(board[0]))] for i in range(len(board))]
4 def search(i,j,index):
5 if index==len(word)-1:
6 return board[i][j]==word[index]
7 if board[i][j]==word[index]:
8 used[i][j] = 1
9 for direct in directions:
10 new_i = i + direct[0]
11 new_j = j + direct[1]
12 if 0<=new_i<=len(board)-1 and 0<=new_j<=len(board[0])-1 and not used[new_i][new_j] and search(new_i,new_j,index+1):
13 return True
14 used[i][j] = 0
15 return False
16
17 for i in range(len(board)):
18 for j in range(len(board[0])):
19 if search(i,j,0):
20 return True
21 return False
都是模板和套路….:
1def exist(self, board: List[List[str]], word: str) -> bool:
2 ans = False
3 n, m = len(board), len(board[0])
4 def dfs(i, j, index):
5 nonlocal ans
6 if 0 <= i <= n - 1 and 0 <= j <= m - 1 and board[i][j] == word[index]:
7 index += 1
8 if index == len(word):
9 ans = True
10 return
11 for delta_i, delta_j in [(1, 0), (-1, 0), (0, 1), (0, -1)]:
12 board[i][j] = "#"
13 new_i, new_j = i + delta_i, j + delta_j
14 dfs(new_i, new_j, index)
15 board[i][j] = word[index - 1]
16 for i in range(n):
17 for j in range(m):
18 dfs(i, j, 0)
19 if ans is True:
20 return True
21 return False
或者用个set保存一下遍历过的路径:
1def exist(self, board: List[List[str]], word: str) -> bool:
2 ROWS, COLS = len(board), len(board[0])
3 path =set()
4 def dfs(r, c, i):
5 if i == len(word):
6 return True
7 if ( r<0 or c <0 or r>= ROWS or c>= COLS
8 or word[i] != board[r][c] or (r,c) in path ):
9 return False
10 path.add((r,c))
11 res = (dfs(r+1,c,i+1) or
12 dfs(r-1,c,i+1) or
13 dfs(r,c+1,i+1) or
14 dfs(r,c-1,i+1))
15 path.remove((r,c))
16 return res
17 for r in range(ROWS):
18 for c in range(COLS):
19 if dfs(r,c,0): return True
20 return False
对于此类问题,可以在前面加上一个次数检查,速度快很多。如果某个字符在word中出现次数大于board中的次数,则说明无法构成word,直接返回False:
1# check if the board even has the correct count of each character in word
2count = defaultdict(int)
3for row in board:
4 for c in row:
5 count[c] += 1
6
7for c in word:
8 count[c] -= 1
9 if count[c] < 0:
10 return False
51. N-Queens¶

卧槽这个解析说的太清楚了!!!
https://www.bilibili.com/video/BV1mY411D7f6/?vd_source=52a05014b8db18f0a2de12bb0c25da9b
1def solveNQueens(self, n: int) -> List[List[str]]:
2 ans = []
3 rows = [0] * n
4 def vaild(i, j):
5 for index in range(i):
6 col = rows[index]
7 if j - i == col - index:
8 return False
9 if j + i == col + index:
10 return False
11 return True
12
13 def dfs(i, choose):
14 if i == n:
15 temp = []
16 for num in rows:
17 temp.append("." * num + "Q" + "." * (n - 1 - num))
18 ans.append(temp)
19 return
20 for j in choose:
21 if vaild(i, j):
22 rows[i] = j
23 dfs(i + 1, choose - {j})
24 dfs(0, set([i for i in range(n)]))
25 return ans
这一段:
1if i == n:
2 temp = []
3 for num in rows:
4 temp.append("." * num + "Q" + "." * (n - 1 - num))
5 ans.append(temp)
还能写成:
if i == n:
ans.append(["." * num + "Q" + "." * (n - 1 - num) for num in rows])
为什么def dfs(i, choose)里面不需要nonlocal ans:
由于ans是一个列表(list),它是可变类型,因此在dfs函数内部可以直接修改它的值,不需要使用nonlocal。
对于不可变类型(如int、str、tuple等)的变量,在内部函数中无法直接修改其值,因为每次为它重新赋值时,实际上是创建了一个新的对象,而不是修改原有对象的值。
而对于可变类型(如list、dict、set等)的变量,在内部函数中是可以直接修改其值的,因为它们指向的是同一个对象的引用。
复习: 可变类型和不可变类型: https://knowledge-record.readthedocs.io/zh-cn/latest/python/python.html#id15
可变类型——list, dict, set
不可变类型——int, str, tuple
单词拆分¶
完全背包动态规划解法:
1def wordBreak(self, s: str, wordDict: List[str]) -> bool:
2 dp = [False] * (len(s))
3 wordset = set(wordDict)
4 for i in range(len(s)):
5 for j in range(i + 1, len(s) + 1):
6 if i == 0 and s[i:j] in wordset:
7 dp[j - 1] = True
8 elif dp[i - 1] and s[i:j] in wordset:
9 dp[j - 1] = True
10 return dp[-1]
dfs递归解法:
1def helper(i):
2 nonlocal flag
3 if flag or i == len(s):
4 flag = True
5 return True
6 if memory_no[i] == 0:
7 return False
8 for j in range(i + 1, len(s) + 1):
9 if s[i:j] in wordset:
10 if helper(j):
11 return True
12 memory_no[i] = 0
13 return False
14wordset = set(wordDict)
15flag = False
16memory_no = [1] * len(s)
17helper(0)
18return flag
这里本来可以很简单的递归,但是这种情况过不了。
所以需要加上记忆化模块,如果在某个index处是到不了的,则需要记下来。
请看下一题:
单词拆分 II (递归中非常重要的一点!强调¶
1def wordBreak(self, s: str, wordDict: List[str]) -> List[str]:
2
3 # 前几行处理特殊情况,但是除了lc上面的测试案例,一般不会这么无聊
4 # tmp = set("".join(wordDict))
5 # if any([i not in tmp for i in s]):
6 # return []
7
8 dp = [[' ']] + [['']] * len(s)
9 store = set(wordDict)
10 for i in range(len(s)):
11 for j in wordDict:
12 if i+1-len(j) >= 0 and j == s[i+1-len(j):i+1] and dp[i+1-len(j)] !=['']:
13 if dp[i + 1] == ['']:
14 dp[i + 1] = [x +' '+ j for x in dp[i + 1 - len(j)]]
15 else:
16 dp[i + 1] += [x +' '+ j for x in dp[i + 1 - len(j)]]
17 if dp[-1]==['']:
18 return []
19 else:
20 return [x.strip() for x in dp[-1]]
这里的话,跟上一题相比需要保存当前为True的结果。由于输出格式的问题,所以dp里面每个元素用[‘’]保存,第一个多一点空格,最后strip掉就好
递归解法。强调递归中非常重要的一点!!!!!
