一些零散记录¶
一些学习资料¶
李航 统计学习方法
台湾大学 林轩田 机器学习基石 进阶
深度学习 台湾大学 李宏毅
深度学习 CV NLP:斯坦福 CS224 斯坦福 CS231
机器学习、深度学习都有 莫烦 python。 非常入门但是讲的很好
西瓜书
一个做的很好的GitHub网站,里面总结了面试题 https://github.com/DarLiner/Algorithm_Interview_Notes-Chinese
【爆肝上传!清华大佬终于把困扰我大学四年的【计算机操作系统】讲的如此通俗易懂-哔哩哔哩】https://b23.tv/JYbL8G
一些易忘的小代码¶
生成a到z,判断是否是数字,判断是否是字母¶
生成a到z:
num2char = dict()
for i in range(26):
num2char[i] = chr(ord("a")+i)
其中,ord是ordinal(序数)的缩写,chr是character(字符)的缩写
string.isdigit() 判断是否是数字 # 但是”-10”这个会是False str.isdigit() 可以判断正数,但是无法判断负数。也没有什么好方法,除非 try int except 或者先判断第一个符号-
string.isalpha() 判断是否是字母
string..isalnum() 判断是否是数字或字母
defaultdict¶
defaultdict这个很好用:
counter = defaultdict(int)
counter[s[r]] += 1
用来代替 counter = dict()
这里的初始值设置还可以是 int, str, list, set等等—分别对应得到0, “”, [], set()
dict.get¶
numdict[num] = numdict.get(num, 0) + 1
lambda¶
匿名函数
g = lambda x, y: x + y print(g(2, 3))
将lambda函数作为参数传递给其他函数。
sort¶
intvs = sorted(intervals, key = lambda x: x[0]) 这个老是忘记
[[-100, 100], [-90, -80], [-20, 0], [1, 10]]
如果我想满足:1.把左端点小的放前面 2.左端点相同的情况下右端点小的放前面。
则需要两次sort排序。而且别忘了,这个和excel的很像,我需要先以右端点排一次,再排左端点:
inters = sorted(sorted(intervals, key = lambda x: x[1]), key = lambda x: x[0])
或者是:
inters = sorted(intervals, key = lambda x: (x[0], x[1]))
这样直观一些。重要性 先x[0] 后x[1]
如果想体现reverse甚至可以:
inters = sorted(intervals, key = lambda x: (x[0], -x[1]))
cmp_to_key 可以自定义排序的比较方式
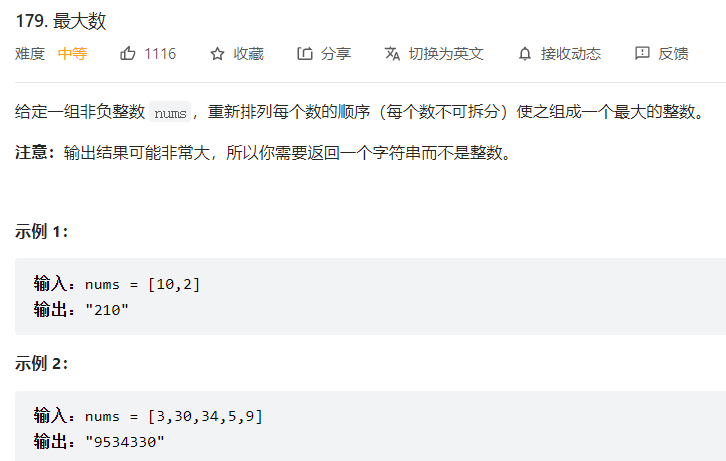
比如这里,可以用 cmp_to_key来定义,两个值是通过字符串比大小来判断大小的:
1def largestNumber(self, nums: List[int]) -> str:
2 def fun(x, y):
