NLP¶
实用网站备份¶
THUOCL:清华大学开放中文词库 http://thuocl.thunlp.org/
中文词表 https://github.com/qianzhengyang/AllDataPackages
里面有个知识图谱的 https://github.com/qianzhengyang/AllDataPackages/tree/master/KnowledgeGraph
中文停用词 在我的这个github里面
项目涉及¶
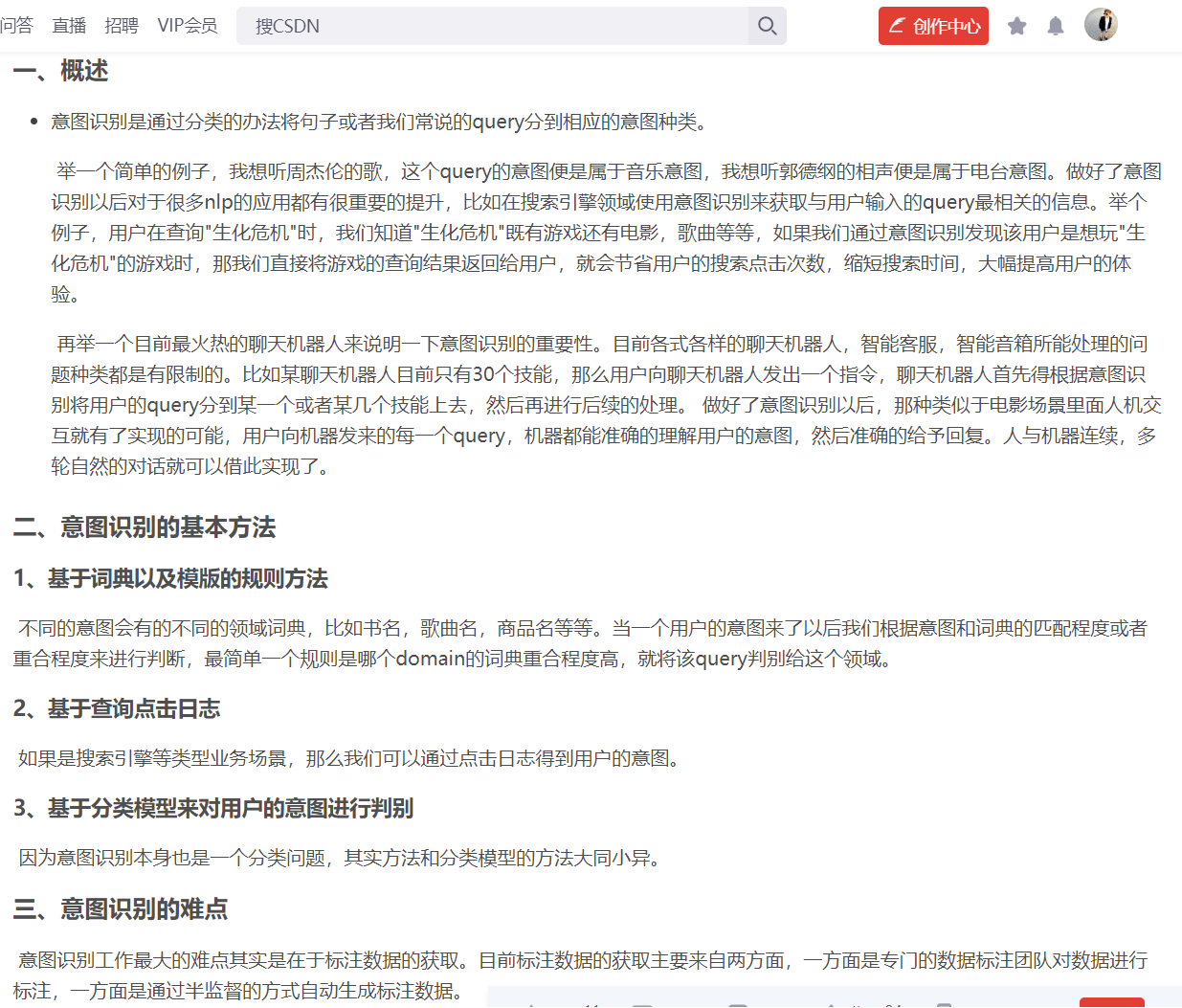

知识蒸馏¶
李宏毅是真的讲得好https://www.bilibili.com/video/BV1SC4y1h7HB?p=7
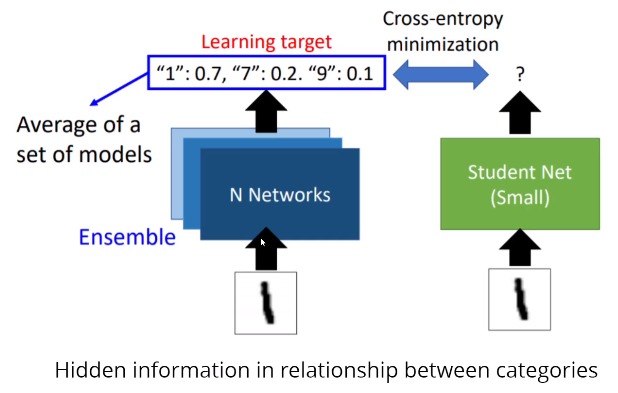

temperature就是为了防止teacher的反馈和one-hot label太像
fastbert¶
ACL2020一篇关于提高BERT推理速度的文章,提出了一种新的inference速度提升方式,相比单纯的student蒸馏有更高的确定性,且可以自行权衡效果与速度
FastBERT的创新点很容易理解,就是在每层Transformer后都加分类器去预测样本标签,如果某样本预测结果的置信度很高,就不用继续计算了。
论文把这个逻辑称为样本自适应机制(Sample-wise adaptive mechanism),就是自适应调整每个样本的计算量,容易的样本通过一两层就可以预测出来,较难的样本则需要走完全程。
这里的分支Classifier都是最后一层的分类器蒸馏来的,作者将这称为自蒸馏(Self-distillation)。
就是在预训练和精调阶段都只更新主干参数,精调完后freeze主干参数,用分支分类器(图中的student)蒸馏主干分类器(图中的teacher)的概率分布。
之所以叫自蒸馏,是因为之前的蒸馏都是用两个模型去做,一个模型学习另一个模型的知识,而FastBERT是自己(分支)蒸馏自己(主干)的知识。
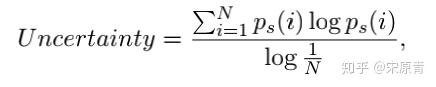
不确定性就是用熵来衡量的。熵越大代表结果越不可信,如果某一层的不确定性小于一个阈值,那么我们就对这层的结果进行输出,从而提高了推理速度
elasticsearch(es)/倒排索引¶
简单的说法
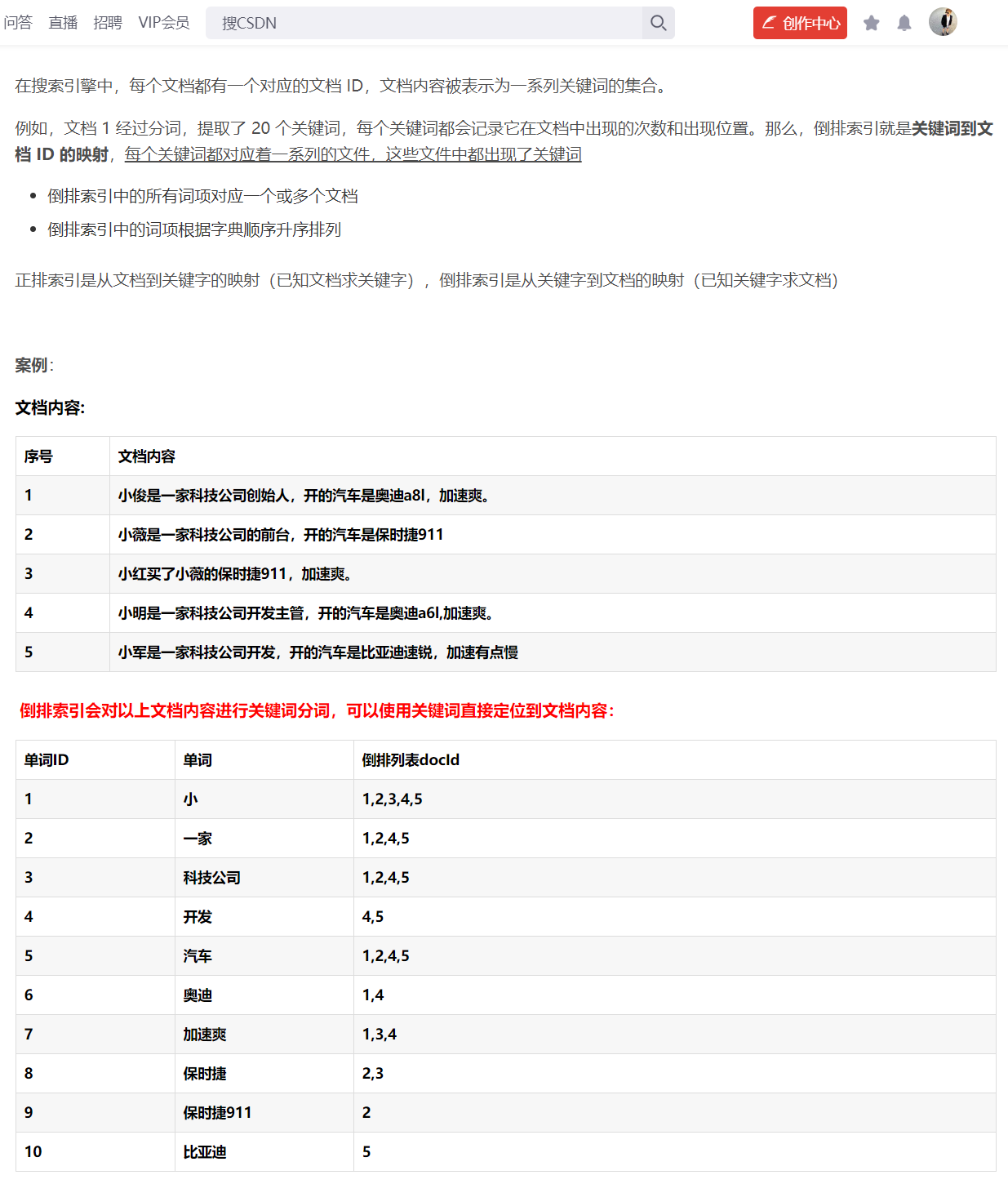
https://blog.csdn.net/RuiKe1400360107/article/details/103864216
更详细的再去网上搜
里面用到的算法是TF-IDF算法,详细见本文档 https://knowledge-record.readthedocs.io/zh-cn/latest/python/python.html#tf-idf
召回¶
协同过滤,聚类
搜索引擎的两大问题(1) - 召回https://www.douban.com/note/722330114/
我们知道召回是通过倒排索引求交得到的,当以词为粒度,粒度较细, 召回的文章的数目较多,但也可能由于倒排过长把一些相关的结果误截断;当以更大的phrase粒度, 粒度较粗,召回的文章相对更相关,但也容易造成召回的结果过少。
匹配¶
pointwise、pairwise、listwise¶
https://zhuanlan.zhihu.com/p/56938216
在pointwise中把排序问题当成一个二分类问题,训练的样本被组织成为一个三元组(qi,cij,yij)跟我们的构造方法一样
在pairwise方法中排序模型让正确的回答的得分明显高于错误的候选回答。给一个提问,pairwise给定一对候选回答学习并预测哪一个句子才是提问的最佳回答。
训练的样例为(qi,ci+,ci-),其中qi为提问,ci+为正确的回答,ci-为候选答案中一个错误的回答。
损失函数为合页损失函数
listwise: pariwise和pointwise忽视了一个事实就是答案选择就是从一系列候选句子中的预测问题。在listwise中单一训练样本就是提问数据和它的所有候选回答句子。 在训练过程中给定提问和它的一系列候选句子和标签
ernie¶
ERNIE 沿袭了 BERT 中绝大多数的设计思路,包括 预训练 (Pretraining) 加 微调 (Fine-tuning) 的流程, 去噪自编码 (DAE, abbr. denoising autoencoding) 的模型本质,以及 Masked Language Model 和 Next Sentence Prediction 的训练环节。主要的不同,在于 ERNIE 采用了更为复杂的 Masking 策略: Knowledge Masking Strategies,并针对对话型数据引入一套新的训练机制:对话语言模型 (Dialogue Language Model)。
ERNIE2
不同于ERNIE1仅有词级别的Pretraining Task,ERNIE2考虑了词级别、结构级别和语义级别3类Pretraining Task,词级别包括Knowledge Masking(短语Masking) 、Capitalization Prediction(大写预测)和Token-Document Relation Prediction(词是否会出现在文档其他地方)三个任务,结构级别包括Sentence Reordering (句子排序分类)和Sentence Distance(句子距离分类)两个任务,语义级别包括Discourse Relation(句子语义关系)和IR Relevance(句子检索相关性)两个任务
ERNIE2采用了持续学习的机制,多个任务轮番学习
albert¶
ALBERT的贡献
文章里提出一个有趣的现象:当我们让一个模型的参数变多的时候,一开始模型效果是提高的趋势,但一旦复杂到了一定的程度,接着再去增加参数反而会让效果降低,这个现象叫作“model degratation”。
基于上面所讲到的目的,ALBERT提出了三种优化策略,做到了比BERT模型小很多的模型,但效果反而超越了BERT, XLNet。
- Factorized Embedding Parameterization. 他们做的第一个改进是针对于Vocabulary Embedding。在BERT、XLNet中,
词表的embedding size(E)和transformer层的hidden size(H)是等同的,所以E=H。但实际上词库的大小一般都很大, 这就导致模型参数个数就会变得很大。为了解决这些问题他们提出了一个基于factorization的方法。
他们没有直接把one-hot映射到hidden layer, 而是先把one-hot映射到低维空间之后,再映射到hidden layer。这其实类似于做了矩阵的分解。
- Cross-layer parameter sharing. Zhenzhong博士提出每一层的layer可以共享参数,这样一来参数的个数不会以层数的增加而增加。所以最后得出来的模型相比BERT-large小18倍以上。
- Inter-sentence coherence loss. 在BERT的训练中提出了next sentence prediction loss, 也就是给定两个sentence segments, 然后让BERT去预测它俩之间的先后顺序,但在ALBERT文章里提出这种是有问题的,其实也说明这种训练方式用处不是很大。
所以他们做出了改进,他们使用的是setence-order prediction loss (SOP),其实是基于主题的关联去预测是否两个句子调换了顺序。
只用了四层的transformer,但是效果下降不多。
RoBERTa¶
静态Masking vs 动态Masking
原来Bert对每一个序列随机选择15%的Tokens替换成[MASK],为了消除与下游任务的不匹配,还对这15%的Tokens进行 (1)80%的时间替换成[MASK];(2)10%的时间不变;(3)10%的时间替换成其他词。 但整个训练过程,这15%的Tokens一旦被选择就不再改变,也就是说从一开始随机选择了这15%的Tokens,之后的N个epoch里都不再改变了。这就叫做静态Masking。
而RoBERTa一开始把预训练的数据复制10份,每一份都随机选择15%的Tokens进行Masking,也就是说, 同样的一句话有10种不同的mask方式。然后每份数据都训练N/10个epoch。这就相当于在这N个epoch的训练中,每个序列的被mask的tokens是会变化的。这就叫做动态Masking。
解释我们的NSP:next sentence prediction¶
当时在NLP大佬Alex的推特下面也参与了讨论。在国内的论坛也和大量的网友讨论过。
我有两个观点。我觉得应该是数据太简单了。就是他的后文选取的太随意。其实这个对于问答系统还是很有帮助的。
弱是因为bert构造负样本的时候使用不同document的内容随机搭配,以至于模型最终学出来的很大一部分是前后句是否同一个topic,而非严格的前后句。 因为构造的正负样本分别来自同一个topic和不同的topic。而这部分信息和MLM信息有重叠,MLM的损失计算已经包含有topic的判断。
提到SOP: 解决方法就是重新构造正负样例,让负样例也来自于同一个topic,提升问题的难度,让模型即使对于同一个topic的句子也能区分是否next sentence,于是就有了SOP, 正样例是正确的前后句,负样例是颠倒顺序的前后句
或者我们的解决方案:但是我们的不是,我们的数据很难,比如第一句是汉武大帝这部电影,我们第二句的数据在构造的时候会包括汉武大帝这部电影, 会包括汉武大帝这个人,会包括汉武大帝这本书,汉武大帝的纪录片等等,模型一定要深入理解了内在关系才能进行判断
NSP是预训练,我们这个是下游任务
SOP¶
Albert原文里对SOP和NSP的评价是:SOP是一个更有挑战性并且更实用的方法,实验比较出来效果更好
如果不使用NSP或SOP作为预训练任务的话,模型在NSP和SOP两个任务上表现都很差;如果使用NSP作为预训练任务的话,模型确实能很好的解决NSP问题, 但是在SOP问题上表现却很差,几乎相当于随机猜,因此说明NSP任务确实很难学到句子间的连贯性;而如果用SOP作为预训练任务,则模型也可以较好的解决NSP问题, 同时模型在下游任务上表现也更好。说明SOP确实是更好的预训练任务。
focal_loss 和 label_smoothing¶
怕找不到
focal_loss: https://knowledge-record.readthedocs.io/zh-cn/latest/cv/cv.html#focal-loss 正负样本不均衡
label_smoothing: 训练样本有误差(本来正负样本是1和0,现在变成0.1和0.9 差距没那么大)
基础知识¶
剪枝
word2vec¶
李宏毅机器学习 unsupervised learning word embedding https://www.bilibili.com/video/BV13x411v7US?p=25
这个是别人做的笔记 https://www.jianshu.com/p/8c7030ccbf9e
核心:通过一个词汇的上下文去了解他的意思
count base的做法
wi词和wj词查找共同出现的次数,那么wi词的向量和wj词的向量的乘积应该接近于这个数