1def helper(path, i):
2 # 以i为开头开始计算
3 if i >= len(s):
4 ans.append(path)
5 return True
6 if memno[i] == 0:
7 return False
8 flag = False
9 for j in range(i + 1, len(s) + 1):
10 if s[i:j] in wordset:
11 if helper(path + [s[i:j]], j):
12 flag = True
13 if not flag:
14 memno[i] = 0
15 return False
16 return True
17memno = [1] * len(s)
18wordset = set(wordDict)
19ans = []
20helper([], 0)
21return [" ".join(cont) for cont in ans]
这一题相比于上一题,在递归的时候需要把path也保留下来。一开始我没有写递归函数中最下面的15、16行(return True 和 return False)。这会造成在多重递归的时候,最尾巴的递归由于到了s的终点,能够返回 True, 但是中间的递归却没有返回True或false给上一层 ,所以上一层没有接收到信号,就变成了默认的None
递归的时候,如果确定是返回状态,一定要在结尾处也返回状态!!
为运算表达式设计优先级/ 对表达式添加括号并求值¶
1def diffWaysToCompute(self, input: str) -> List[int]:
2 def helper(arr):
3 if arr.isdigit():
4 return [int(arr)]
5 ans = []
6 for i in range(len(arr)):
7 if arr[i] in ["+","-","*"]:
8 left = helper(arr[:i])
9 right = helper(arr[i+1:])
10 for x in left:
11 for y in right:
12 if arr[i] == "+":
13 ans.append(x + y)
14 elif arr[i] == "-":
15 ans.append(x - y)
16 else:
17 ans.append(x * y)
18 return ans
19 return helper(input)
思路:分治思想,分成两部分。遍历到一个符号的时候,可以递归得到左边的全部结果和右边的全部结果。然后看符号是什么,分别相加相减相乘。
394. Decode String¶
Given an encoded string, return its decoded string.
The encoding rule is: k[encoded_string], where the encoded_string inside the square brackets is being repeated exactly k times. Note that k is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc. Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, k. For example, there will not be input like 3a or 2[4].
The test cases are generated so that the length of the output will never exceed 105.
1def decodeString(self, s: str) -> str:
2 def bracket(i):
3 ans = ""
4 cnt = 0
5 if i > length - 1:
6 return ans, i
7 j = i
8 while j <= length - 1:
9 if s[j].isalpha():
10 ans += s[j]
11 j += 1
12 elif s[j].isdigit():
13 cnt = cnt * 10 + int(s[j])
14 j += 1
15 elif s[j] == "[":
16 next_ans, next_j = bracket(j + 1)
17 ans += cnt * next_ans
18 cnt = 0
19 j = next_j
20 elif s[j] == "]":
21 return ans, j + 1
22 return ans, j + 1
23 length = len(s)
24 return bracket(0)[0]
图¶
133. Clone Graph¶
Given a reference of a node in a connected undirected graph.
Return a deep copy (clone) of the graph.
Each node in the graph contains a value (int) and a list (List[Node]) of its neighbors.:
class Node {
public int val;
public List<Node> neighbors;
}
Test case format:
For simplicity, each node’s value is the same as the node’s index (1-indexed). For example, the first node with val == 1, the second node with val == 2, and so on. The graph is represented in the test case using an adjacency list.
An adjacency list is a collection of unordered lists used to represent a finite graph. Each list describes the set of neighbors of a node in the graph.
The given node will always be the first node with val = 1. You must return the copy of the given node as a reference to the cloned graph.
1class Solution:
2 def cloneGraph(self, node: Optional['Node']) -> Optional['Node']:
3 if not node:
4 return node
5 store = dict()
6 pending = [node]
7 while pending:
8 n = pending.pop(0)
9 if n not in store:
10 store[n] = Node(n.val, [])
11 for neb in n.neighbors:
12 if neb not in store:
13 store[neb] = Node(neb.val, [])
14 pending.append(neb)
15 store[n].neighbors.append(store[neb])
16 return store[node]
其实没有搞得太明白,看了解析的。BFS DFS都可以。 我觉得这里是利用了字典的内容可变性
399. Evaluate Division¶
You are given an array of variable pairs equations and an array of real numbers values, where equations[i] = [Ai, Bi] and values[i] represent the equation Ai / Bi = values[i]. Each Ai or Bi is a string that represents a single variable.
You are also given some queries, where queries[j] = [Cj, Dj] represents the jth query where you must find the answer for Cj / Dj = ?.
Return the answers to all queries. If a single answer cannot be determined, return -1.0.
Note: The input is always valid. You may assume that evaluating the queries will not result in division by zero and that there is no contradiction.
Note: The variables that do not occur in the list of equations are undefined, so the answer cannot be determined for them.
1def calcEquation(self, equations: List[List[str]], values: List[float], queries: List[List[str]]) -> List[float]:
2 graph = defaultdict(list)
3 # build graph
4 for i in range(len(values)):
5 front, back, val = equations[i][0], equations[i][1], values[i]
6 graph[front].append((back, val))
7 graph[back].append((front, 1/val))
8
9 # cal queries
10 ans = []
11 for front, back in queries:
12 if front not in graph or back not in graph:
13 ans.append(-1)
14 continue
15 temp = [(front, 1)]
16 used = set()
17 res = -1
18 while temp:
19 b, val = temp.pop(0)
20 if b == back:
21 res = val
22 break
23 if b in used:
24 continue
25 used.add(b)
26 for m, v in graph[b]:
27 if m not in used:
28 temp.append((m, v * val))
29 ans.append(res)
30 return ans
这道题很有意思。建议还是BFS更加直观一些。参考了解析https://leetcode.com/problems/evaluate-division/solutions/88275/python-fast-bfs-solution-with-detailed-explantion/
这里build graph和cal queries可以写成两个函数。这样:
1for m, v in graph[b]:
2if m not in used:
3 temp.append((m, v * val))
4# 可以加上 及时剪枝
5if m == back:
temp = [(front, 1)] 这里也很重要,因为要加一个自己和自己的。或者在生成图的时候加上也行
课程表¶
1def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
2 graph = defaultdict(list)
3 degree = defaultdict(int)
4 for f, s in prerequisites:
5 graph[s].append(f) # second to first
6 degree[f] += 1
7 qualified = [i for i in range(numCourses) if i not in degree]
8 for course in qualified:
9 if course not in graph:
10 continue
11 for c in graph[course]:
12 degree[c] -= 1
13 if degree[c] == 0:
14 qualified.append(c)
15 return len(qualified) == numCourses
# 参考了解析https://leetcode.cn/problems/course-schedule/solution/bao-mu-shi-ti-jie-shou-ba-shou-da-tong-tuo-bu-pai-/ # 使用拓扑的入度与出度
课程表 II¶
leetcode 210.