3 if x + y > y + x:
4 return 1
5 return -1
6 nums = list(map(str, nums))
7 nums.sort(key=cmp_to_key(fun), reverse=True)
8 return "0" if nums[0] == "0" else "".join(nums)
sort 和 sorted 区别
1s = [1,2,3,1,4,6]
2如果想进行排序的话
3a = sorted(s) 需要再找个变量来承接
4或者
5s.sort() 原地排序
sort()属于永久性排列,直接改变该list; sorted属于暂时性排列,会产生一个新的序列。
re正则¶
???待总结
enumerate¶
这样可以同时获取index和内容:
seq = [‘one’, ‘two’, ‘three’] for index, element in enumerate(seq):
print index, element

map¶
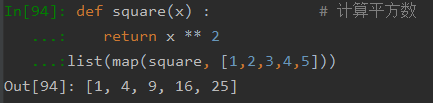
作用:括号里前面是函数,后面是作用的数据集
python2里面是直接返回列表,python3里面是返回返回迭代器,list一下就好
我们在笔试题的时候也是这样做的
a = list(map(int,input().strip().split()))
list(map(int, xxx )) 就能把之前的 [‘1’,’3’,234] 或者 ‘11213’ 变成 int
tuple元组: list不能当字典里的key的时候¶
比如这一题

1def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
2 store = defaultdict(list)
3 for word in strs:
4 count = [0] * 26
5 for cha in word:
6 count[ord(cha) - ord("a")] += 1
7 # str_count = ""
8 # for i in range(26):
9 # if count[i] != 0:
10 # str_count += chr(i + ord("a")) + str(count[i])
11 store[tuple(count)].append(word) # 直接使用tuple
12 return list(store.values())
关于tuple元组的一些小知识点
- 元组内部的元素不能修改
- 但我们可以对元组进行连接组合,如下实例:
1tup1 = (12, 34.56)
2tup2 = ('abc', 'xyz')
3
4# 以下修改元组元素操作是非法的。
5# tup1[0] = 100
6
7# 创建一个新的元组
8tup3 = tup1 + tup2
- 元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组
- 元组生成
1tup1 = ('physics', 'chemistry', 1997, 2000)
2tup2 = (1, 2, 3, 4, 5, 6, 7 )
3aa = (1, "222", "bbbb")
4aa = 1, "222", "bbbb"
5tup1 = (50,) # 元组中只包含一个元素时,需要在元素后面添加逗号