predition base的做法
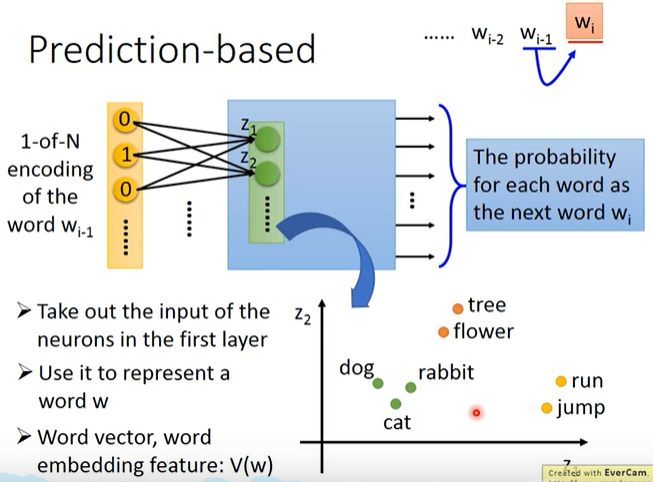
用前一个字去预测后一个字。先用one-hot编码,然后输入到一个线性神经网络,网络的最后去预测。那么他把神经网络的第一层(相当于是一个降维的功能)当作word embedding
如果不仅是只用前一个词,而是前N个词。那么w这个权重是共享的。
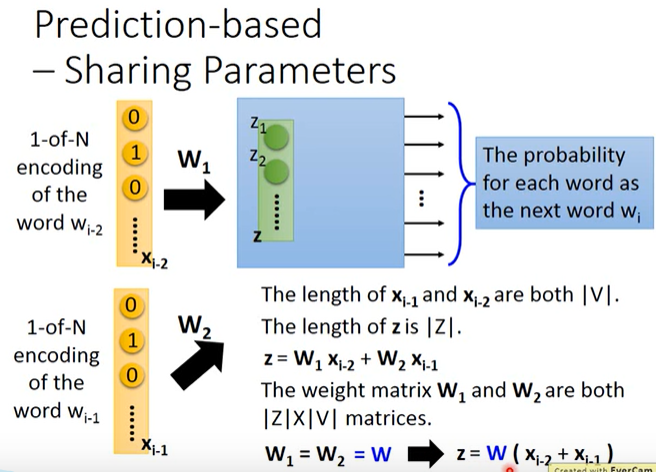
变体:
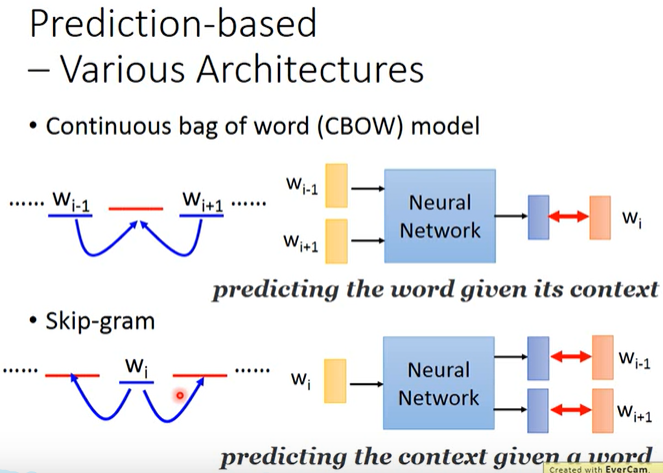
CBOW 用两边预测中间。 skip-gram 用中间预测两边
skip-gram 训练时间更长,出来的准确率比cbow 高。但是生僻词较多时cbow更好
优化:
hierarchical softmax优化、负采样
Negative Sampling负采样¶
Negative Sampling是对于给定的词,并生成其负采样词集合的一种策略,已知有一个词,这个词可以看做一个正例,而它的上下文词集可以看做是负例, 但是负例的样本太多,而在语料库中,各个词出现的频率是不一样的,所以在采样时可以要求高频词选中的概率较大, 低频词选中的概率较小,这样就转化为一个带权采样问题,大幅度提高了模型的性能。
Negative Sampling · 负采样 在训练神经网络时,每当接受一个训练样本,然后调整所有神经单元权重参数,来使神经网络预测更加准确。换句话说,每个训练样本都将会调整所有神经网络中的参数。 我们词汇表的大小决定了我们skip-gram 神经网络将会有一个非常大的权重参数,并且所有的权重参数会随着数十亿训练样本不断调整。
negative sampling 每次让一个训练样本仅仅更新一小部分的权重参数,从而降低梯度下降过程中的计算量。 如果 vocabulary 大小为1万时, 当输入样本 ( “fox”, “quick”) 到神经网络时, “ fox” 经过 one-hot 编码, 在输出层我们期望对应 “quick” 单词的那个神经元结点输出 1,其余 9999 个都应该输出 0。 在这里,这9999个我们期望输出为0的神经元结点所对应的单词我们为 negative word. negative sampling 的想法也很直接 , 将随机选择一小部分的 negative words,比如选 10个 negative words 来更新对应的权重参数。
在论文中作者指出指出对于小规模数据集,建议选择 5-20 个 negative words,对于大规模数据集选择 2-5个 negative words.
如果使用了 negative sampling 仅仅去更新positive word- “quick” 和选择的其他 10 个negative words 的结点对应的权重,共计 11 个输出神经元,相当于每次只更新 300 x 11 = 3300 个权重参数。对于 3百万 的权重来说,相当于只计算了千分之一的权重,这样计算效率就大幅度提高。
hierarchical softmax层次softmax¶
构造Huffman树
基本原理 | • 根据标签(label)和频率建立霍夫曼树;(label出现的频率越高,Huffman树的路径越短) | • Huffman树中每一叶子结点代表一个label;
hierarchical softmax 将词库表示成前缀树,从树根到叶子的路径可以表示为一系列二分类器,一次多分类计算的复杂度从|V|降低到了树的高度
Hierarchical Softmax(层次Softmax) https://zhuanlan.zhihu.com/p/56139075
Word2vec ——算法岗面试题 https://www.cnblogs.com/zhangyang520/p/10969975.html
bag_of_word¶
它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。 简单说就是将每篇文档都看成一个袋子(因为里面装的都是词汇,所以称为词袋,Bag of words即因此而来),然后根据袋子里装的词汇对其进行分类。 如果文档中猪、马、牛、羊、山谷、土地、拖拉机这样的词汇多些,而银行、大厦、汽车、公园这样的词汇少些,我们就倾向于判断它是一篇描绘乡村的文档,而不是描述城镇的。
各种词语出现的数量
n-gram¶

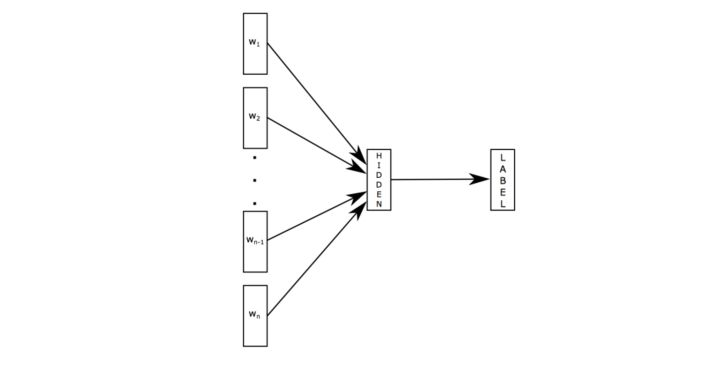
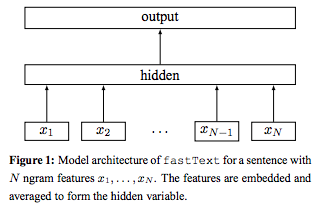