现在你总共有 numCourses 门课需要选,记为 0 到 numCourses - 1。给你一个数组 prerequisites ,其中 prerequisites[i] = [ai, bi] ,表示在选修课程 ai 前 必须 先选修 bi 。
例如,想要学习课程 0 ,你需要先完成课程 1 ,我们用一个匹配来表示:[0,1] 。
返回你为了学完所有课程所安排的学习顺序。可能会有多个正确的顺序,你只要返回 任意一种 就可以了。如果不可能完成所有课程,返回 一个空数组 。
1def findOrder(self, numCourses: int, prerequisites: List[List[int]]) -> List[int]:
2 graph = defaultdict(list)
3 degree = defaultdict(int)
4 for f, s in prerequisites:
5 graph[s].append(f)
6 degree[f] += 1
7 verified = [i for i in range(numCourses) if i not in degree]
8 for i in verified:
9 if i not in graph:
10 continue
11 for c in graph[i]:
12 degree[c] -= 1
13 if degree[c] == 0:
14 verified.append(c)
15 if len(verified) == numCourses:
16 return verified
17 return []
跟上面那题一模一样,最后改一下下
岛屿数量¶
1def dfs(self,grid,i,j):
2 grid[i][j]=0
3 row, col = len(grid), len(grid[0])
4 next_step = [(i+1,j),(i-1,j),(i,j+1),(i,j-1)]
5 for new_x, new_y in next_step:
6 if 0<=new_x<=row-1 and 0<=new_y<=col-1 and grid[new_x][new_y]=="1":
7 self.dfs(grid,new_x,new_y)
8
9def numIslands(self, grid: List[List[str]]) -> int:
10 ans = 0
11 for i in range(len(grid)):
12 for j in range(len(grid[0])):
13 if grid[i][j]=="1":
14 ans +=1
15 self.dfs(grid,i,j)
16 return ans
思想就是:遍历,然后DFS。注意DFS的时候不要越界:
0<=new_x<=row-1 and 0<=new_y<=col-1
这个写法很不错:
next_step = [(i+1,j),(i-1,j),(i,j+1),(i,j-1)]
for new_x, new_y in next_step:
909. Snakes and Ladders¶

1def snakesAndLadders(self, board: List[List[int]]) -> int:
2 n = len(board)
3 def d2ij(d):
4 i = n - 1 - ((d - 1) // n)
5 j = (d - 1) % n if ((d - 1) // n) % 2 == 0 else n - 1 - (d - 1) % n
6 return i, j
7 visit = set()
8 bfs = [(1, 0)]
9 for d, step in bfs:
10 for gap in range(1, 7):
11 new_d = d + gap
12 i, j = d2ij(new_d)
13 if board[i][j] != -1:
14 new_d = board[i][j]
15 if new_d == n ** 2:
16 return step + 1
17 if new_d > n ** 2:
18 break
19 if new_d not in visit:
20 visit.add(new_d)
21 bfs.append((new_d, step + 1))
22 return -1
注意
if new_d == n ** 2:
return step + 1
if new_d > n ** 2:
break
这一段一定要写到完全判断完new_d之后
def d2ij(d) 这个函数不好写呢….可以先想想如果是0,0在开头会是怎样,那么现在上下颠倒会是怎样?从1开始会是怎样?
433. Minimum Genetic Mutation¶
A gene string can be represented by an 8-character long string, with choices from ‘A’, ‘C’, ‘G’, and ‘T’.
Suppose we need to investigate a mutation from a gene string startGene to a gene string endGene where one mutation is defined as one single character changed in the gene string.
For example, “AACCGGTT” –> “AACCGGTA” is one mutation. There is also a gene bank bank that records all the valid gene mutations. A gene must be in bank to make it a valid gene string.
Given the two gene strings startGene and endGene and the gene bank bank, return the minimum number of mutations needed to mutate from startGene to endGene. If there is no such a mutation, return -1.
Note that the starting point is assumed to be valid, so it might not be included in the bank.
1def minMutation(self, startGene: str, endGene: str, bank: List[str]) -> int:
2 if startGene == endGene:
3 return 0
4 sub_list = ["A", "C", "G", "T"]
5 bank = set(bank)
6 if startGene in bank:
7 bank.remove(startGene)
8 if endGene not in bank:
9 return -1
10 bfs = [(startGene, 0)]
11 for gene, step in bfs:
12 for i in range(8):
13 for sub in sub_list:
14 temp = gene[:i] + sub + gene[i + 1:]
15 if temp == endGene:
16 return step + 1
17 if temp in bank:
18 bfs.append((temp, step + 1))
19 bank.remove(temp)
20 return -1
127. Word Ladder¶
A transformation sequence from word beginWord to word endWord using a dictionary wordList is a sequence of words beginWord -> s1 -> s2 -> … -> sk such that:
1def ladderLength(self, beginWord: str, endWord: str, wordList: List[str]) -> int:
2 wordList = set(wordList)
3 if beginWord in wordList:
4 wordList.remove(beginWord)
5 if endWord not in wordList:
6 return 0
7 bfs = [(beginWord, 1)]
8 length = len(beginWord)
9 for word, step in bfs:
10 for i in range(length):
11 for j in range(26):
12 temp = word[:i] + chr(ord("a") + j) + word[i + 1:]
13 if temp == endWord:
14 return step + 1
15 if temp in wordList:
16 bfs.append((temp, step + 1))
17 wordList.remove(temp)
18 return 0
或者也可以两头都出发的来找:
1def ladderLength(self, beginWord: str, endWord: str, wordList: List[str]) -> int:
2 wordSet = set(wordList)
3 if endWord not in wordSet:
4 return 0
5 beginSet = {beginWord}
6 endSet = {endWord}
7 distance = 1
8 while beginSet and endSet:
9 wordSet -= beginSet
10 distance += 1
11 newSet = set()
12 for word in beginSet:
13 for i in range(len(word)):
14 left = word[:i]
15 right = word[i + 1:]
16 for c in string.ascii_lowercase:
17 new_word = left + c + right
18 if new_word in wordSet:
19 if new_word in endSet:
20 return distance
21 newSet.add(new_word)
22 if len(beginSet) > len(endSet): #swap to lowest set
23 beginSet = endSet
24 endSet = newSet
25 else: beginSet = newSet
26 return 0
310. Minimum Height Trees¶
A tree is an undirected graph in which any two vertices are connected by exactly one path. In other words, any connected graph without simple cycles is a tree.