6aa = tuple([1, "222", "aaa"]) # list可以转化为元组,这样就能用在字典的key中
- 元组可以使用下标索引来访问元组中的值
- tuple元组、set、list可以互相转换.这样set和list变成tuple后就能放到字典里面做key
1bb = set()
2bb.add(1)
3bb.add(222)
4print(bb)
5aa = tuple(bb)
6print(aa)
7print(list(aa))
8cc = set(aa)
9print(cc)
stack栈、queue队列、heap堆¶
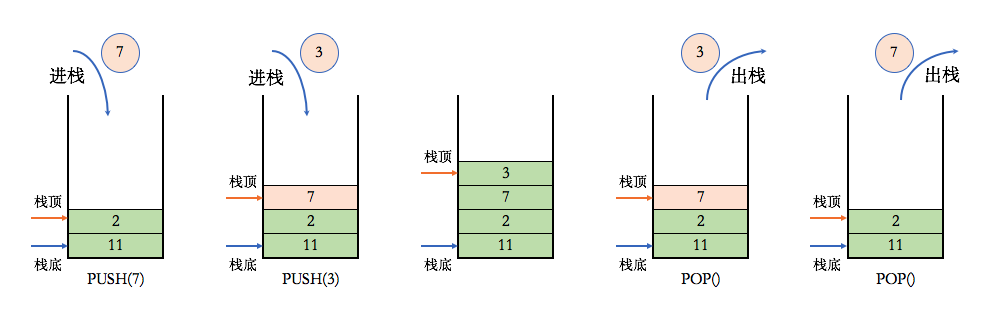
stack 栈
栈可以想象成AK47的弹夹,上子弹的时候一个个从上往下一个个压进去,发射的时候从上面一个个弹出。先进后出: FILO(First In Last Out)的原则存储数据。
常用的几个名词:栈顶(top), 栈底(bottom), 进栈(push), 出栈(pop)。栈中的每个元素称为一个frame。
<table border=”1” class=”docutils”> <thead> <tr> <th></th> </tr> </thead> <tbody> <tr> <td></td> </tr> </tbody> </table>
queue队列
queue队列可以想象成一个排队的队伍。队列队列,后来的得排队,先到先得
先进先出: (FIFO, First-In-First-Out) 的原则存储数据。
<table border=”1” class=”docutils”> <thead> <tr> <th></th> </tr> </thead> <tbody> <tr> <td></td> </tr> </tbody> </table>
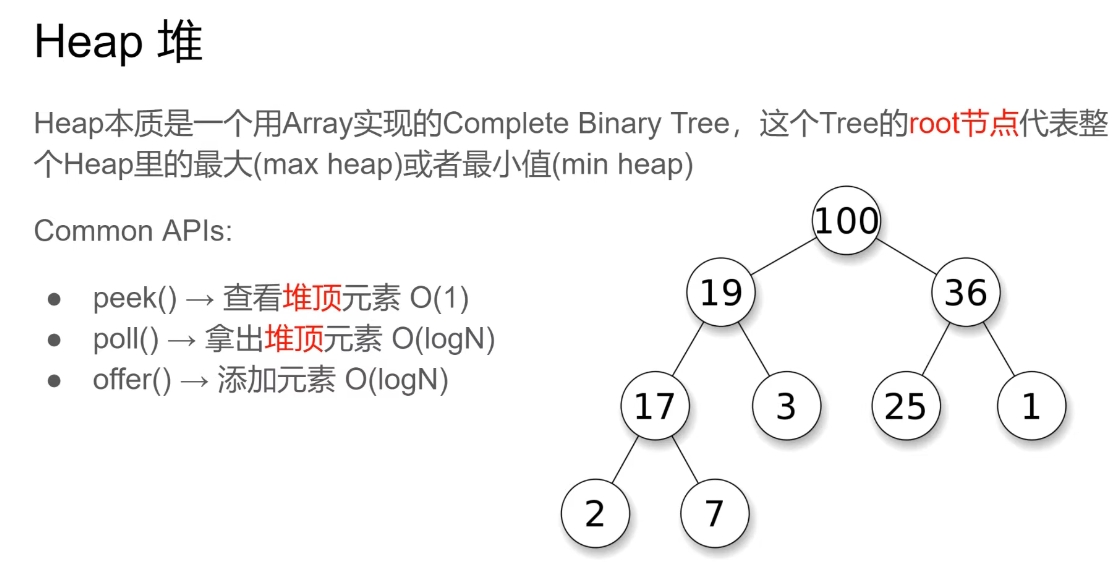
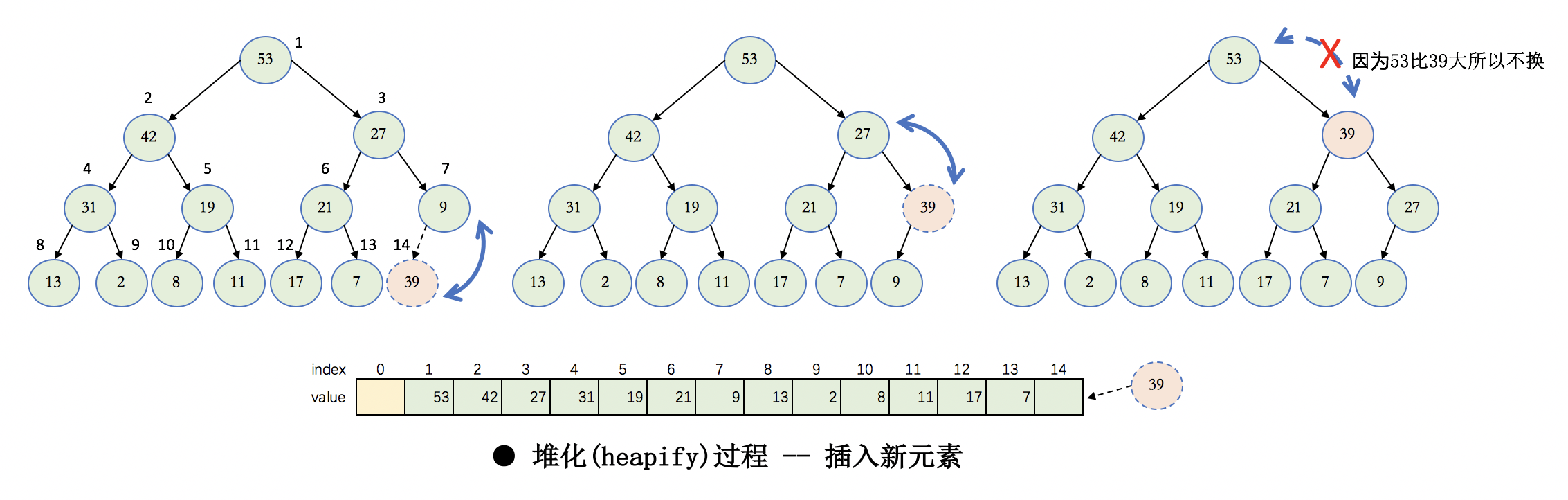
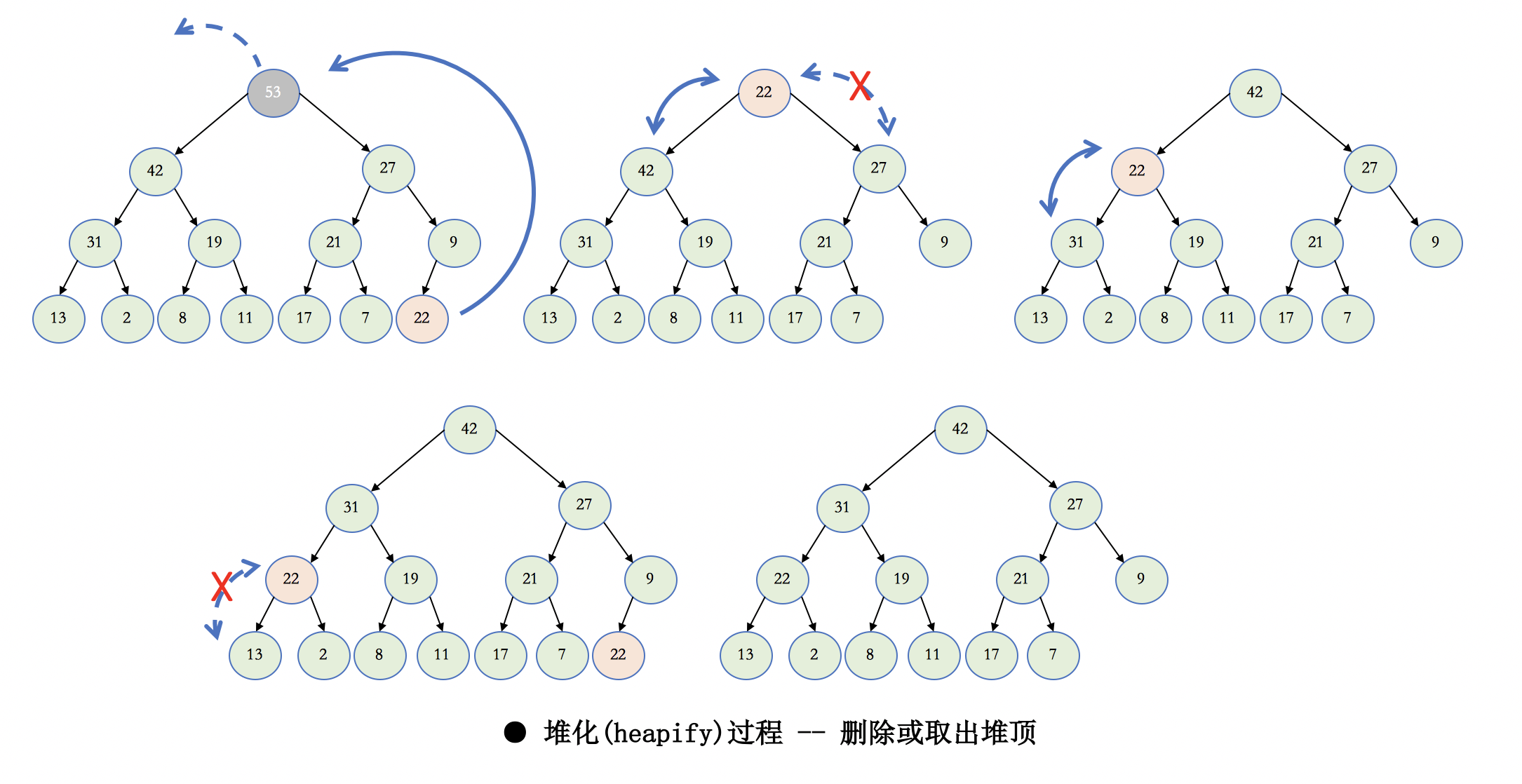
heap堆
堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
·堆中某个节点的值总是不大于或不小于其父节点的值;
·堆总是一棵完全二叉树。(从上到下,从左到右都是满的。除了最后一层有空的,而且还得是右边空)
*arg与**kwargs参数的用法¶
https://www.cnblogs.com/xujiu/p/8352635.html
*arg表示任意多个无名参数,类型为tuple;**kwargs表示关键字参数,为dict
any / all¶
元素除了是 0、空、FALSE 外都算 TRUE
any() :如果全为空,0,False,则返回False;如果不全为空,则返回True。
all() :如果全不为空,则返回True;否则返回False。
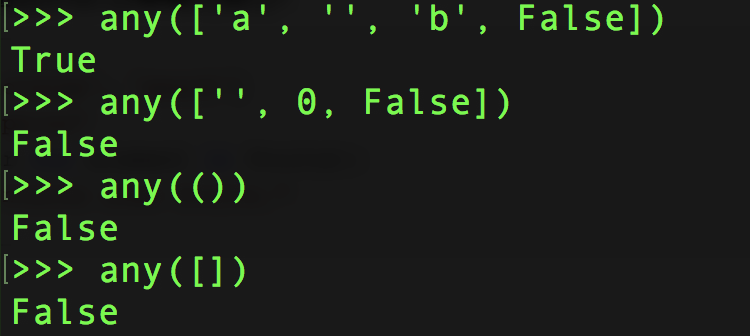
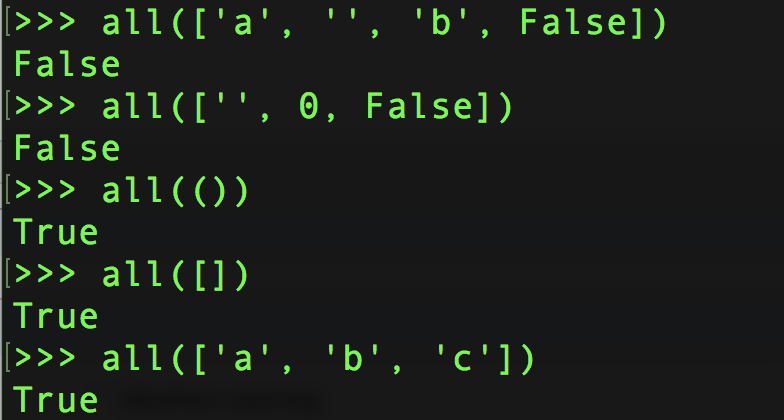
emmmmmm, () 和 [] 这里有点奇怪…. 但基本上 any 就是逻辑中or,all就是逻辑中 and


零碎¶
ReadtheDocs、Sphinx、rst文件¶
【文档】使用Sphinx + reST编写文档 https://www.cnblogs.com/zzqcn/p/5096876.html#_label7