glove¶
word2vec是“predictive”的模型,而GloVe是“count-based”的模型
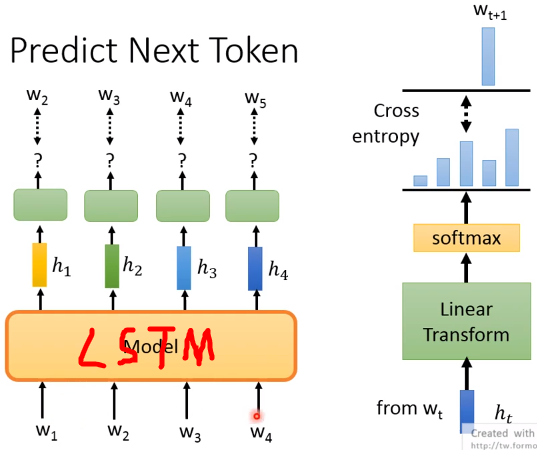
先进来w1,然后得到隐藏层h1,通过线性层和softmax预测下一句。所以w1 w2 w3不能一次性全读入
ELMO双向¶
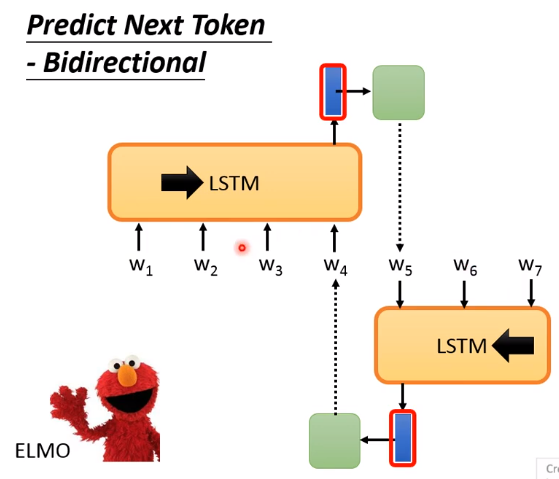
从前往后有个LSTM生成隐层,从后往前也有个LSTM生成隐层,然后两个隐层拼接起来才是总共的embedding结果
但是相比BERT存在的问题是:从前往后的时候只看到这个词为止了,没有继续往后看,从后往前的时候也是没有看到最开始。
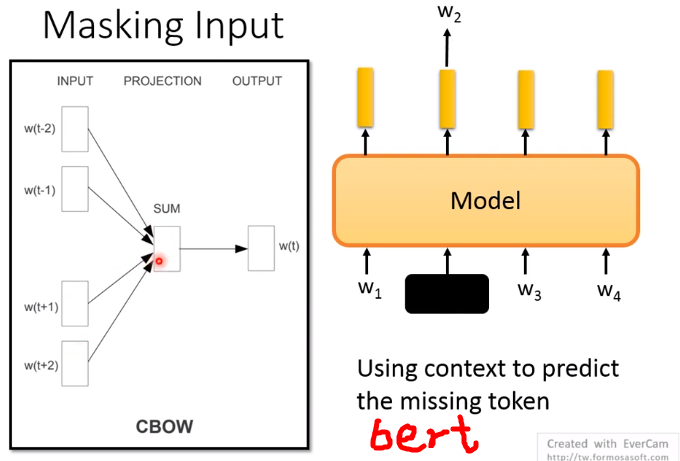
bert的话,把w2遮住或者随机替换。用隐藏层去预测w2。这样的话,隐藏层里面会看见前后的所有信息。
细粒度分类¶
????待补充
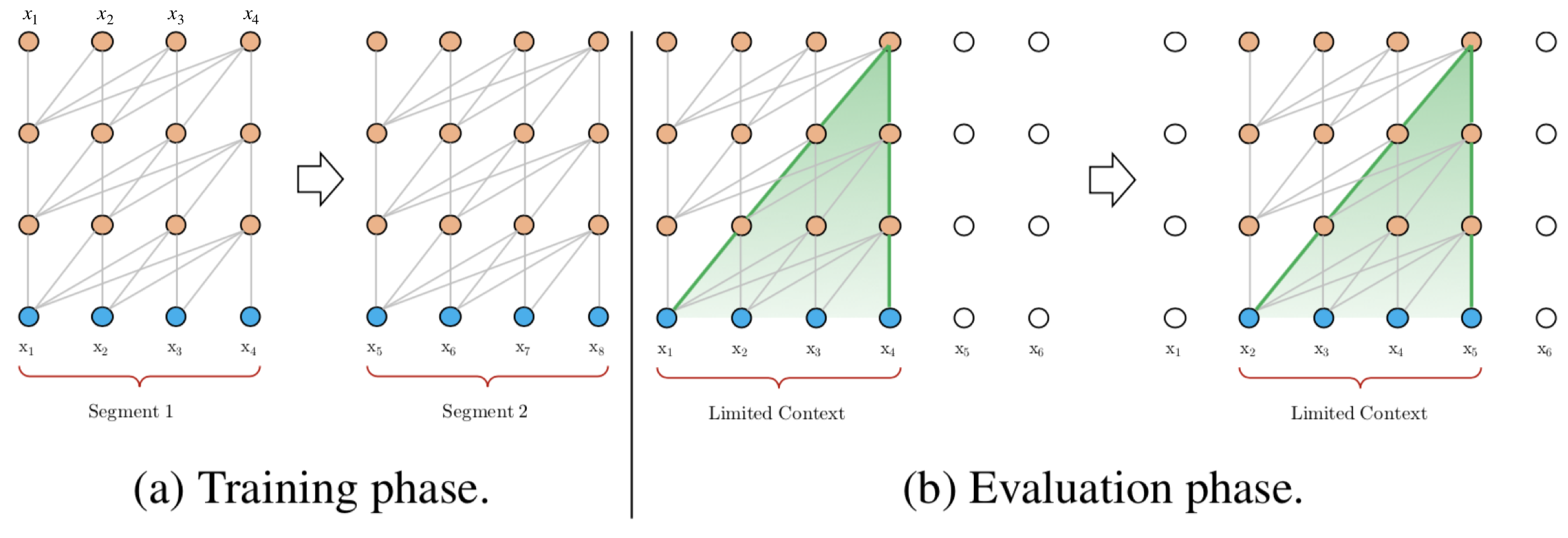
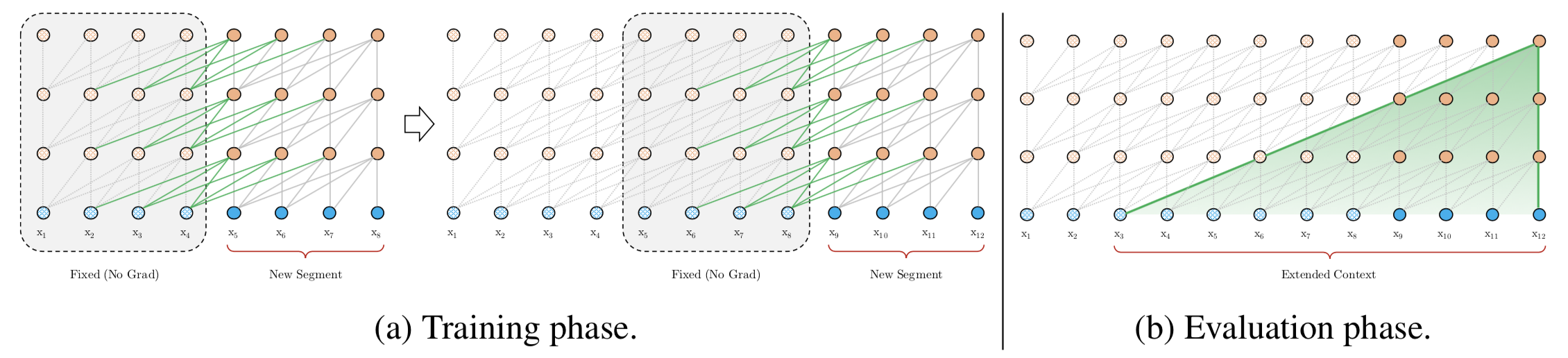
XLNet¶
从language model的观点来看:
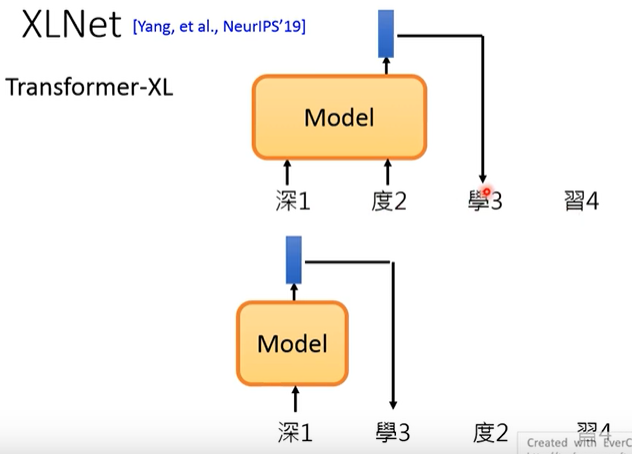
从Bert的观点来看:
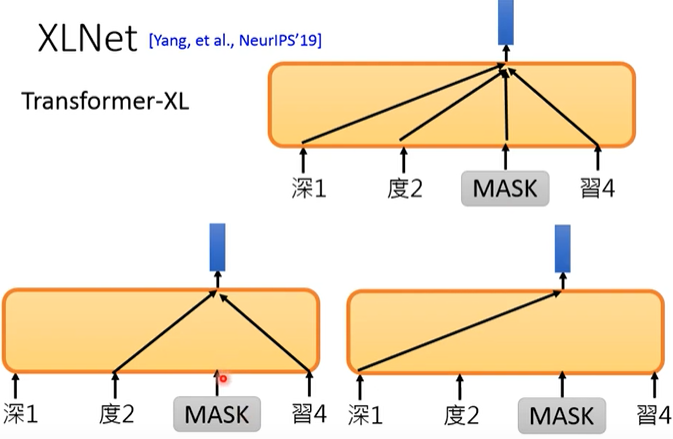
而且不给model看见mask。 注意这张图里面的mask是没有一条线的。因为作者任务下游任务也没有出现mask
??再看!!
nlp中的数据增强¶
随机drop和shuffle、同义词替换、回译、文档裁剪、GAN、预训练的语言模型
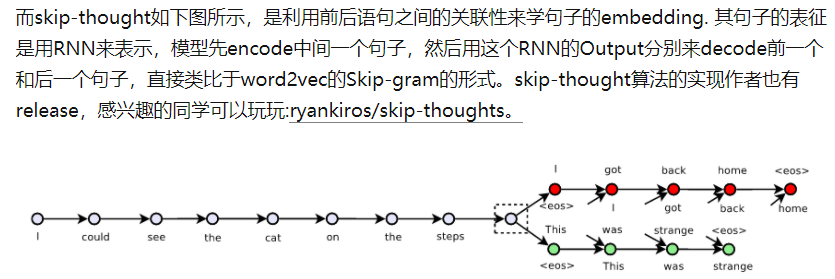
skip-thought¶
TextCNN¶
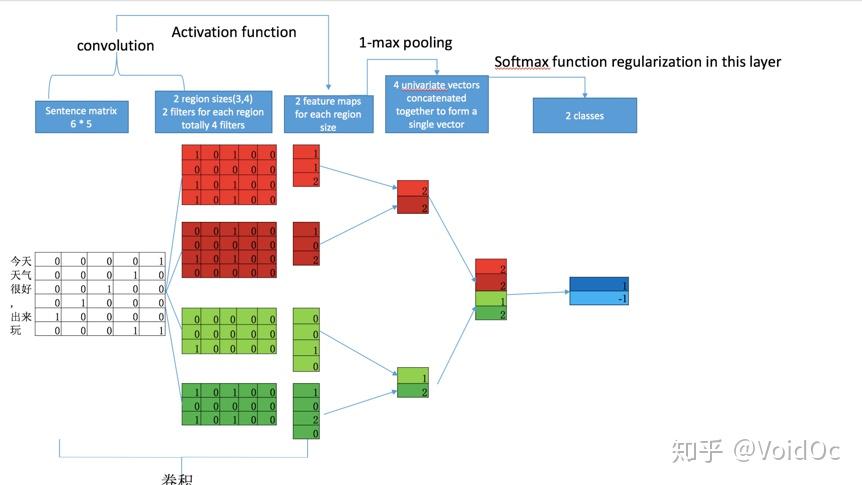
把文本通过向量表示之后,一行一行的组成一个二维向量矩阵
将一个设计好的convolutional kernel扫过去得到中间向量
中间向量进行max-pooling降维
接softmax分类器
句子的向量表示方法 / sentence2vec¶
文本的向量表示方法¶
词袋法¶
忽略其词序和语法,句法,将文本仅仅看做是一个词集合。若词集合共有NN个词,每个文本表示为一个NN维向量,元素为0/1,表示该文本是否包含对应的词。( 0, 0, 0, 0, …. , 1, … 0, 0, 0, 0)
一般来说词库量至少都是百万级别,因此词袋模型有个两个最大的问题:高纬度、高稀疏性
n-gram词袋模型¶
与词袋模型类似,考虑了局部的顺序信息,但是向量的维度过大,基本不采用。如果词集合大小为N,则bi-gram的单词总数为N2向量空间模型
向量空间模型¶
以词袋模型为基础,向量空间模型通过特征选择降低维度,通过特征权重计算增加稠密性。
特征权重计算¶
一般有布尔权重、TFIDF型权重、以及基于熵概念权重这几种方式,其中布尔权重是指若出现则为1,否则为0,也就是词袋模型;而TFIDF则是基于词频来进行定义权重; 基于熵的则是将出现在同一文档的特征赋予较高的权重。
分词¶
1)基于字符串匹配的分词方法:¶
过程:这是一种基于词典的中文分词,核心是首先建立统一的词典表,当需要对一个句子进行分词时,首先将句子拆分成多个部分,将每一个部分与字典一一对应,如果该词语在词典中, 分词成功,否则继续拆分匹配直到成功。
核心: 字典,切分规则和匹配顺序是核心。
分析:优点是速度快,时间复杂度可以保持在O(n),实现简单,效果尚可;但对歧义和未登录词处理效果不佳。
2)基于理解的分词方法:¶
基于理解的分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。 它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断, 即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式, 因此目前基于理解的分词系统还处在试验阶段。
3)基于统计的分词方法:¶
过程:统计学认为分词是一个概率最大化问题,即拆分句子,基于语料库,统计相邻的字组成的词语出现的概率,相邻的词出现的次数多,就出现的概率大,按照概率值进行分词,所以一个完整的语料库很重要。
主要的统计模型有: N元文法模型(N-gram),隐马尔可夫模型(Hidden Markov Model ,HMM),最大熵模型(ME),条件随机场模型(Conditional Random Fields,CRF)等。
4)英文分词技术:¶
英文分词相比中文分词要简单得多,可以根据空格和标点符号来分词,然后对每一个单词进行词干还原和词形还原,去掉停用词和非英文内容
RNN及其变体LSTM等¶
这个从基础知识里面单独拿出来讲
完全图解RNN、RNN变体、Seq2Seq、Attention机制 https://www.leiphone.com/news/201709/8tDpwklrKubaecTa.html
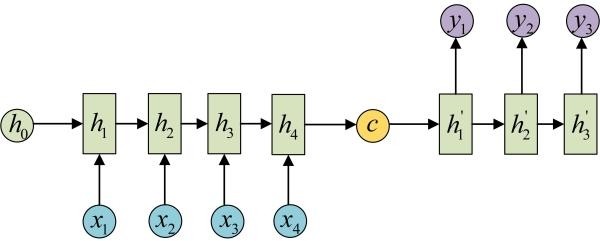
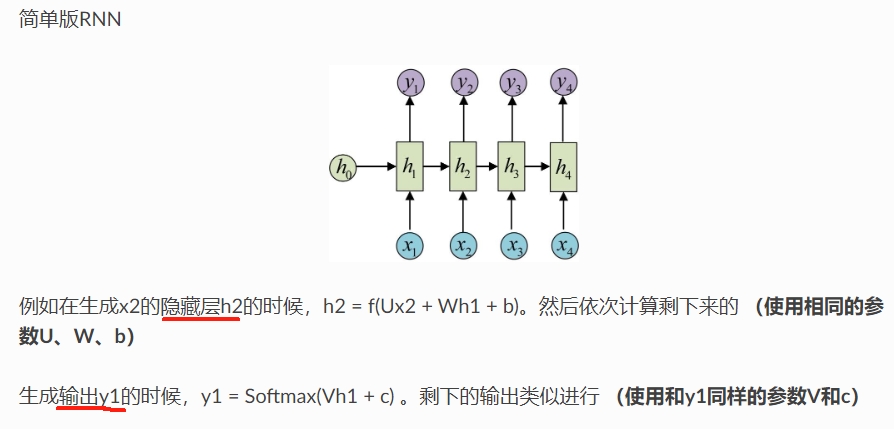
简单版RNN
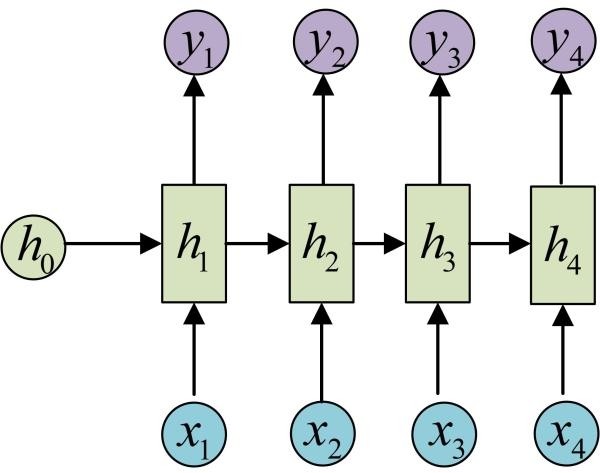
例如在生成x2的隐藏层h2的时候,h2 = f(Ux2 + Wh1 + b)。然后依次计算剩下来的 (使用相同的参数U、W、b)
生成输出y1的时候,y1 = Softmax(Vh1 + c) 。剩下的输出类似进行 (使用和y1同样的参数V和c)
为了输入输出不等长,所以出现了 seq2seq (encoder decoder)
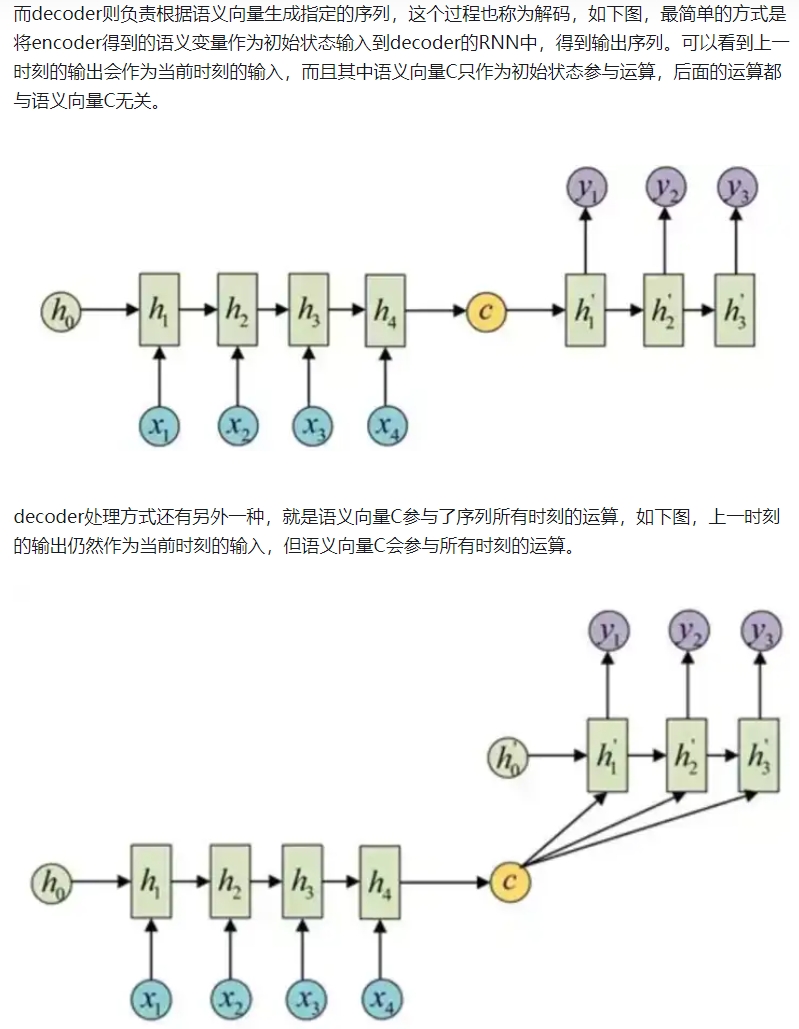
一维卷积CNN和RNN¶
另外一种处理sequence或者timeseries问题的方法就是使用1维的卷积网络,并且跟上1维度的池化层。卷积或者池化的维度就是timestep的维度。它可以学习到一些local pattern,视它window大小而定。
优点就是简单,计算相比于LSTM要快很多,所以一种常用的做法就是:
心电大赛中,先用CNN是为了学习到他的形态上的特征。1.这个符合医生的做法,医生也是根据波形的形状来判断的。2. 根据我们多年的研究,和心电大赛的前十名的选手的模型,这种做法实际效果最好
序列预测问题,CNN、RNN各有什么优势¶
CNN 形态特征,从形状上面提取特征。RNN 考虑前文对它的影响,
CNN优点在于平移不变性,在特征提取上不会破坏信号频谱,可以用来做特征提取,降维压缩。但是也要考虑结合LSTM做时间上的记忆
(平移不变性:图像中的猫在左上角还是右下角,标签都是猫)
GRU LSTM BRNN¶
吴恩达https://www.bilibili.com/video/BV1F4411y7BA?p=9