Given a tree of n nodes labelled from 0 to n - 1, and an array of n - 1 edges where edges[i] = [ai, bi] indicates that there is an undirected edge between the two nodes ai and bi in the tree, you can choose any node of the tree as the root. When you select a node x as the root, the result tree has height h. Among all possible rooted trees, those with minimum height (i.e. min(h)) are called minimum height trees (MHTs).
Return a list of all MHTs’ root labels. You can return the answer in any order.
The height of a rooted tree is the number of edges on the longest downward path between the root and a leaf.
1def findMinHeightTrees(self, n: int, edges: List[List[int]]) -> List[int]:
2 store = []
3 if n == 1:
4 return [0]
5 for _ in range(n):
6 store.append(set())
7 for i, j in edges:
8 store[i].add(j)
9 store[j].add(i)
10 leaves = [i for i in range(n) if len(store[i]) == 1]
11 while n > 2:
12 n -= len(leaves)
13 next_level = []
14 for i in leaves:
15 j = store[i].pop()
16 store[j].remove(i)
17 if len(store[j]) == 1:
18 next_level.append(j)
19 leaves = next_level
20 return leaves
这个参考了https://leetcode.com/problems/minimum-height-trees/solutions/76055/share-some-thoughts/
从叶子节点开始,一步步的缩减。最后的中心只能是1-2个节点。因为如果3个,那么需要排除边上两个找中间的。 有点类似于物体的质心一定在一个点上,可以恰好是那个点,也可以两点在一条直线上,但一定不会是三个点
下面这道是类似的题
834. Sum of Distances in Tree¶
There is an undirected connected tree with n nodes labeled from 0 to n - 1 and n - 1 edges.
You are given the integer n and the array edges where edges[i] = [ai, bi] indicates that there is an edge between nodes ai and bi in the tree.
Return an array answer of length n where answer[i] is the sum of the distances between the ith node in the tree and all other nodes.
我还不会
??????
743. Network Delay Time¶
You are given a network of n nodes, labeled from 1 to n. You are also given times, a list of travel times as directed edges times[i] = (ui, vi, wi), where ui is the source node, vi is the target node, and wi is the time it takes for a signal to travel from source to target.
We will send a signal from a given node k. Return the minimum time it takes for all the n nodes to receive the signal. If it is impossible for all the n nodes to receive the signal, return -1.
1def networkDelayTime(self, times: List[List[int]], n: int, k: int) -> int:
2 store = defaultdict(list)
3 for u, v, w in times:
4 store[u].append([v, w])
5 path = [float(inf)] * n
6 path[k - 1] = 0
7 pending = [(0, k)]
8 while pending:
9 w, node = heapq.heappop(pending)
10 for new_v, new_w in store[node]:
11 if new_w + w < path[new_v - 1]:
12 path[new_v - 1] = new_w + w
13 heapq.heappush(pending, (new_w + w, new_v))
14 return max(path) if float('inf') not in path else -1
Dijkstra 算法: https://www.youtube.com/watch?v=uyNJxsH16nc
但其实就简单的dfs或者bfs也能过:
1def networkDelayTime(self, times: List[List[int]], n: int, k: int) -> int:
2 store = defaultdict(list)
3 for u, v, w in times:
4 store[u].append([v, w])
5 path = [float(inf)] * n
6 path[k - 1] = 0
7 pending = [(0, k)]
8 for w, node in pending:
9 for new_v, new_w in store[node]:
10 if new_w + w < path[new_v - 1]:
11 path[new_v - 1] = new_w + w
12 pending.append((new_w + w, new_v))
13 return max(path) if float('inf') not in path else -1
个人浅显的理解,Dijkstra算法相对于dfs或者bfs的优点在于,能提前终止:
Dijkstra 可以在找到目标节点后立即停止,而 BFS 变体需要探索所有可能的路径。因为w, node = heapq.heappop(pending) 这里的值就是固定的了,不会再修改了,贪心算法
请看下一题
1631. Path With Minimum Effort¶
You are a hiker preparing for an upcoming hike. You are given heights, a 2D array of size rows x columns, where heights[row][col] represents the height of cell (row, col). You are situated in the top-left cell, (0, 0), and you hope to travel to the bottom-right cell, (rows-1, columns-1) (i.e., 0-indexed). You can move up, down, left, or right, and you wish to find a route that requires the minimum effort.
A route’s effort is the maximum absolute difference in heights between two consecutive cells of the route.
Return the minimum effort required to travel from the top-left cell to the bottom-right cell.
1def minimumEffortPath(self, heights: List[List[int]]) -> int:
2 m, n = len(heights), len(heights[0])
3 directions = [(1, 0), (-1, 0), (0, 1), (0, -1)]
4 path = [[float(inf)] * n for _ in range(m)]
5 path[0][0] = 0
6 pending = [(0, 0, 0)]
7 while pending:
8 step, row, col = heapq.heappop(pending)
9 if row == m - 1 and col == n - 1:
10 return step
11 for x, y in directions:
12 if 0 <= row + x <= m - 1 and 0 <= col + y <= n - 1:
13 new_step = max(step, abs(heights[row][col] - heights[row + x][col + y]))
14 if new_step < path[row + x][col + y]:
15 path[row + x][col + y] = new_step
16 heapq.heappush(pending, (new_step, row + x, col + y))
17 return path[-1][-1]
这里用Dijkstra的好处就在于第9,10行。如果从pending里面pop出来的是最后一格就能直接return
Trie¶
前缀树
字典嵌套字典。然后记得在插入的时候,到单词的结尾需要添加一个结束的标志
208. Implement Trie (Prefix Tree)¶
A trie (pronounced as “try”) or prefix tree is a tree data structure used to efficiently store and retrieve keys in a dataset of strings. There are various applications of this data structure, such as autocomplete and spellchecker.