如何用ReadtheDocs、Sphinx快速搭建写书环境 https://www.jianshu.com/p/78e9e1b8553a
.rst文件规则!!!! 这个是rst文件的语法!!! https://golden-note.readthedocs.io/zh/latest/sphinx/rst.html
tmux的使用¶
tmux new -s session-name 新建会话
tmux ls或ctrl+b s 查看目前有开启的会话
tmux a -t session-name 接入session-name这个会话
ctrl+b d或tmux detach 临时断开会话
tmux kill-session -t 1 关闭会话
窗口操作 | Ctrl+b PgUp/PgDn/ 查看页面之前的输出,按q退出
Linux中查看进程状态信息¶
哈希表的原理¶
利用哈希函数映射,构造出一个键值对。(查找的时候直接根据key去计算储存的位置 洛)
生成器和迭代器¶
https://www.jianshu.com/p/dcc4c1af63c7
http://www.techweb.com.cn/cloud/2020-07-27/2798448.shtml
生成器:iter() 和 next()
迭代器: yield
省内存
Python垃圾回收¶
当发生以下四种情况的时候,该对象的引用计数器+1
与上述情况相对应,当发生以下四种情况时,该对象的引用计数器-1
当指向该对象的内存的引用计数器为0的时候,该内存将会被Python虚拟机销毁
还有一些补充机制
详解可变、不可变数据类型+引用、深|浅拷贝¶
可变类型——list, dict, set
不可变类型——int, str, tuple
tuple元组、set、list可以互相转换.这样set和list变成tuple后就能放到字典里面做key
python 常用的 string format 形式¶
linux 操作系统一些命令¶
按 b 键就会往回(back)一页显示,而且还有搜寻字串的功能 。more命令从前向后读取文件,因此在启动时就加载整个文件。 | • less:工具也是对文件或其它输出进行分页显示的工具,应该说是Linux正统查看文件内容的工具,功能极其强大。less 的用法比起 more 更加的有弹性。 在 more 的时候,我们并没有办法向前面翻, 只能往后面看,但若使用了 less 时,就可以使用 [pageup] [pagedown] 等按键的功能来往前往后翻看文件, 更容易用来查看一个文件的内容!除此之外,在 less 里头可以拥有更多的搜索功能,不止可以向下搜,也可以向上搜。 | • grep:文本过滤,模糊查找
为某一个文件在另外一个位置建立一个同步的链接.当我们需要在不同的目录,用到相同的文件时,我们不需要在每一个需要要的目录下都放一个必须相同的文件, 我们只要在某个固定的目录,放上该文件,然后在 其它的目录下用ln命令链接(link)它就可以,不必重复的占用磁盘空间。 | • type: 查看命令的类型 | • file: 确定文件类型 如果文件系统确定成功,则输出文件类型,输出的文件类型如下:text:文件中只有ASCII码字符,可以将字符终端显示文件内容。executable:文件可以运行。data:其他类型文件,此类文件一般是二进制文件或不能再字符终端上直接显示的文件 | • stat: 查看文件属性 可以显示文件的一些详细信息!!