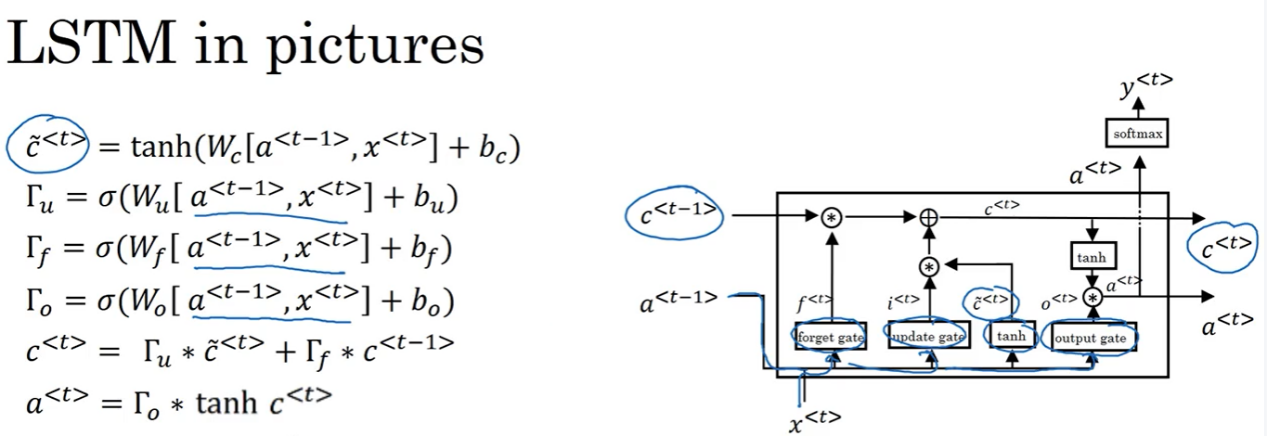
RNN的弊端,还有LSTM内部结构,以及接收的是前一个LSTM的什么?怎样解决长期依赖?为什么要用sigmoid?
长期依赖,三个门,加计算公式,sigmoid将值限制在了0-100%
RNN所谓梯度消失的真正含义是,梯度被近距离梯度主导,远距离梯度很小,导致模型难以学到远距离的信息。
LSTM的梯度爆炸可通过梯度裁剪解决。