Implement the Trie class:
1class Trie:
2 def __init__(self):
3 self.root = dict()
4
5 def insert(self, word: str) -> None:
6 store = self.root
7 for cha in word:
8 if cha not in store:
9 store[cha] = dict()
10 store = store[cha]
11 store['end'] = True
12
13 def search(self, word: str) -> bool:
14 store = self.root
15 for cha in word:
16 if cha in store:
17 store = store[cha]
18 else:
19 return False
20 if 'end' in store:
21 return True
22 return False
23
24 def startsWith(self, prefix: str) -> bool:
25 store = self.root
26 for cha in prefix:
27 if cha in store:
28 store = store[cha]
29 else:
30 return False
31 return True
211. Design Add and Search Words Data Structure¶
Design a data structure that supports adding new words and finding if a string matches any previously added string.
Implement the WordDictionary class:
1class WordDictionary:
2
3 def __init__(self):
4 self.root = dict()
5
6 def addWord(self, word: str) -> None:
7 store = self.root
8 for cha in word:
9 if cha not in store:
10 store[cha] = dict()
11 store = store[cha]
12 store['#'] = []
13
14 def search(self, word: str) -> bool:
15 temp = [self.root]
16 for cha in word:
17 next_level = []
18 for store in temp:
19 if cha == ".":
20 for content in store:
21 next_level.append(store[content])
22 else:
23 if cha in store:
24 next_level.append(store[cha])
25 temp = next_level
26 for store in temp:
27 if '#' in store:
28 return True
29 return False
python小知识点运用¶
最大数–sort的key=cmp_to_key写法¶
leetcode 179.
给定一组非负整数 nums,重新排列每个数的顺序(每个数不可拆分)使之组成一个最大的整数。
注意:输出结果可能非常大,所以你需要返回一个字符串而不是整数。
1def largestNumber(self, nums: List[int]) -> str:
2 def fun(x, y):
3 if x + y > y + x:
4 return 1
5 return -1
6 nums = list(map(str, nums))
7 nums.sort(key=cmp_to_key(fun), reverse=True)
8 return "0" if nums[0] == "0" else "".join(nums)
这里考察的是sort的key=cmp_to_key写法。这样可以自定义如何来排序,如何比较两个值。
如果只是一个值,比如 nums = [(“aa”, 1), (“bb”, 3), (“cc”, 2)]可以
nums.sort(key=lambda x: x[1]) 按照括号第二位进行排列
字符串的最大公因子—辗转相除法¶
leetcode 1071.
对于字符串 s 和 t,只有在 s = t + … + t(t 自身连接 1 次或多次)时,我们才认定 “t 能除尽 s”。
给定两个字符串 str1 和 str2 。返回 最长字符串 x,要求满足 x 能除尽 str1 且 x 能除尽 str2 。
1def gcdOfStrings(self, str1: str, str2: str) -> str:
2 if str1 + str2 != str2 + str1:
3 return ""
4 def gcd(a, b):
5 while b != 0:
6 a, b = b, a % b
7 return a
8 k = gcd(len(str1), len(str2))
9 return str1[:k]
这里判断两个字符串是否有“最大公约数”是通过str1 + str2 == str2 + str1。这个有些意想不到。直观上符合认知 假设str1和str2的最大公约数为x,比如分别由 xxx 和 xxxxx 组成,那str1 + str2 == str2 + str1
这里还使用到了辗转相除法
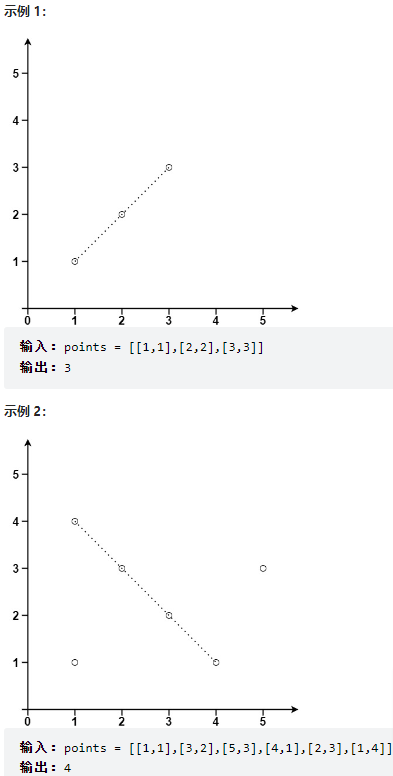
计数质数¶
1def countPrimes(self, n: int) -> int:
2 res = [2]
3 if n<=2:
4 return 0
5 for i in range(2,n):
6 for j in range(len(res)):
7 if i%res[j]==0:
8 break
9 else:
10 res.append(i)
11 return len(res)
会有点超时
这种厄拉多塞筛法可以:
1def countPrimes(self, n: int) -> int:
2 # 0, 1 不是质数,第一个质数从2开始
3 prime = [0,0] + [1]*(n-2)
4 for i in range(2,len(prime)):
5 if prime[i] ==1:
6 prime[i**2::i] = [0] * len(prime[i**2::i])
7 return sum(prime)
8 # 如果是看谁是质数,就
9 # p = [i for i,v in enumerate(prime) if v == 1]
10 # return p
非常规题¶
概率问题见 machine_learning 概率论¶
概率问题见 machine_learning 概率论
用小随机数生成大随机数¶
比如 用一个能生成[1, 5]的随机数生成器X,构建一个能生成[1, 10]的随机数生成器Y
或者用一个6面的筛子给15个人分月饼。
这种的就是编码就好了。
比如用一个6面的筛子给15个人分月饼:
两个数位分别可以实现6*6=36种情况,36/15 = 2 ……6 所以每两种情况编码一位。如果摇到分配不到的空值就重新摇
超多数字,从中找出只出现过一次的数字¶

海量数据处理面试题¶
https://www.cnblogs.com/v-July-v/archive/2012/03/22/2413055.html
多看看!