find / -name “*.so.2” 找当前目录下后缀是so.2的文件 grep -r 需要查询的文字 目录 。这个是能看文件内容的,查看哪个文件内容里面有xxx文字。后面还可以–color。-r是递归
eg:
1#新建文本
2touch a.txt #默认权限-rw-rw-r--
3
4#预览文本
5cat a.txt ,从第一行开始
6tac a.txt #从最后一行开始
7nl a.txt #带行号
8more a.txt #分页,从前往后
9less a.txt #分页,从后往前
10head a.txt #只看头几行
11less a.txt #只看最后几行
12
13echo "hello" > a.txt #覆盖文件
14echo "hello" >> a.txt #写入文件
pytorch,DDP(DistributedDataParallel)¶
本来设计主要是为了多机多卡使用,但是单机上也能用
DistributedDataParallel 比DataParallel 快很多,据说能快三倍以上。原因是每个卡都是主卡,…这个具体再看下。
除此之外,还能用 horovod或者 apex 但是都要单独配置
先贴一段自己能跑通的代码。
1# import 阶段要多import 这些
2import torch.distributed as dist
3from torch.nn.parallel import DistributedDataParallel
4from torch.utils.data.distributed import DistributedSampler
5from torch.utils.data import DataLoader
6
7# dataloader 这里要用sampler
8sampler = torch.utils.data.distributed.DistributedSampler(dataset)
9dataloader = data.DataLoader(dataset=dataset,
10 collate_fn=TextCollate(dataset),
11 pin_memory=True,
12 batch_size=batch_size,
13 num_workers=num_workers,
14 shuffle=False,
15 sampler=sampler)
16
17# 初始化这里最恶心
18torch.distributed.init_process_group(backend='nccl')
19# local_rank = args.local_rank
20# torch.cuda.set_device(local_rank) 这样设置好像也可
21local_rank = torch.distributed.get_rank() # 这样最好
22torch.cuda.set_device(local_rank)
23device = torch.device("cuda", local_rank)
24model.to(device)
25model = model.cuda()
26model = torch.nn.parallel.DistributedDataParallel(model,
27 device_ids=[local_rank],
28 output_device=local_rank,find_unused_parameters=True)
29
30# 如果用到了parser.add_argument,这句话也是需要的
31parser.add_argument('--local_rank', default=-1, type=int)
32
33# 要用shell来跑,按照如下的来写。jupyter的话要另外在代码里面设置别的内容。--nproc_per_node=2因为有两张卡
34python -m torch.distributed.launch --nproc_per_node=2 train_distribute.py
几个坑的地方要特别注意:¶
https://zhuanlan.zhihu.com/p/97115875 这篇文章讨论到了shuffle 的结果依赖 g.manual_seed(self.epoch) 中的 self.epoch,跑完后再试试
mp的问题,上次拍过棉洲老哥的照片,代码。传到这个GitHub里了,但是没有贴到这上面来。 knowledge_record/docs/_static/python/
多看看官方文档。 好像pytorch1.4还是多少之后就自带apex了
排序问题¶