LSTM简要介绍¶
建议之间看这个.. https://zhuanlan.zhihu.com/p/564057405
后面的内容只是节选自这个文章
先看下RNN。会产生Gradient Vanishing 梯度消失的问题 because there are too many chain rule derivatives
LSTM的全称是Long Short Term Memory。LSTM的提出正是为了解决长期依赖问题。
LSTM增加了一个细胞状态(cell state)
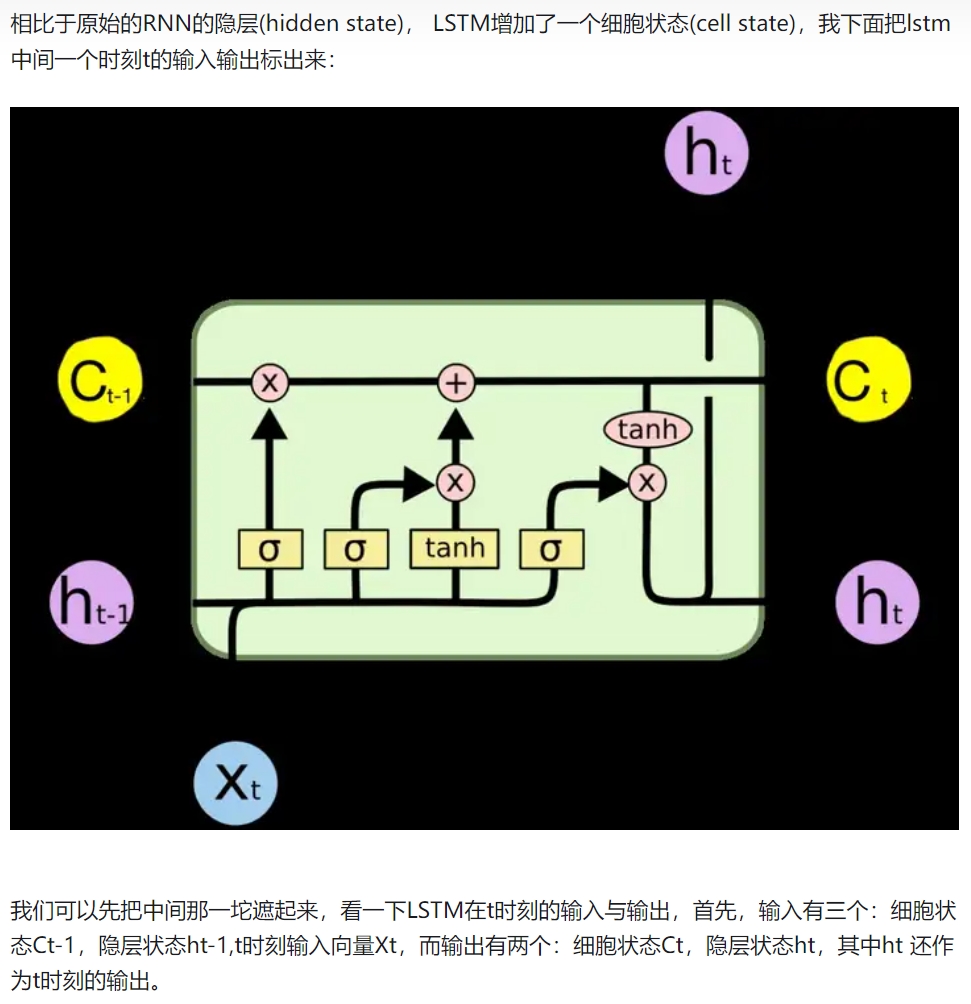
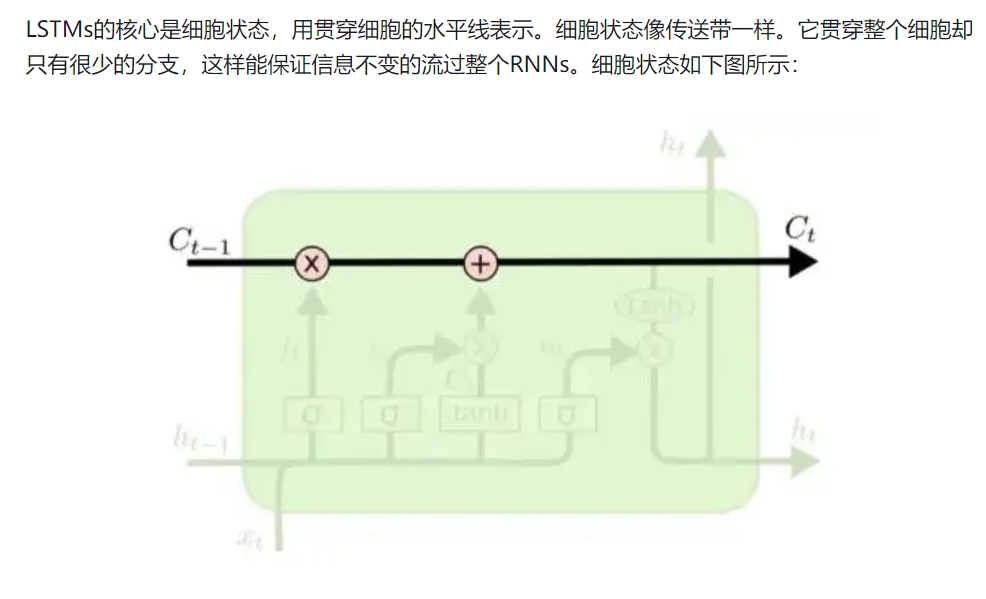
LSTM网络能通过一种被称为门的结构对细胞状态进行删除或者添加信息。门能够有选择性的决定让哪些信息通过。其实门的结构很简单,就是一个sigmoid层和一个点乘操作的组合。
遗忘门
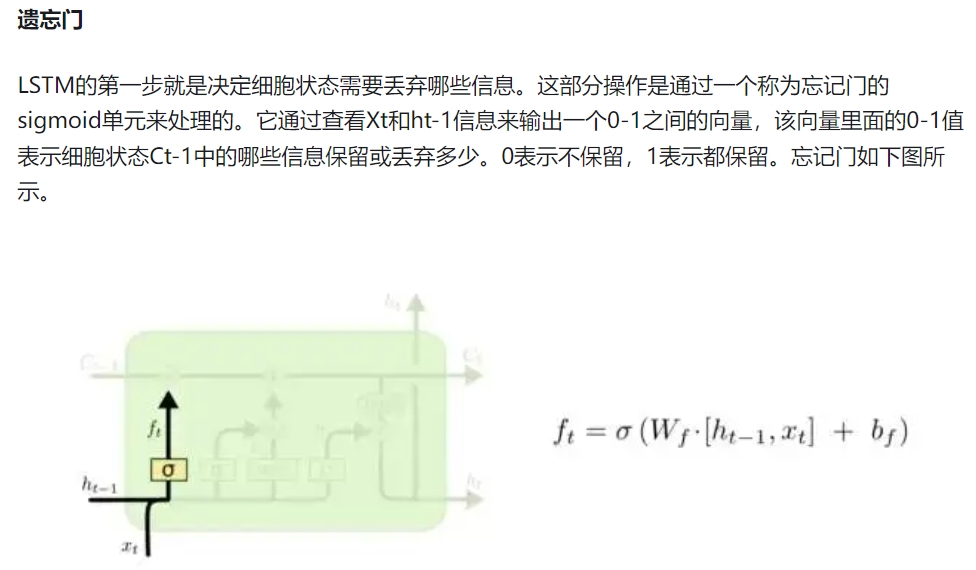
输入门
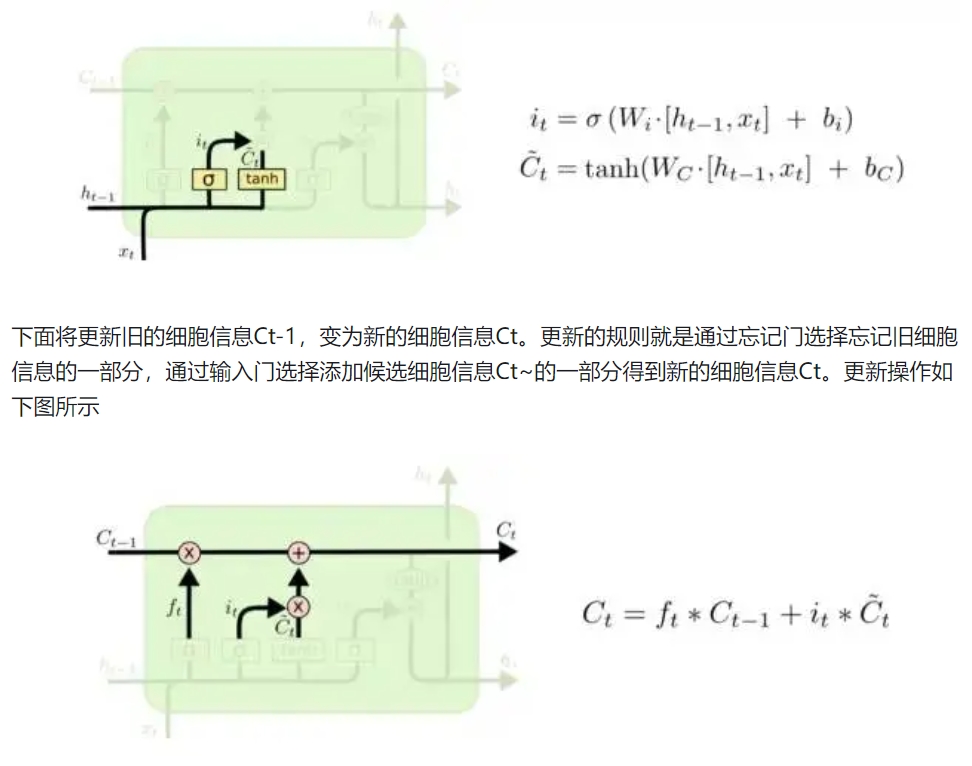
输出门
RNN LSTM 参数量¶
RNN。U是输入,W是隐藏层,V是输出。那么参数量应该是dim(W)+dim(U)+dim(V)。
即 n**2 + kn + nm。其中 n是隐藏层的维度,K是输出层的维度,m是输入层的维度。详细可见 https://www.cnblogs.com/wdmx/p/9284037.html
LSTM 模型的参数数量(包括 bias):4(mh+h**2+h) 其中m是输入向量的长度,h是输出向量(隐层)的长度。
LSTM 和 Transformer 复杂度对比¶
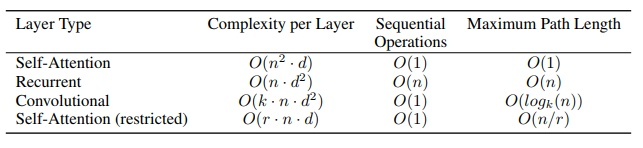
Transformer vs CNN vs RNN 时间复杂度比较 https://blog.csdn.net/Jerry_Lu_ruc/article/details/107690998
LSTM:seq_length * hidden**2
Transformer: seq_length**2 * hidden
因此,当隐层神经元数量大于序列长度时,Transformer 比 LSTM 快。
LSTM处理长序列的方法¶
1.原封不动
原封不动地训练/输入,这或许会导致训练时间大大增长。另外,尝试在很长的序列里进行反向传播可能会导致梯度消失,反过来会削弱模型的可靠性。在大型 LSTM 模型中,步长通常会被限制在 250-500 之间。
2.截断序列
处理非常长的序列时,最直观的方式就是截断它们。这可以通过在开始或结束输入序列时选择性地删除一些时间步来完成。这种方式通过失去部分数据的代价来让序列缩短到可以控制的长度,而风险也显而易见:部分对于准确预测有利的数据可能会在这个过程中丢失。
3.总结序列
在某些领域中,我们可以尝试总结输入序列的内容。例如,在输入序列为文字的时候,我们可以删除所有低于指定字频的文字。我们也可以仅保留整个训练数据集中超过某个指定值的文字。总结可以使得系统专注于相关性最高的问题,同时缩短了输入序列的长度。
4.随机取样
相对更不系统的总结序列方式就是随机取样了。我们可以在序列中随机选择时间步长并删除它们,从而将序列缩短至指定长度。我们也可以指定总长的选择随机连续子序列,从而兼顾重叠或非重叠内容。
在缺乏系统缩短序列长度的方式时,这种方法可以奏效。这种方法也可以用于数据扩充,创造很多可能不同的输入序列。当可用的数据有限时,这种方法可以提升模型的鲁棒性。
5.时间截断的反向传播
除基于整个序列更新模型的方法之外,我们还可以在最后的数个时间步中估计梯度。这种方法被称为「时间截断的反向传播(TBPTT)」。它可以显著加速循环神经网络(如 LSTM)长序列学习的过程。
这将允许所有输入并执行的序列向前传递,但仅有最后数十或数百时间步会被估计梯度,并用于权重更新。一些最新的 LSTM 应用允许我们指定用于更新的时间步数,分离出一部分输入序列以供使用。
6.使用编码器-解码器架构
可以使用自编码器来让长序列表示为新长度,然后解码网络将编码表示解释为所需输出。这可以是让无监督自编码器成为序列上的预处理传递者,或近期用于神经语言翻译的编码器-解码器 LSTM 网络。
attention¶
不错的资料¶
自然语言处理中的Attention机制总结 https://blog.csdn.net/hahajinbu/article/details/81940355
直观的解释¶
为什么要引入Attention机制¶
计算能力的限制:当要记住很多“信息“,模型就要变得更复杂,然而目前计算能力依然是限制神经网络发展的瓶颈。
优化算法的限制:虽然局部连接、权重共享以及pooling等优化操作可以让神经网络变得简单一些,有效缓解模型复杂度和表达能力之间的矛盾; 但是,如循环神经网络中的长距离以来问题,信息“记忆”能力并不高。
手写¶
???待补充
attention的一个通用定义¶
按照Stanford大学课件上的描述,attention的通用定义如下:
变体¶
答案是我自己根据一些博客总结的,待进一步考究与确认
动态attention
Attention score的计算方式变体

静态attention
强制前向attention
self attention
key-value attention
multi-head attention
bert¶
一些学习资料¶
Bert的一些面试题 https://cloud.tencent.com/developer/article/1558479
这篇文章讲解bert还不错 https://zhuanlan.zhihu.com/p/46652512
李宏毅bert https://www.bilibili.com/video/BV1C54y1X7xJ?p=1
BERT 时代的常见 NLP 面试题 https://blog.csdn.net/qq_34832393/article/details/104356462
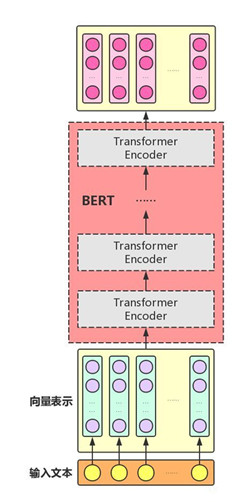
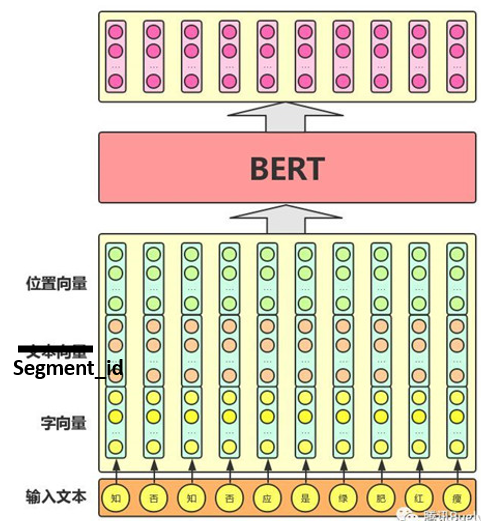
embedding¶
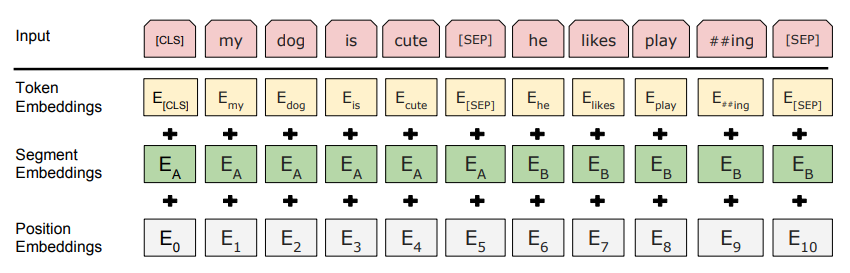
bert模型中的[CLS]、[UNK]、[SEP]是什么意思?¶
BERT 的输入可以包含一个句子对 (句子 A 和句子 B),也可以是单个句子。此外还增加了一些有特殊作用的标志位:
[CLS] 标志放在第一个句子的首位,经过 BERT 得到的的表征向量 C 可以用于后续的分类任务。
[SEP] 标志用于分开两个输入句子,例如输入句子 A 和 B,要在句子 A,B 后面增加 [SEP] 标志。
[UNK]标志指的是未知字符
[MASK] 标志用于遮盖句子中的一些单词,将单词用 [MASK] 遮盖之后,再利用 BERT 输出的 [MASK] 向量预测单词是什么。
BERT模型的预训练任务¶
BERT模型的预训练任务主要包含两个, 一个是MLM(Masked Language Model),一个是NSP(Next Sentence Prediction),BERT 预训练阶段实际上是将上述两个任务结合起来, 同时进行,然后将所有的 Loss 相加。
Masked Language Model 可以理解为完形填空,随机mask每一个句子中15%的词,用其上下文来做预测。
而这样会导致预训练阶段与下游任务阶段之间的不一致性(下游任务中没有【MASK】),为了缓解这个问题,会按概率选择以下三种操作:
例如:my dog is hairy → my dog is [MASK]
80%的是采用[mask],my dog is hairy → my dog is [MASK]
10%的是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
10%的保持不变,my dog is hairy -> my dog is hairy
Next Sentence Prediction可以理解为预测两段文本的蕴含关系(分类任务),选择一些句子对A与B,其中50%的数据B是A的下一条句子(正样本),剩余50%的数据B是语料库中随机选择的(负样本),学习其中的相关性。
前面提到序列的头部会填充一个[CLS]标识符,该符号对应的bert输出值通常用来直接表示句向量。
为什么Bert的三个Embedding可以进行相加?¶
知乎的一些解释:
1.空间维度很高,所以模型总能分开各个组分。 举个例子,假设词表大小 50k,segment 只有 2 种,position embedding 只有 512 种,这三者任选一个进行组合,至多有 50k x 2 x 512 = 50 M 种组合。 embedding 维度我没记错的话是 768 维,假设每个维度的取值范围是 [-1, 1],这就相当于要求模型在体积为 2^768 的空间里区分 50 M 个不同的点, 我觉得这个空间还是相对比较开阔的,所以模型能做到。
2.在实际场景中,叠加是一个更为常态的操作。比如声音、图像等信号。一个时序的波可以用多个不同频率的正弦波叠加来表示。只要叠加的波的频率不同,我们就可以通过傅里叶变换进行逆向转换。 一串文本也可以看作是一些时序信号,也可以有很多信号进行叠加,只要频率不同,都可以在后面的复杂神经网络中得到解耦(但也不一定真的要得到解耦)。 在BERT这个设定中,token,segment,position明显可以对应三种非常不同的频率。
等等
BERT为何使用学习的position embedding而非正弦position encoding¶
知乎的一些解释:
1.有个答主说 他的实验结果也是使用两种embedding的方法最终结果差不多,所以选择简单的方法 2.破坏轮换对称性,同时给长距离的 token 关联做自动衰减
GPT 与 BERT 的区别是什么¶
??? 待补充
GPT 是单向的,BERT 是双向的。
训练方法不同,GPT 是语言模型使用最大似然,BERT 的训练分为 MLM 和 NSP。
bert在seq2seq方面,也就是生成文本有欠缺。
GPT Bert与XLNet的差异 https://cloud.tencent.com/developer/article/1507551