基本思路是: 大数据所以分而治之,然后hash table用的很多,为了统计一些数量,比如统计每个词出现的次数
KMP¶
KMP算法易懂版https://www.bilibili.com/video/BV1jb411V78H?from=search&seid=4251637190584004649 这个视频基本上从原理上讲懂了
1def KMP(s, p):
2 """
3 s为主串
4 p为模式串
5 如果t里有p,返回打头下标
6 """
7 nex = getNext(p)
8 i = 0
9 j = 0 # 分别是s和p的指针
10 while i < len(s) and j < len(p):
11 if j == -1 or s[i] == p[j]: # j==-1是由于j=next[j]产生
12 i += 1
13 j += 1
14 else:
15 j = nex[j]
16
17 if j == len(p): # j走到了末尾,说明匹配到了
18 return i - j
19 else:
20 return -1
21
22
23def getNext(p):
24 """
25 p为模式串
26 返回next数组,即部分匹配表
27 """
28 nex = [0] * (len(p) + 1)
29 nex[0] = -1
30 i = 0
31 j = -1
32 while i < len(p):
33 if j == -1 or p[i] == p[j]:
34 i += 1
35 j += 1
36 nex[i] = j # 这是最大的不同:记录next[i]
37 else:
38 j = nex[j]
39 return nex
40
41s="abxababcabyabc"
42p="abyab"
43KMP(s, p)
代码贴一下。不是太懂。下面那个getNext(p)只被调用了一次。生成的是一个 list,长度比substring大1,开头是-1.然后似乎是在找重合的前缀后缀。
用pytorch手写逻辑回归¶
假设已经准备好数据集了
1import torch
2import torch.nn as nn
3import torchvision
4import torchvision.transforms as transforms
5import torch.nn.functional as F
6
7# 准备数据集和参数
8train_dataset = xxxx
9test_dataset = xxxx
10
11train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
12test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)
13
14# 核心函数
15class LR(nn.Module):
16 def __init__(self,input_dims,output_dims):
17 super().__init__()
18 self.linear=nn.Linear(input_dims, output_dims,bias=True)
19 def forward(self,x):
20 x=self.linear(x)
21 return x
22
23model = LR(input_size, num_classes)
24criterion = nn.CrossEntropyLoss()
25optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
26
27for epoch in range(num_epochs):
28 for i,(images,labels)in enumerate(train_loader):
29
30 # forward
31 y_pred = model(images)
32 loss = criterion(y_pred,labels)
33
34 # backward()
35 optimizer.zero_grad()
36 loss.backward()
37 optimizer.step()
38
39# 验证和测试
40with torch.no_grad():
41 correct = 0
42 total = 0
43 for images, labels in test_loader:
44 images = images.reshape(-1, 28*28)
45 outputs = model(images)
46 _ , predicted = torch.max(outputs.data, 1)
47 total += labels.size(0)
48 correct += (predicted == labels).sum()
49
50# 保存模型
51torch.save(LR_model.state_dict(), 'model.ckpt')
lc 题型归类/模板¶
二分查找¶
模板¶
迭代
1def binary_search(target, array):
2 l = 0
3 r = len(array)-1
4 while l<=r:
5 mid = (l+r)//2
6 if array[mid]==target:
7 return mid
8 elif array[mid]<target:
9 l = mid + 1
10 else:
11 r = mid – 1
12 return False
递归
1def binary(stand, left, right, potions):
2 mid = (left + right) // 2
3 if left >= right:
4 return left
5 if potions[mid] >= stand:
6 return binary(stand, left, mid, potions)
7 else:
8 return binary(stand, mid + 1, right, potions)
注意点¶
- 看见O(log n)的基本就是二分
- //2操作是向下取整。所以涉及谁+1的时候,都是不包括mid==target的情况下left = mid+1,另一边是 包括 mid==target的情况下 right = mid,保留mid==target的可能性
例题¶
变体¶
数组中存在旋转: 需要用中间去和左边or右边比较,判断旋转在哪边。 如:leetcode 33.
如果存在重复元素:
找左边找右边:
1def get_left(nums,target):
2 l, r = 0, len(nums)-1
3 while l <= r:
4 mid = (l + r)//2
5 if nums[mid]>=target:
6 r = mid -1
7 elif nums[mid] < target:
8 l = mid + 1
9 return l
10
11def get_right(nums,target):
12 l, r = 0, len(nums)-1
13 while l <= r:
14 mid = (l + r)//2
15 if nums[mid] <= target:
16 l = mid + 1
17 elif nums[mid] > target:
18 r = mid - 1
19 return r
需要维护一个队列/单调栈¶
好像有一个规律
如果是要找递增,那么就维护一个递减的栈。因为这样才能更新并且留下最大值
如果是找递减,那么就维护一个递增的栈。
然后栈中被pop完后最后一个符合规则的,计算和这次的跨度
可以这么想:在运算的途中,已经获得当前的数要开始pop,直到放到倒数第二个,你希望当前在栈最里面的数是大还是小
注意点¶
- 哨兵:heights = [0] + heights + [0] 相当于前后加了两个“哨兵”
- 算跨度的左边,用stack中上一个。 w = i - stack[-1] - 1 而不是刚刚pop出来的。防止[2, 1, 2]的情况发生,不知道左边界是哪里,因为1会把第一个2给pop掉
例题¶
柱状图中最大的矩形 leetcode 84.
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。求在该柱状图中,能够勾勒出来的矩形的最大面积。
- def largestRectangleArea(self, heights: List[int]) -> int:
ans = heights[0] queue = [] heights = [0] + heights + [0] # 哨兵 for i in range(len(heights)):
- while queue and heights[i] < heights[queue[-1]]:
- h = heights[queue.pop()] w = i - queue[-1] - 1 # 算跨度用stack中的最后一个 ans = max(ans, h * w)
queue.append(i)
return ans
滑动窗口¶
模板¶
备注
这篇解析写的很好,总结了滑动窗口的全部题目。 https://leetcode.cn/problems/permutation-in-string/solution/by-flix-ix7f/
窗口定长,和窗口不定长度是有两种模板的。前面基本是一样的,把demand字典给统计好,有多少个字符串need统计好
但是在遍历的时候:
定长的时候如果big[r]不在demand中,不能直接continue,因为当窗口是此时这样覆盖的时候,big[l]也有可能在demand里面的,是需要对demand[big[l]] 做加减判断的
不定长的时候,可以continue,因为左边是固定的,还会保留在之前的位置,而不是依赖于右边去做计算
定长的左边index是确定的,记得l = r - lenp 这里要特别注意这里不需要l = r - lenp + 1,因为是右边左边都要动,此时处理的是左边开始滑动时刻的情况
不定长的时候,while need <= 0: 再对左边滑出的元素做demand和need的判断
例题¶
最小覆盖子串 leetcode 76.