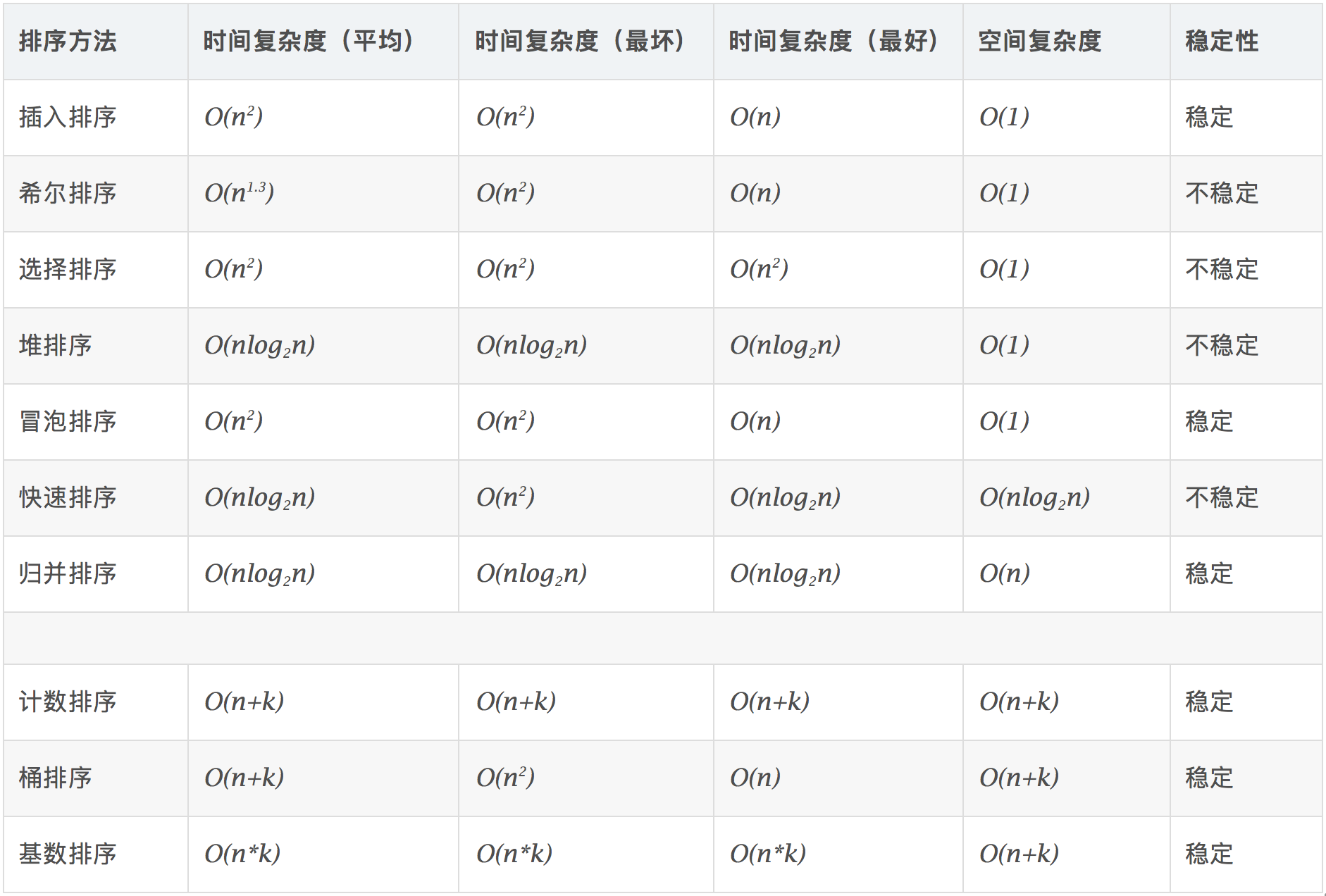
一些排序算法的简单解释
选择排序¶
每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完。
希尔排序¶
先取一个小于n的证书d1作为第一个增量,把文件的全部记录分成d1组。所有距离为d1的倍数的记录放在同一组中。先在各组内进行直接插入排序,然后取第二个增量d2<d1重复上述的分组和排序,直到所取的增量dt=1, 即所有记录放在同一组中进行直接插入排序为止。该方法实际上是一种分组插入方法。
归并排序¶
归并排序是把序列递归地分成短序列,递归出口是短序列只有1个元素(认为直接有序)或者2个序列(1次比较和交换), 然后把各个有序的段序列合并成一个有序的长序列,不断合并直到原序列全部排好序。
堆排序(Heap Sort)¶
堆排序是一树形选择排序,在排序过程中,将R[1..N]看成是一颗完全二叉树的顺序存储结构,利用完全二叉树中双亲结点和孩子结点之间的内在关系来选择最小的元素。
基数排序¶
(1)根据数据项个位上的值,把所有的数据项分为10组;
(2)然后对这10组数据重新排列:把所有以0结尾的数据排在最前面,然后是结尾是1的数据项,照此顺序直到以9结尾的数据,这个步骤称为第一趟子排序;
(3)在第二趟子排序中,再次把所有的数据项分为10组,但是这一次是根据数据项十位上的值来分组的。这次分组不能改变先前的排序顺序。也就是说,第二趟排序之后,从每一组数据项的内部来看,数据项的顺序保持不变;
(4)然后再把10组数据项重新合并,排在最前面的是十位上为0的数据项,然后是10位为1的数据项,如此排序直到十位上为9的数据项。
(5)对剩余位重复这个过程,如果某些数据项的位数少于其他数据项,那么认为它们的高位为0。
快速排序¶
快排的代码在 leetcode那一页有
稳定性¶
所谓稳定性是指待排序的序列中有两元素相等,排序之后它们的先后顺序不变.假如为A1,A2.它们的索引分别为1,2.则排序之后A1,A2的索引仍然是1和2.
稳定也可以理解为一切皆在掌握中,元素的位置处在你在控制中.而不稳定算法有时就有点碰运气,随机的成分.当两元素相等时它们的位置在排序后可能仍然相同.但也可能不同.是未可知的.
稳定性的用处¶
我们平时自己在使用排序算法时用的测试数据就是简单的一些数值本身.没有任何关联信息.这在实际应用中一般没太多用处.实际应该中肯定是排序的数值关联到了其他信息,比如数据库中一个表的主键排序,主键是有关联到其他信息. 另外比如对英语字母排序,英语字母的数值关联到了字母这个有意义的信息.
初始状态的影响¶
topK 问题¶
坑死了…被很多面试官问过这个问题…这里总结一下。
(1)排序。再取前k个
(2)局部排序。冒泡。冒k个泡,就得到TopK
(3)堆/动态规划。 堆的方法要再看看。 适合处理海量数据 堆 时间复杂度 O(NlogK) 、空间复杂度 O(K)
(4)快速排序改编。 !! 重要
从数组S中随机取出一个元素,使用一次partition函数,找到该元素对应的位置p,同时将原始数组分成了两个部分S1和S2,显然S1中的元素都小于等于该数,S2中的元素都大于等于该数;此时有三种情况:
1class Solution(object):
2 def partition(self,arr,k,low,high):
3 i,j = low,high
4 p = arr[low]
5 while i<j:
6 while i<j and arr[j]>=p:
7 j-=1
8 while i<j and arr[i]<=p:
9 i+=1
10 if i<j:
11 arr[i],arr[j] = arr[j],arr[i]
12 arr[low],arr[i] = arr[i],p
13 if i==low+k-1:
14 return arr[low:low+k]
15 elif i>low+k-1:
16 return self.partition(arr,k,low,i-1)
17 else:
18 return arr[low:i+1]+self.partition(arr,k-(i+1-low),i+1,high)
19 def getLeastNumbers(self, arr, k):
20 """
21 :type arr: List[int]
22 :type k: int
23 :rtype: List[int]
24 """
25 if k==0:
26 return []
27 if len(arr)<=k:
28 return arr
29 return self.partition(arr,k,0,len(arr)-1)
时间空间复杂度?? 和K有关吗?