bert里面的 intermediate layer¶
Transformer block是由multi-head self-attention + FFN构成的? 其实论文原文以及配图就是这样写的,但这么说不确切。如果你仔细地看过Transformer部分的源码,你会发现,在multi-head self-attention和FFN层之间, 还有一个“intermediate layer”,即中间层。这个中间层将前面Attention-layer的hidden size扩大了4倍,然后再做一次非线性变换( 即过一个激活函数,如gelu、relu),再将hidden size变回原size。中间这部分的功能,我个人理解,有点类似于“特征组合器”,增大神经元个数, 增强Transformer对于distributed的文本特征的组合能力,从而获取更多、更复杂的语义信息。此外,中间层是Transformer中唯一一个过了激活函数的layer, 所以也引入了非线性信息,当然从理论上也对提升模型的拟合不同语义信息能力有帮助。(当然,BERT预训练的MLM任务中,在bert_model的输出之后,在接softmax+将结果计算loss之前, 有一个hidden_size不变的线性变换Linear + 激活函数激活 + LayerNorm的过程,,这里也有个激活函数,但这并非Transformer的结构,这属于接了下游MLM任务的结构, 故真正Transformer-block中的非线性映射,只在中间层的激活函数引入)
实际上,“intermediate layer”在bert代码里是集成到FFN类中的,但由于很多人经常把FFN层直接当做一次线性变换(即简单的nn.Linear layer)而忽略了其中的intermediate layer, 故在这里单拎出来加以解释。
变种:BERT-wwm、BERT-wwm-ext、RoBERTa、SpanBERT、ERNIE2¶
摘抄自 https://www.cnblogs.com/dyl222/p/11845126.html
bert 掩码:
Mask 15% of all tokens
80% of the time, replace with [mask] token, 10% of the time, replace with random token, 10% of the time, keep the word unchanged
BERT-wwm¶
wwm是Whole Word Masking(对全词进行Mask),它相比于Bert的改进是用Mask标签替换一个完整的词而不是子词,中文和英文不同, 英文中最小的Token就是一个单词,而中文中最小的Token却是字,词是由一个或多个字组成,且每个词之间没有明显的分隔,包含更多信息的是词,全词Mask就是对整个词都通过Mask进行掩码。
BERT-wwm-ext¶
它是BERT-wwm的一个升级版,相比于BERT-wwm的改进是增加了训练数据集同时也增加了训练步数。
RoBERTa¶
相比于Bert的改进:更多的数据、更多的训练步数、更大的批次(用八千为批量数),用字节进行编码以解决未发现词的问题。
对Adam算法中的两处进行了调整:
Adam 中二阶矩估计时的 β_2,一般对于梯度稀疏之问题,如 NLP 与 CV,建议将此值设大,接近 1,因此通常默认设置为 0.999, 而此处却设 0.98。调节最早只用来防止除零情况发生的ε,通过对ε的调节能够提高模型的稳定性,有时能够提升模型性能。
对于Mask不再使用静态的Mask而是动态的Mask,对于同一句话,在不同的批次中参与训练其Mask的位置是不同的。(这样做相当于对数据进行了简单的增强)
取消了Next Sentence这一预训练任务,输入的不再是通过[SEP]隔开的句子对,而是一个句子段,对于短句会进行拼接,但是最大长度仍是512(这样做是因为更长的语境对模型更有利, 能够使模型获得更长的上下文),同时输入的句子段不跨文档(是因为引入不同文档的语境会给MLM带来噪音)。
SpanBERT¶
作者提出一种分词级别的预训练方法。它不再是对单个Token进行掩码,而是随机对邻接分词添加掩码。对于掩码词的选取, 作者首先从几何分布中采样得到分词的长度,该几何分布是偏态分布,偏向于较短的分词,分词的最大长度只允许为10(超过10的不是截取而是舍弃)。 之后随机(均匀分布)选择分词的起点。对选取的这一段词进行Mask,Mask的比例和Bert相同,15%、80%、10%、10%。
对于损失函数也进行了改进,去除了Next Sentence,
具体做法是,在训练时取 Span 前后边界的两个词,值得指出,这两个词不在 Span 内,然后用这两个词向量加上 Span 中被遮盖掉词的位置向量,来预测原词。
详细做法是将词向量和位置向量拼接起来,作者使用一个两层的前馈神经网络作为表示函数,该网络使用 GeLu 激活函数,并使用层正则化:
作者使用向量表示yi来预测xi,并和 MLM 一样使用交叉熵作为损失函数,就是 SBO 目标的损失,之后将这个损失和 BERT 的 Mased Language Model(MLM)的损失加起来,一起用于训练模型
ERNIE2¶
它的主要创新是ERNIE2采用Multi-task进行预训练,训练任务有词级别的、结构级别、语义级别三类。同时多任务是轮番学习,学习完一个任务再学习下一个任务, 不同任务使用相应损失函数,类似于教课,不同课应该分开上,若多任务同时学习会学的较为混乱,多个任务同时学习最好是任务之间存在关系,能够相互指导。
word2vec到bert的的区别¶
静态到动态:一词多义问题
word2vec产生的词表示是静态的,不考虑上下文的。
word2vec由词义的分布式假设(一个单词的意思由频繁出现在它上下文的词给出)出发,最终得到的是一个look-up table,每一个单词被映射到一个唯一的稠密向量。 这显然不是一个完美的方案,它无法处理一词多义(polysemy)问题。
所以bert的动态指的是可以fine-tune?一个词的向量表示也包含了周围词的信息,在不同上下文环境下,这个词的表示是不一样的,也就是所谓的动态的。