1def minWindow(self, s: str, t: str) -> str:
2 lens = len(s)
3 lent = len(t)
4 if lent > lens:
5 return ""
6 ans = s + "#"
7 l = 0
8 demand = dict()
9 for cha in t:
10 demand[cha] = demand.get(cha, 0) + 1
11 need = lent
12 for r in range(lens):
13 if s[r] not in demand:
14 continue
15 if demand[s[r]] > 0:
16 need -= 1
17 demand[s[r]] -= 1
18
19 while need <= 0:
20 if len(ans) > r - l + 1:
21 ans = s[l: r + 1]
22 if s[l] in demand:
23 if demand[s[l]] >= 0:
24 need += 1
25 demand[s[l]] += 1
26 l += 1
27 return ans if len(ans) <= lens else ""
二叉树¶
前中后序遍历 递归¶
前序遍历:
1def preorder(node):
2 if not node:
3 return []
4 res.append(node.val)
5 preorder(node.left)
6 preorder(node.right)
中序遍历:
1def inorder(node):
2 if not node:
3 return []
4 inorder(node.left)
5 res.append(node.val)
6 inorder(node.right)
后序遍历:
1def postorder(node):
2 if not node:
3 return []
4 postorder(node.left)
5 postorder(node.right)
6 res.append(node.val)
前中后序遍历 迭代¶
前序遍历:
1def preorder(node):
2 res, stack = [], []
3 while stack or node:
4 while node:
5 res.append(node.val)
6 stack.append(node)
7 node = node.left
8 node = stack.pop()
9 node = node.right
10 return res
中序遍历:
1def inorder(node):
2 res, stack = [], []
3 while stack or node:
4 while node:
5 stack.append(node)
6 node = node.left
7 node = stack.pop()
8 res.append(node.val)
9 node = node.right
10 return res
后序遍历:
1def postorder(node):
2 res, stack = [], []
3 while stack or node:
4 while node:
5 res.append(node.val)
6 stack.append(node)
7 node = node.right
8 node = stack.pop()
9 node = node.left
10 return res
11res = postorder(node)[::-1]
12# 后序遍历是 左右中,然后我们使用了stack,所以录入的时候是左右中,(先进后出),然后对结果[::-1] 取逆序就好了。
13# [::-1]这个操作对 string和list 都适用的
大佬方法,学习一下
1class TreeNode:
2 def __init__(self, val=0, left=None, right=None):
3 self.val = val
4 self.left = left
5 self.right = right
6
7def LRN(root):
8 s = []
9 t = root
10 r = None # 记录上次访问过的节点
11
12 # 当t指针为空,而且堆栈也为空的时候遍历就结束了
13 while t or s:
14 # 每次当t不为空的时候就默认把t压入堆栈
15 if t:
16 s.append(t)
17 t = t.left
18 else:
19 t = s[-1]
20 if t.right and r != t.right:
21 # 该节点的右孩子不空,而且上一个访问的不是右孩子(证明这是从左孩子回溯过来的)
22 t = t.right
23 else:
24 # 该节点的右孩子为空,或者右孩子已经访问过了
25 t = s.pop()
26 print(t.val) # 遍历节点
27 r = t
28 t = None # 防止t被压入堆栈,所以要置空
29
30def NLR(root):
31 s = []
32 t = root
33
34 # 当t指针为空,而且堆栈也为空的时候遍历就结束了
35 while t or s:
36 # 每次当t不为空的时候就默认把t压入堆栈
37 if t:
38 print(t.val) # 遍历节点
39 s.append(t)
40 t = t.left
41 else:
42 t = s.pop()
43 t = t.right
44
45def LNR(root):
46 s = []
47 t = root
48
49 # 当t指针为空,而且堆栈也为空的时候遍历就结束了
50 while t or s:
51 # 每次当t不为空的时候就默认把t压入堆栈
52 if t:
53 s.append(t)
54 t = t.left
55 else:
56 t = s.pop()
57 print(t.val) # 遍历节点
58 t = t.right
层次遍历¶
1def levelorder(node):
2 cur_level, res = [node], []
3 while cur_level:
4 temp = []
5 next_level = []
6 for node in cur_level:
7 temp.append(node.val)
8 if node.left:
9 next_level.append(node.left)
10 if node.right:
11 next_level.append(node.right)
12 res.append(temp)
13 cur_level = next_level
14 return res
二叉搜索树 Binary Search Tree¶
Binary Search Tree的性质
1、对于 BST 的每一个节点 node,左子树节点的值都比 node 的值要小,右子树节点的值都比 node 的值大。
2、对于 BST 的每一个节点 node,它的左侧子树和右侧子树都是 BST。
因此二叉搜索树的中序遍历,是一个递增的序列. 这个性质能解决绝大部分的题目。而且很多题目不需要用list保存全部的值,只需要一个变量保存上一个就行
动态规划¶
前缀和¶
和为 K 的子数组 leetcode 560.
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的连续子数组的个数 。
子数组是数组中元素的连续非空序列。
1def subarraySum(self, nums: List[int], k: int) -> int:
2 ans = 0
3 store = {0:1}
4 temp = 0
5 for num in nums:
6 temp += num
7 if temp - k in store:
8 ans += store[temp - k]
9 store[temp] = store.get(temp, 0) + 1
10 return ans
11 # 这道题看了解析的。前缀和+类似2sum的解法真牛啊!
01背包¶
假设有一组物品,w的list是他们的weight,v的list是他们的value,tar是背包的重量。求能带上的最大价值
1w = [2,2,6,5,4]
2v = [6,3,5,4,6]
3tar = 10
4
5# i 是是否用物品
6# j 是背包的重量
7temp = [[0 for _ in range(tar+1)] for _ in range(len(w)+1)]
8for i in range(1,len(w)+1):
9 for j in range(1,tar+1):
10 if j < w[i-1]:
11 temp[i][j] = temp[i-1][j]
12 else:
13 temp[i][j] = max(temp[i-1][j-w[i-1]]+v[i-1],temp[i-1][j])
编辑距离¶
1def minDistance(self, word1: str, word2: str) -> int:
2 if not word1:
3 return len(word2)
4 if not word2:
5 return len(word1)
6 len1 = len(word1)
7 len2 = len(word2)
8 dp = [[0] * (len2 + 1) for _ in range(len1 + 1)]
9 for i in range(len2 + 1):
10 dp[0][i] = i
11 for i in range(len1 + 1):
12 dp[i][0] = i
13 for i in range(1, len1 + 1):
14 for j in range(1, len2 + 1):
15 if word1[i - 1] == word2[j - 1]:
16 dp[i][j] = dp[i - 1][j - 1]
17 else:
18 dp[i][j] = 1 + min(dp[i - 1][j - 1], dp[i][j - 1], dp[i - 1][j])
19 return dp[-1][-1]
这里 dp = [[0] * (len2 + 1) for _ in range(len1 + 1)] 和 for i in range(len2 + 1):dp[0][i] = i 这几行要搞清楚到底是 len1还是len2!!!!