找到数组中第k大的元素 (leetcode215. 数组中的第K个最大元素) 跟上面那个有点区别。上面的是topk小,这是第k大
1def parti(arr, low, high):
2 tmp = arr[low]
3 while low<high:
4 while low<high and arr[high]>=tmp:
5 high-=1
6 arr[low] = arr[high]
7 while low<high and arr[low]<=tmp:
8 low +=1
9 if low<high:
10 arr[high] = arr[low]
11 arr[low] = tmp
12 return low
13
14if not arr or k<=0 or len(arr)<k:
15 return []
16
17low, high, n = 0, len(arr)-1, len(arr)
18index = parti(arr,low, high)
19
20while index != (n-k):
21 if index>(n-k):
22 high = index-1
23 index=parti(arr, low, high)
24 else:
25 low = index+1
26 index=parti(arr, low, high)
27return arr[n-k]
python下划线¶

一些经典网络代码实现¶
pandas和numpy¶
职业发展¶
【职场】技术人如何做好述职汇报- 轩脉刃de刀光剑影 https://www.youtube.com/watch?v=Wis0PUaqXtU
个税申报¶
投资理财¶
面试总结¶
面试-基础¶
总结一下面试教训¶
之前什么都不懂….把该犯的错都犯了一遍,这里记录一下深刻的血泪教训….
这哪里像是个正常人做的事啊…….愚蠢到家了
1.要刷题….真的要刷题,如果一点都没准备,二分查找和树的遍历都写不出,别人凭什么相信你能力强。。。给你机会你不中用啊!
2.不要在什么面试经验都没有的时候从大公司开始投
3.一定要看自己和这个岗位是不是匹配,不用冲着因为是内推所以投个擦边的
4.最后面试结束的时候面试官问你,还有没有什么想问的?
现在这个阶段的面试可以问的问题:
还是要等别人说完话,略微停个一秒钟半秒钟的再说话…别着急,别紧张,别抢话
在面试官介绍完自己之后,简单的问别人一个问题。比如,你们最常用的语言是什么,目前的数据量是多少,目前的用户量是多少,是否有时效性要求等等。这样礼貌一些
我发现有时候,需要区分别人是在问我总体的业务,还是具体某一个项目。比如说,如果是总体的业务我应该怎么介绍?
更重要的是,要听清并且理解别人到底在问什么….别人在问impact,回答最终结果就完了,不要老是按照自己之前编好的故事和逻辑在巴拉巴拉的说
看下别人是招SDE 还是MLE,要对应好了说,如果别人不是做ML model的,就不要一直在巴拉巴拉的说model
介绍任何一个项目的时候都要说结果!!! 不管是技术介绍还是BQ,biggest challenge,tight deadline
小公司 和 fintech公司会问。为什么选择小公司,为什么选择fintech
对面试官的问题:
5.多面,多练手,才不会那么紧张
6.自我介绍和项目介绍一定要准备好。之前的一分钟自我介绍太短了,导致后面很被动。
7.要很有自信,就像是在和老板讲故事一样,自己说出来的话都没底气,别人怎么会相信你。 不要战战兢兢的像是小学的时候老师抽查你背课文一样,就当跟同学之间的聊天和探讨吹牛皮。
8.面试要经常总结和做面经,不然会在一个坑里一次又一次的跌倒。
9.多去和师兄同学讨论,请教。不要闭门造车
10.当然要去猜面试官到底想问什么,但是不要说出来!!!不要显得自己很聪明的 “啊我猜您想问的呢是XXXX”
这次北美找工作的经验¶
简历很重要,不然都过不了第一关:叠名词和技术名词,为了过机器筛选关、关键词加粗。一页实在写不下就扩展成两页吧…
地址要和公司post的地址匹配上
岗位一出来就要投
适当的为自己加码:senior,证书
BQ问题多准备一下
做一些文档,记录一些经常投简历的时候需要填写的问题,比如用python的经验,用ml的经验
投工作之后可以跟放出这个岗位的HR再发个私信
以后工作了还是要重视networking。多交朋友
面试经验很重要,所以要找mock interview试试
面试之前看看别人的JD,然后把关键词找出来,技术栈什么的。自我介绍的时候提一下。很多HR不懂技术,但是会捕捉关键词
收到面试邀请后可以网上搜搜面经 比如https://www.glassdoor.ca/Interview/Cresta-CA-Interview-Questions-E3180909.htm
考代码之前,先花1h以上把所有题型都给过一遍
面试前记得看 https://github.com/luochuankai-JHU/work_summary/blob/main/interview_lesson.md#monitor_and_computers
面试前记得看 https://github.com/luochuankai-JHU/work_summary/blob/main/interview_lesson.md#monitor_and_computers
面试前记得看 https://github.com/luochuankai-JHU/work_summary/blob/main/interview_lesson.md#monitor_and_computers
视频的时候可以穿个衬衫,显得专业/正式一点
笔试做题和面试做题¶
- 输入输出要搞明白,line那个变量没有定义这种事情不要再发生了(我经常搞出这种变量未定义,超边界的事情)。例题1和例题2多看看
- 笔试的优点在于:可以用愚蠢的暴力法去得一个基础分数。可以一个个的去尝试。比如某公司的某个跳台阶的题目,题目没描述清楚,那么我们一个个的去尝试前几个值,能把他的分布找出来
- 笔试的缺点在于,如果出了任何的bug,是得不了分的。而且解释的机会都没有。而且不能print 的debug
- print还是return,py2还是py3 一定要看清楚。而且,某公司让你取100000007%的模,那就一定要取!
- 脑子不能僵硬,该那啥那啥。选择题和编程题都是。
6. !!!!输入就用 a = input(). 然后记得 a=input().strip().split(). 需要strip,因为有时候输入的东西不干净,前后有空格。然后用split不要用list()….吃过一次亏了,之间把“10”给我分成了[“1”,”0”]
- 既然可以在自己的本地进行调试。那就一定要在本地调试。用完整的代码,大不了复制粘贴输入输出而已。这样避免用他的调试半天不出结果。而且这样能看见报错。
拿到offer之后需要问的问题¶
[选组选Offer] [工作信息] 【选组选offer】如何选到理想的公司或team? https://www.1point3acres.com/bbs/thread-806618-1-1.html
System Design¶
Consistent Hashing 一致性哈希¶
https://www.xiaolincoding.com/os/8_network_system/hash.html
这篇文章说的太好了
如果网页打不开,我有截屏保存在 docs/_static/python/consistent_hashing.png
MLE/AS 面试¶
参考资料¶
https://www.1point3acres.com/bbs/thread-901595-1-1.html [找工就业] [工作信息] 个人经验教你如何准备MLE/AS的面试 – Part 1
coding¶
前辈的经验说的都很好!