对“dp[i-1][j-1] 表示替换操作,dp[i-1][j] 表示删除操作,dp[i][j-1] 表示插入操作。”的补充理解:
区间问题¶
合并区间¶
1def merge(self, intervals: List[List[int]]) -> List[List[int]]:
2 intervals.sort()
3 length = len(intervals)
4 ans = []
5 last_s, last_e = intervals[0][0], intervals[0][1]
6 for i in range(1, length):
7 s, e = intervals[i][0], intervals[i][1]
8 if s <= last_e:
9 last_s = min(last_s, s)
10 last_e = max(last_e, e)
11 else:
12 ans.append([last_s, last_e])
13 last_s, last_e = s, e
14 ans.append([last_s, last_e])
15 return ans
只要明白一件事就好了,先排序(sort以后先按第一个排序,再按第二个排序)。排序后的列表,如果说新判断的区间,左边的区间都比上一个的右区间大,那么一定不重合
矩阵/二维数组¶
四种翻转方法¶
注意看下i和j的范围:
1# 上下对称
2def up_down_symmetry(matrix):
3 n = len(matrix)
4 for i in range(n // 2):
5 for j in range(n):
6 matrix[i][j], matrix[n-i-1][j] = matrix[n-i-1][j], matrix[i][j]
7
8# 左右对称
9def left_right_symmetry(matrix):
10 n = len(matrix)
11 for i in range(n):
12 for j in range(n // 2):
13 matrix[i][j], matrix[i][n-j-1] = matrix[i][n-j-1], matrix[i][j]
14
15# 主对角线对称
16def main_diag_symmetry(matrix):
17 n = len(matrix)
18 for i in range(n - 1):
19 for j in range(i + 1, n):
20 matrix[i][j], matrix[j][i] = matrix[j][i], matrix[i][j]
21
22# 副对角线对称
23def subdiag_symmetry(matrix):
24 n = len(matrix)
25 for i in range(n - 1):
26 for j in range(n - i - 1):
27 matrix[i][j], matrix[n-j-1][n-i-1] = matrix[n-j-1][n-i-1], matrix[i][j]
链表¶
前置学习内容¶
https://www.youtube.com/watch?v=0czlvlqg5xw
这个视频说的很好。链表的题目其实不复杂。基本上就是 **双指针**(快慢指针or前后指针)或者递归. 而且链表只能前进不能后退,是缺点也是优点,简化了很多思路,导致基本上都需要用双指针来解决
有这样一些小技巧:
dummy = ListNode(0, head) **虚拟头节点**是真的好用
实在不行就 **需要保存的地方**就设置一个变量,然后充分利用python的同时交换的特性,大力出奇迹
找个纸和笔 画画图
例题¶
反转链表 leetcode 206./ 剑指 Offer 24.
定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。
示例:
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
双指针方法一,这个需要当成模板背下来!!!
1def reverseList(self, head):
2 """
3 :type head: ListNode
4 :rtype: ListNode
5 """
6 pre = None
7 cur = head
8 while cur:
9 # 记录当前节点的下一个节点
10 tmp = cur.next
11 # 然后将当前节点指向pre
12 cur.next = pre
13 # pre和cur节点都前进一位
14 pre = cur
15 cur = tmp
16 return pre
递归recursion
1def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:
2 if not head:
3 return
4 def helper(cur, pre):
5 if not cur:
6 return pre
7 res = helper(cur.next, cur)
8 cur.next = pre
9 return res
10 return helper(head, None)
这个递归比较难理解。但其实我们应该从后往前看。 假设是12345。这里的res通过层层往下,最后会固定在5这里。我们本身想返回的也就是5这个头。 然后在每一层里面,做的事情就是把后面指向前面.第7行的这个代码其实是阻止我们先反转顺序,而是让我们先找到头。然后再一层层的反转顺序
堆¶
Python默认实现的是最小堆。如果是最大堆的话,取个负号就行。但是记得最后输出的时候也要再负回来
回溯/递归¶
回溯模板¶
1result = []
2def backtrack(路径, 选择列表):
3 if 满足结束条件:
4 result.add(路径)
5 return
6
7 for 选择 in 选择列表:
8 做选择
9 backtrack(路径, 选择列表)
10 撤销选择
例题¶
1def permute(self, nums: List[int]) -> List[List[int]]:
2 res, path = [], []
3 def all_sort(res, path):
4 if len(path)==len(nums):
5 res.append(path[:])
6 return
7 for i in range(0,len(nums)):
8 if nums[i] not in path:
9 path.append(nums[i])
10 all_sort(res, path)
11 path.pop()
12 all_sort(res, path)
13 return res
或者:
1def permute(nums):
2 ans = []
3 def dfs(path, store):
4 nonlocal ans
5 print(path, store)
6 if len(path) == len(nums):
7 ans.append(path[:])
8 return
9 for i in range(len(store)):
10 dfs(path + [store[i]], store[:i] + store[i + 1:])
11 # dfs(path.append(store[i]), store[:i] + store[i + 1:])
12 dfs([], nums)
13 return ans
为什么这里要 dfs(path + [store[i]], store[:i] + store[i + 1:]) 而不是 dfs(path.append(store[i]), store[:i] + store[i + 1:])
因为path.append() 会改变append, 那在本次for循环里,后面的path都会带上前面append的内容了。甚至这样写都不行,:
for i in range(len(store)):
dfs(path.append(store[i]), store[:i] + store[i + 1:])
path.pop()
The bug in the code dfs(path.append(store[i]), store[:i] + store[i + 1:]) is because the append method returns None, and you’re passing that None value as the first argument to the dfs function.
In Python, the append method modifies the list in-place and returns None. So, when you call path.append(store[i]), it appends store[i] to the path list, but the expression itself evaluates to None.
重要
所以,append 操作只能单独做,不能在传参时候做,不然就是None!!!
图¶
课程表¶
1def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
2 graph = defaultdict(list)
3 degree = defaultdict(int)
4 for f, s in prerequisites:
5 graph[s].append(f) # second to first
6 degree[f] += 1
7 qualified = [i for i in range(numCourses) if i not in degree]
8 for course in qualified:
9 if course not in graph:
10 continue
11 for c in graph[course]:
12 degree[c] -= 1
13 if degree[c] == 0:
14 qualified.append(c)
15 return len(qualified) == numCourses
# 参考了解析https://leetcode.cn/problems/course-schedule/solution/bao-mu-shi-ti-jie-shou-ba-shou-da-tong-tuo-bu-pai-/ # 使用拓扑的入度与出度