有的公司会有专门的ML coding或者出的coding题会更数学一点,比如怎么设计一个sparse matrix (包括加减乘等运算)。这需要你懂得这些矩阵的运算大概是怎么work的。 有的公司甚至可能会要求你implement一个具体的算法像kNN/k-means之类的 或者用DL framework简单写一些model implementation像transformer的矩阵运算(这种面试一般不是非常common)。 所以建议的准备是对于最常用的算法你需要至少能达到写伪代码的程度。
ML design¶
这个是MLE面试和SDE面试最不一样的地方,基本上所有公司都会有一两轮考察这个。大概的面试题都是要求你按照一个实际的use case设计一个solution。比如最常见的怎么设计Youtube recommendation/doordash search box/auto suggestion/etc. 这种问题由于high ambiguity/很依赖经验,使得并不容易回答好。
看相关的准备材料。<a> 如果你实在经验很少,可以看看educative的ML system design/Grokking the Machine Learning Interview入门至少知道一个大致框架。比如search的问题需要分成information retrival和ranking两个步骤。如果你没有search的经验可能会一脸懵逼。。。如果你自己有不少CV/NLP/search/recommendation的经验这些课程意义不大。<b> 然后还是跟第一点一样,可以看看相应公司的blog来了解他们主要解决的是什么样子的问题以及解决的方法。<c> 可以去youtube里面搜索一些相关的视频。我个人发现好的比较少,但也可以找到一些好的。比如我觉得这个talk就挺不错的:🔗 https://youtu.be/lh9CNRDqKBk
而在回答这个问题的时候,我自己的prefer的框架是: ask clarification questions: 1) 比如像 what’s the stage of the project。如果是早期可能需要考虑cold start的问题。2)traffic。这个会影响你engineering wise的robustness和latency的考虑之类的。3)assume常用的数据都log了。一般这个assumption都是成立的。不过依然建议double confirm。 . —- 整一个大的八股文的结构。roughly的描述主要的几个component:对于online的部分包括像 数据 (有online user data的 和 直接database fetch的),ML service, ML model artifact, logging and monitoring 对于offline的部分包括feature processing, modeling, evaluation。你应该很容易找到这个标准的design图像前面提到的那些课程里面。建议直接跟面试官画图。比如我自己很喜欢remote面试的时候准备ipad在上面直接画。这个一方面面试官会觉得你很有条理;另一方面当你讲details的时候会知道你在讲哪个方面。 .. 具体的实现。这个包括: <a> features。你会需要什么样的数据,这个需要自己多开脑洞。比如recommendation大致分成三块 document related features (like # of watches, text, video embedding), user related features (gender, geographic info super important for location related search , previous watches, previous searches), interaction features (distance, watched/clicked before or not, matched words), etc. 而往往你会需要了解最常用的text embedding/ image embedding/id embedding的方法从而能够知道怎么处理这些非numerical的数据。<b> 模型。这个就是整个design的meat了。你首先需要把问题建模成regression/classification/ranking/etc 中的哪个问题。你对于input是怎么encode,你模型的框架什么样子(对于ranking bi-encoder vs cross-encoder vs poly-encoder,对于recommendation最常见的two-tower), 然后模型的主体是一个什么模型 (往往会考察不同模型选择的优劣势logistic regression vs. random forest; LSTM vs. Transformer),然后模型的loss function怎么选择。<c> evaluation。 你需要知道最常用的evaluation metrics像 accuracy/AUC/F1/precision/recall/MSE, 对于NLP像 perplexity/BLEU/ROGUE/BertScore, etc. <c> 其它的部分基本不大可能聊出花来。简单的延伸像是对于不同的数据用什么方式存储,data pipeline怎么设计之类的。
ML knowledge¶
我的感觉是绝大多数公司MLE面试对ML Knowledge并不深,相对来说如果你面试的title是Scientist的情况会更加注重一些。这也非常好理解,MLE本质更在乎engineering所以对hands-on的要求更高一些。当时实际上不同title做的东西不会有很大差异。.

欠缺需补¶
一点都不能松劲啊!!!
英语。我发现很多项目的细节我其实用英语说不清楚。这个要多加练习。以后晚上多和chat练练?
model的deployment我不知道。 通用工具我不知道
docker
Kubernetes
noSQL/sql
数据库
data warehousing
PySpark
ETL processes
云相关的内容要学
CI/CD
system design OOD 这个需要恶补
leetcode 还是要继续刷,以后每天回家来一道?
其他:
Grokking the Machine Learning Interview!!!https://youtu.be/lh9CNRDqKBk
怎么设计Youtube recommendation/doordash search box/auto suggestion
对于NLP的应用可能会问你如果文本非常长怎么处理;推荐的应用上可能会问你怎么做counterfactual evaluation。
有的公司会有专门的ML coding或者出的coding题会更数学一点,比如怎么设计一个sparse matrix (包括加减乘等运算)。这需要你懂得这些矩阵的运算大概是怎么work的。 有的公司甚至可能会要求你implement一个具体的算法像kNN/k-means之类的 或者用DL framework简单写一些model implementation像transformer的矩阵运算(这种面试一般不是非常common)。 所以建议的准备是对于最常用的算法你需要至少能达到写伪代码的程度。