感觉是 word2vec是已经训练好了,每个字的字向量直接查表。而bert的向量还要去训练得到。
bert 论文里读的¶
模型参数¶
BERTBASE (L=12, H=768, A=12, Total Parameters=110M) and BERTLARGE (L=24, H=1024, A=16, Total Parameters=340M).
MASK¶
In this case, the final hidden vectors corresponding to the mask tokens are fed into an output softmax over the vocabulary, as in a standard LM. In all of our experiments, we mask 15% of all WordPiece tokens in each sequence at random.
Although this allows us to obtain a bidirectional pre-trained model, a downside is that we are creating a mismatch between pre-training and fine-tuning, since the [MASK] token does not appear during fine-tuning. To mitigate this, we do not always replace “masked” words with the actual [MASK] token.
The training data generator chooses 15% of the token positions at random for prediction. If the i-th token is chosen, we replace the i-th token with
- the [MASK] token 80% of the time
- a random token 10% of the time
- the unchanged i-th token 10% of the time.
Then, Ti will be used to predict the original token with cross entropy loss
NSP¶
Specifically, when choosing the sentences A and B for each pretraining example, 50% of the time B is the actual next sentence that follows A (labeled as IsNext), and 50% of the time it is a random sentence from the corpus (labeled as NotNext). (语料库不一定是同一篇文章,可以是其他文章)
(MLM和NSP的loss在预训的时候,好像是加在一起,两个任务同时算的)
transformer¶
一些学习资料¶
李宏毅 transformer讲解视频: https://www.bilibili.com/video/BV1J441137V6?from=search&seid=1952161104243826844
Transformer模型中重点结构详解 https://blog.csdn.net/urbanears/article/details/98742013 这个博客讲的不错
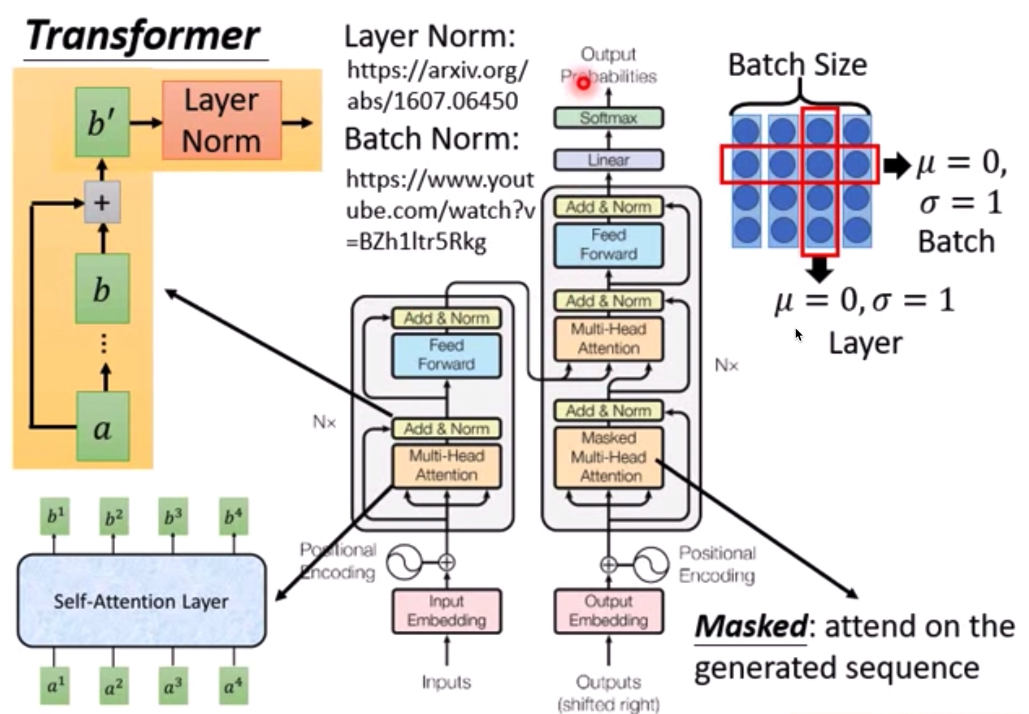
https://zhuanlan.zhihu.com/p/148656446
史上最全Transformer面试题
Q,K,V¶
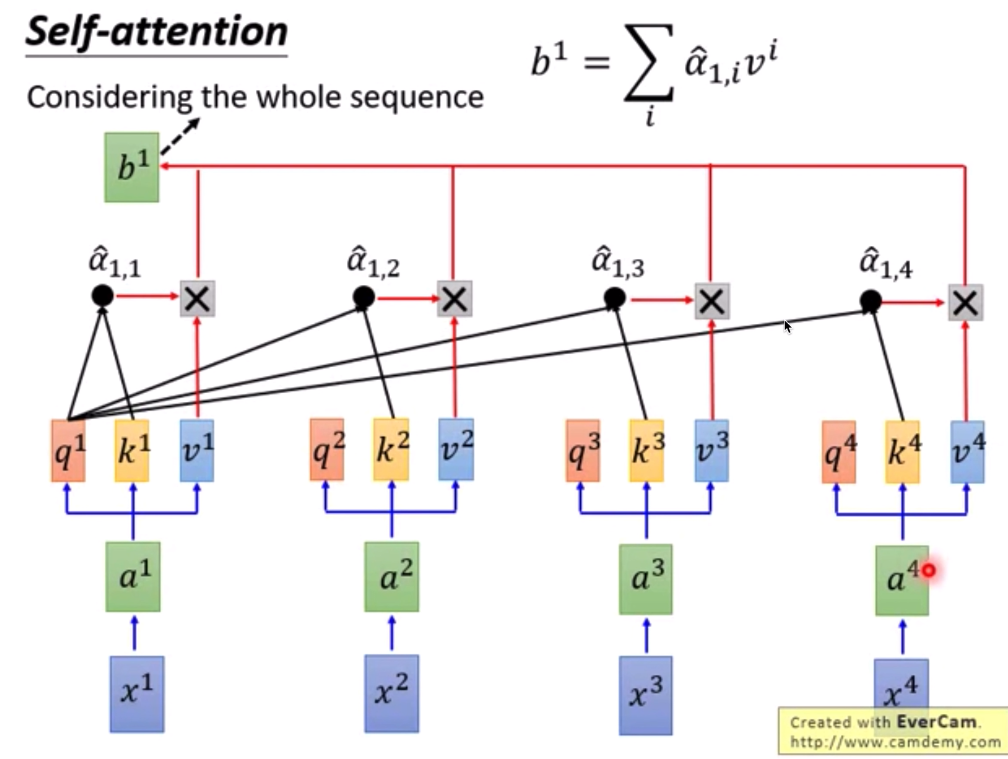
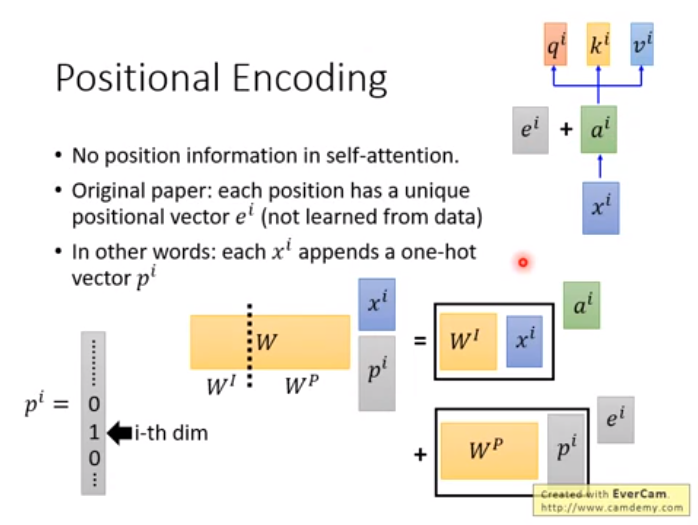
ei是 position vectors (not learned from data)
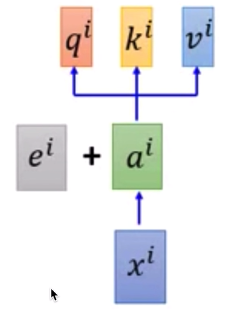
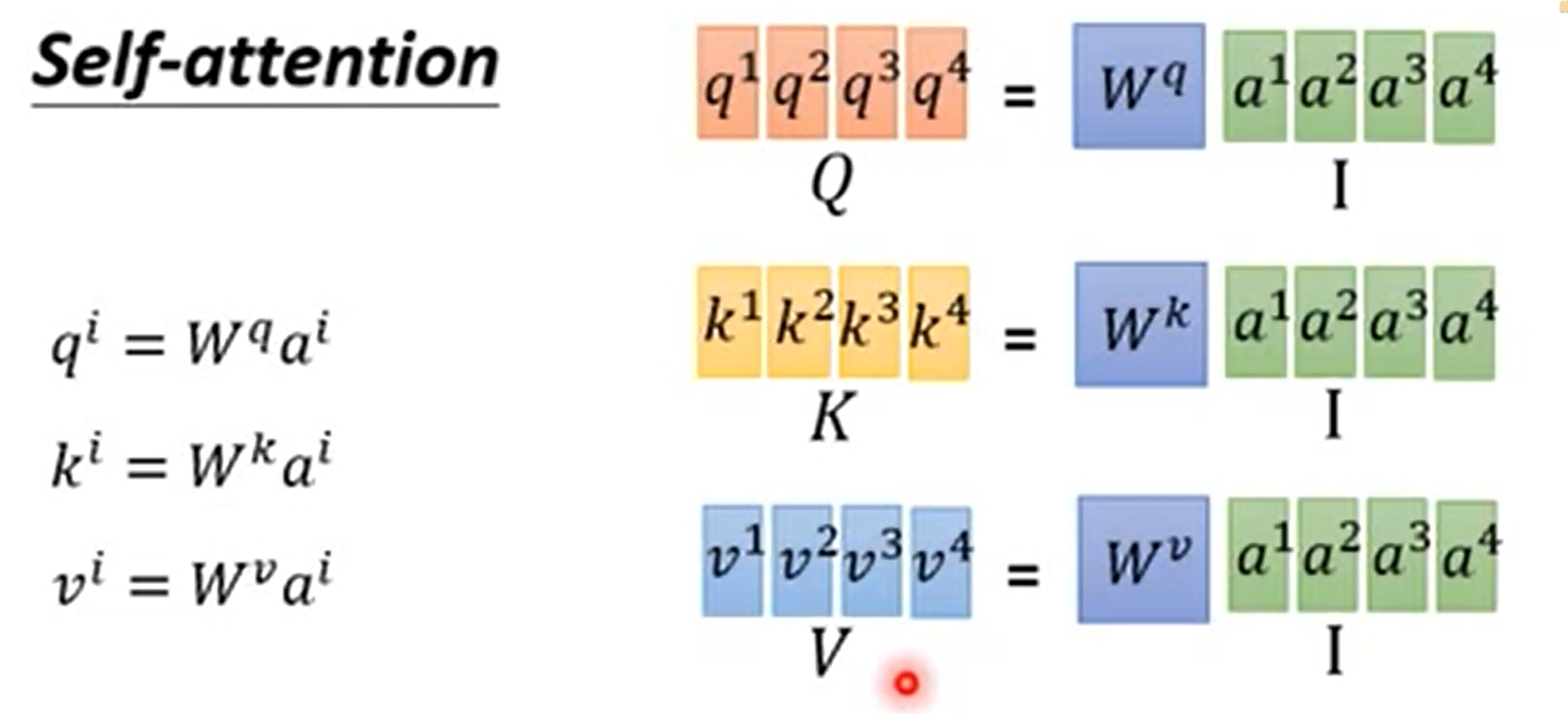
一个 max_seq_len=210的句子,如上图中的x,通过word embedding,得到一个210*256的矩阵,如上图a。
但实际a还是a1 a2 a3等单词组成的
a 通过线性层(但还是210*256——210*256),得到 QKV 三个矩阵,其实基本可以看成a’。然后通过上面的公式 Q和K(T)做点乘,除以dimensionK,然后softmax,然后乘V
q是query,用于match其他人
k:key to be matched
v: information to be extracted
拿每个q去对每个k做attention
scaled dot-product attention α1,i = q1 * ki / 更号d (d is the dim of q and k)
α之间做个softmax 然后与vi做相乘
b1 = Σα1,i * vi
Wq Wk Wv是参数共享的
上面通过的这个线性层,我们的实际经验是,去掉线性层这个步骤效果没区别,而且参数量小很多。
当多头的时候,比如8头,处理方法是210*256的矩阵变成 8个 210*32 的矩阵,然后multi-head attention的计算完成后再拼接起来。
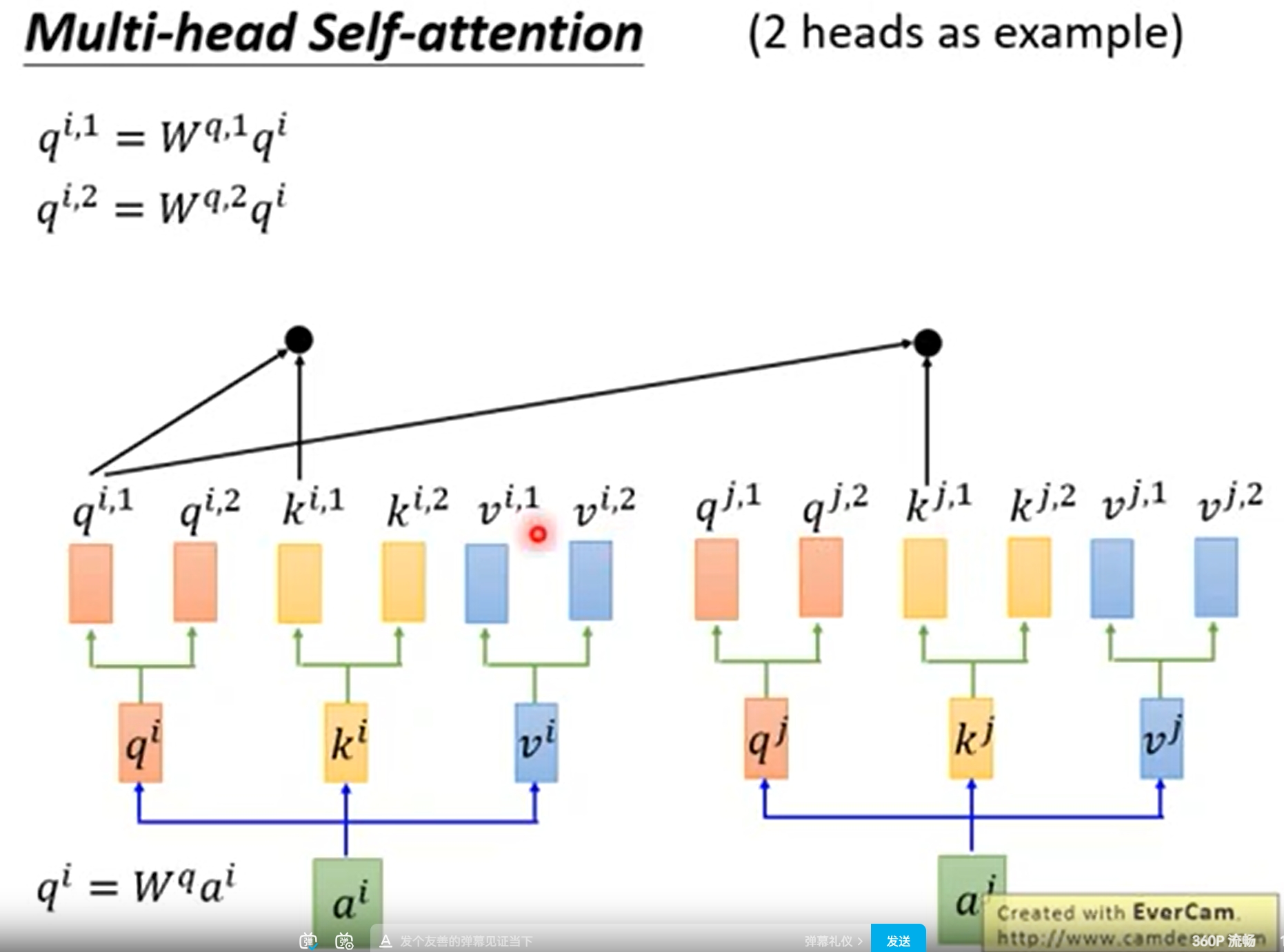
多头的时候,相当于是多了一组 Wq Wk Wv
多头的用途相当于是CNN多个filter的作用,分别提取不同的特征
作者的目的应该是怕头多了以后,在高维空间中参数量大,学习效果不好。
https://www.cnblogs.com/rosyYY/p/10115424.html 这篇文章讲的multihead不错,截图在下方:

记得多头之间参数不共享
Transformer为何使用多头注意力机制?(为什么不使用一个头)¶
这个目前还没有公认的解释,本质上是论文原作者发现这样效果确实好。但是普遍的说法是,使用多个头可以提供多个角度的信息。从多个角度提取特征。
在同一“multi-head attention”层中,输入均为“KQV”,同时进行注意力的计算,彼此之前参数不共享,最终将结果拼接起来,这样可以允许模型在不同的表示子空间里学习到相关的信息
提一下原文的2个头 —-> 6 8 12 个头
Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?¶

链接:https://www.zhihu.com/question/319339652/answer/730848834
Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?¶
为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解¶
减轻输入值的范围问题:
在自注意力机制中,注意力权重通过查询(query)和键(key)的点积来计算。点积的结果是两个向量的长度(即它们的维度)的函数。 随着维度(√dk)的增加,点积的结果会变得越来越大。假设查询和键向量的每个元素的期望值为零,方差为1,那么点积的期望值和方差会随着维度的增加而增大(期望值为0,方差为 (√dk)。
防止softmax输出过于尖锐:
如果不进行缩放,点积结果在高维度时会有较大的数值范围。这会导致softmax函数输出一个非常尖锐的分布,其中某些注意力权重非常接近1,而其他权重非常接近0。 这种极端的权重分布可能会导致梯度消失或者梯度爆炸,从而影响模型的训练过程和性能。 实现数值稳定性: 通过将点积结果除以(√dk) ,可以将点积结果标准化,使得结果值的范围较为适中,不会因为维度的增加而变得过大或过小。 这种缩放使得点积结果更适合输入到softmax函数中,从而得到一个更平滑且数值稳定的注意力分布。
在计算attention score的时候如何对padding做mask操作?¶
padding位置置为负无穷(一般来说-1000就可以)
Transformer的Encoder模块¶
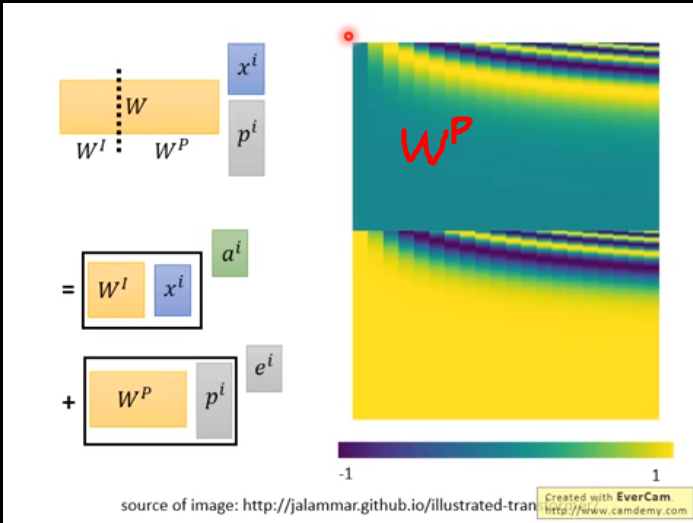
简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?¶
Feed Forward层是一个两层的fully-connection层,中间有一个ReLU激活函数,隐藏层的单元个数为 2048。
是非线性变换,能增强学习能力 nonlinear transformation
Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)¶
Q矩阵来源于下面子模块的输出(对应到图中即为masked多头self-attention模块经过Add&Norm后的输出),而K,V矩阵则来源于整个Encoder端的输出
Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask)¶
Decoder端的多头self-attention需要做mask,因为它在预测时,是“看不到未来的序列的”,所以要将当前预测的单词(token)及其之后的单词(token)全部mask掉。
Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?¶
具体细节???????位置在哪里?待补充
self-attention的优点¶
引入self-attention后会更容易捕获句子中长距离的相互依赖特征。 因为如果是LSTM或者RNN,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
self-attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来, 所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。
除此外,self-attention对计算的并行性也有直接帮助。
关于并行计算¶
Encoder端可以并行计算,一次性将输入序列全部encoding出来,但Decoder端不是一次性把所有单词(token)预测出来的,而是像seq2seq一样一个接着一个预测出来的
batch norm & layer norm¶
可以先看下李宏毅的那个图
batch norm就是一个batch中,对于不同vector之间相同位置的数值做normalization, 使其均值0方差1
layer norm就是对于同一个vector的数值做normalization, 使其均值0方差1
这个说的勉强还行:https://zhuanlan.zhihu.com/p/74516930
batch normalization 受batch size的影响很大,因为他是用batch里的数据来假设是整体样本的情况
https://zhuanlan.zhihu.com/p/54530247
为什么BN不太适用于RNN:
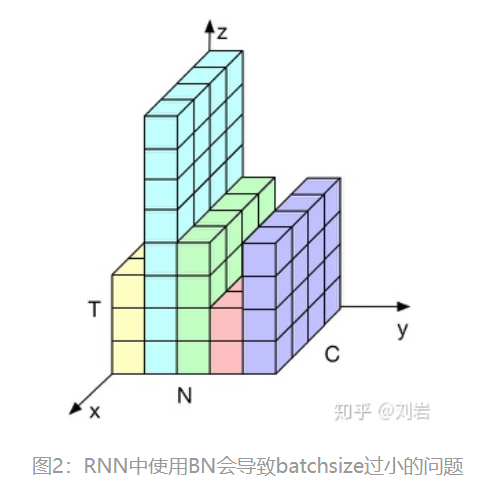
由于文本的长度不一致,例如这几句话,当句长大于4的时候,就只有一个样本了(剩下的全是padding)。做batch norm的话size太小,不能反映样本的整体分布。
transformers 中的 tokenizers是什么¶
在Transformer模型中,tokenizer 是一个用于将文本数据转换为模型可处理的数值形式的工具。具体来说,tokenizer负责将文本字符串分割成单词、子词或字符(称为tokens),并将这些tokens映射到相应的整数索引。这个过程包括以下几个步骤:
分词(Tokenization):
将输入的文本字符串分割成一系列tokens。根据不同的分词方法,可以是单词级别、子词级别(如BPE或WordPiece)或字符级别的tokens。 例如,对于句子 “Transformers are powerful,” 分词器可能将其分割为 [“Transformers”, “are”, “powerful”, “.”] 或 [“Transform”, “ers”, “are”, “power”, “ful”, “.”]。
将tokens映射到索引(Token-to-Index Mapping):
将分割后的tokens转换为整数索引。这通常通过一个预定义的词汇表(vocabulary)来实现。词汇表是token到索引的映射。 例如,假设词汇表中 “Transformers” 的索引是 1234, “are” 的索引是 567, “powerful” 的索引是 890,那么句子 [“Transformers”, “are”, “powerful”, “.”] 将被映射为 [1234, 567, 890, 999](其中 999 可能是词汇表中句点的索引)。
处理特殊tokens:
Tokenizer 还会添加一些特殊的tokens,比如句子的起始(<s>)和结束(</s>)标记、填充(<pad>)标记、未知(<unk>)标记等,这些在模型的训练和推理过程中有特定的用途。 例如,一个句子可能被处理为 [“<s>”, “Transformers”, “are”, “powerful”, “.”, “</s>”] 并映射为相应的索引。
句子对的处理:
对于一些任务,如自然语言推理或问答,tokenizer 需要处理句子对。在这种情况下,tokenizer 会将两个句子连接起来,并插入分隔符token来区分它们。
常见的分词算法包括:
warmup¶
CRF 条件随机场¶
一些资料¶
条件随机场(CRF) 举例讲解 https://www.cnblogs.com/sss-justdDoIt/p/10218886.html
CRF系列(一)——一个简单的例子 https://zhuanlan.zhihu.com/p/69849877
sequence labeling problem 李宏毅 https://www.bilibili.com/video/BV1zJ411575b?from=search&seid=2817357212456451101
通俗易懂理解——BiLSTM-CRF https://zhuanlan.zhihu.com/p/115053401
生成式判别式¶
假定所关心的变量集合为Y, 可观测变量集合为O,其他变量的集合为R,
“生成式” (generative) 模型考虑联合分布 P(Y,O,R)
判别式” (discriminative)型考虑条件分布 P(Y,R|O).
给定一组观测变量值,推断就是要由P(Y,O,R)或P(Y,R|O)得到条件概率分布 P(Y|O).
HMM¶
HMM的两个基本假设:


CRF¶


w是训练中要学习的权重

所以,训练的时候要寻找一个权重w,做到O(w)表达的那个式子最大
拆开写,由两部分组成。已出现过的共现对要权重大,未出现过的搭配权重要小。

反向传播 求导
HMM、CRF、MEMM¶
HMM、CRF、MEMM区别 https://www.cnblogs.com/gczr/p/10248232.html
是序列标注中最常用也是最基本的三个模型。
HMM首先出现,MEMM其次,CRF最后。三个算法主要思想如下:
1)HMM模型是对转移概率和表现概率直接建模,统计共现概率,HMM就是典型的概率有向图,其就是概率有向图的计算概率方式,只不过概率有向图中的前边节点会有多个节点, 而隐马尔可夫前面只有一个节点。
2)MEMM模型是对转移概率和表现概率建立联合概率,统计时统计的是条件概率,但MEMM容易陷入局部最优,是因为MEMM只在局部做归一化。
3)CRF模型中,统计了全局概率,在 做归一化时,考虑了数据在全局的分布,而不是仅仅在局部归一化,这样就解决了MEMM中的标记偏置(label bias)的问题。
将三者放在一块做一个总结:
HMM -> MEMM:
单词的上下文,等等相关。MEMM解决了HMM输出独立性假设的问题。因为HMM只限定在了观测与状态之间的依赖,而MEMM引入自定义特征函数,不仅可以表达观测之间的依赖,还可表示当前观测与 前后多个状态之间的复杂依赖。
MEMM -> CRF:
仅仅在局部归一化,这样就解决了MEMM中的标记偏置的问题。使得序列标注的解码变得最优解。 | • HMM、MEMM属于有向图,所以考虑了x与y的影响,但没讲x当做整体考虑进去(这点问题应该只有HMM)。CRF属于无向图,没有这种依赖性,克服此问题。
<table border=”1” class=”docutils”> <thead> <tr> <th></th> </tr> </thead> <tbody> <tr> <td><strong>举例如下:</strong></td> </tr> </tbody> </table>
对于一个标注任务,“我爱北京天安门“, 标注为” s s b e b c e”。
相比于HMM,状态转移概率矩阵变成了条件状态概率矩阵。 | • 对于CRF的话,其判断这个标注成立的概率为 P= F(s转移到s,’我’表现为s)….F为一个函数,是在全局范围统计归一化的概率而不是像MEMM在局部统计归一化的概率,MEMM所谓的局部归一化, 我的理解就是你加了一个前提条件下的概率,也就是前提条件下概率也要满足各个概率之和为1,是这样的局部归一化。当前,最后出现的CRF在多项任务上达到了统治级的表现,所以如果重头搞应用的话, 大家可以首选CRF。
CRF优点¶
1)与HMM比较,CRF没有HMM那样严格的独立性假设条件,因而可以容纳任意的上下文信息。特征设计灵活(与ME一样)
2)与与MEMM比较,由于CRF计算全局最优输出节点的条件概率,它还克服了最大熵马尔可夫模型标记偏置(Label-bias)的缺点。
3)CRF是在给定需要标记的观察序列的条件下,计算整个标记序列的联合概率分布,而不是在给定当前状态条件下,定义下一个状态的状态分布。凡事都有两面,正由于这些优点,CRF需要训练的参数更多,与MEMM和HMM相比,它存在训练代价大、复杂度高的缺点。
CRF VS 词典统计分词¶
具备较好的学习能力,因此其对歧义词和未登录词的识别都具有良好的效果;其不足之处是训练周期较长,运营时计算量较大,性能不如词典分词
MEMM 标记偏置¶
Bi-LSTM,CRF¶
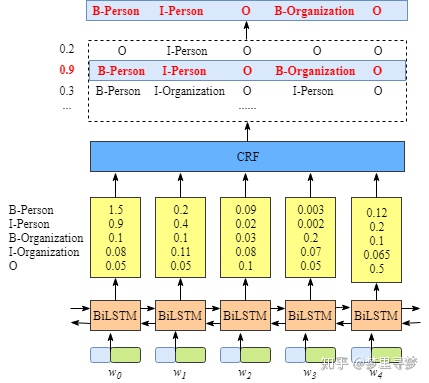
从上图可以看出,BiLSTM层的输出是每个标签的得分,如单词w0,BiLSTM的输出为1.5(B-Person),0.9(I-Person),0.1(B-Organization), 0.08 (I-Organization) and 0.05 (O), 这些得分就是CRF层的输入。
将BiLSTM层预测的得分喂进CRF层,具有最高得分的标签序列将是模型预测的最好结果。
如果没有CRF层将如何:无视语法规则,比如动词后面还会继续接动词等
在CRF层的损失函数中,有两种类型的得分,这两种类型的得分是CRF层的关键概念。
第一个得分为发射得分,该得分可以从BiLSTM层获得。第二个是转移得分,这是BiLSTM-CRF模型的一个参数,在训练模型之前, 可以随机初始化该转移得分矩阵,在训练过程中,这个矩阵中的所有随机得分将得到更新,换而言之, CRF层可以自己学习这些约束条件,而无需人为构建该矩阵。随着不断的训练,这些得分会越来越合理。
维特比算法¶
视频讲解的话可以看这个 https://www.bilibili.com/video/BV1Ff4y127dL?from=search&seid=4545627192690502482 速度可以选1.25或者1.5倍…..
其实就是一个动态规划解决最优路径的事情。看作HMM的解码
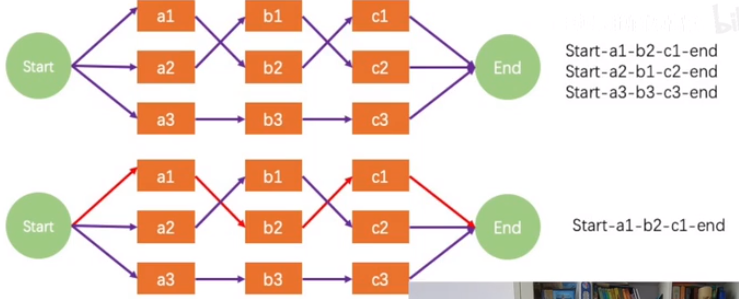
然后在处理b这一列的时候,比如处理b1,只保留从上一层到b1的路径里面最优的路径
文本分类/nlp综述¶
综述¶
文本分类算法综述 https://zhuanlan.zhihu.com/p/76003775?from_voters_page=true
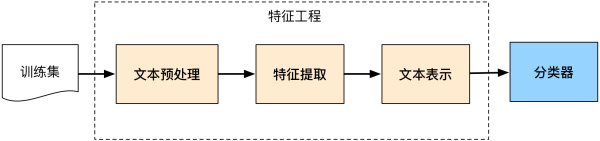
特征工程分为文本预处理、特征提取、文本表示三个部分
文本的向量表示方法 放到前面 “基础知识-文本的向量表示方法” 里面去了
知识图谱&实体链接¶
实体识别 关系识别 实体消歧 还有啥是知识图谱 ?????????待补充
概念解释¶
【NLP笔记】知识图谱相关技术概述 https://zhuanlan.zhihu.com/p/153392625
大家更常指的是NER命名实体识别,指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,以及时间、数量、货币、比例数值等文字。 一般用序列标注问题来处理实体识别。传统的实体识别方法以统计模型如HMM、CRF等为主导,随着深度学习的兴起, DNN+CRF的结构非常的通用,DNN部分可以使用一些主流的特征抽取器如Bi-LSTM, Bert等,这种模型在数据不至于太糟的情况下,轻易就能有90%+的效果。
具有不同标识实体(ID标识符)却代表真实世界中同一对象的那些实体, 并将这些实体归并为一个具有全局唯一标识的实体对象添加到知识图谱中,即同一个实质不同的名字,需要将这些本质相同的东西归并。
是用于解决同个实体名称在不同语句不同意义的问题,同一个词不同的实质, 如apple 在知识图谱里至少有两个歧义,静态词向量无法解决这个问题,不能要求你的知识库里所有的苹果 ,都是吃的苹果。
将自由文本中已识别的实体对象(人名、地名、机构名等),无歧义的正确的指向知识库中目标实体的过程。 本质仍是同一个词不同实质,如已有一个知识库的情况下,预测输入query的某个实体对应知识库id, 如 apple 在一个有上下文的query中是指能吃的apple 还是我们手上用的apple。实体链接强调链接的过程,而消岐强调先描述这个实体是什么。
知识图谱的存储
一种是基于 RDF 的存储;另一种是基于图数据库的存储(使用更多)。 RDF 一个重要的设计原则是数据的易发布以及共享,图数据库则把重点放在了高效的图查询和搜索上。 其次,RDF 以三元组的方式来存储数据而且不包含属性信息,但图数据库一般以属性图为基本的表示形式,所以实体和关系可以包含属性,这就意味着更容易表达现实的业务场景。 根据相关统计,图数据库仍然是增长最快的存储系统。相反,关系型数据库的增长基本保持在一个稳定的水平。
自然语言处理之知识图谱 https://blog.csdn.net/zourzh123/article/details/81011008
知识图谱的一些介绍 知识图谱研究进展 https://www.jiqizhixin.com/articles/2017-03-20
实体链接的应用。一般有KB的地方就离不开EL。以下是EL的几个应用:
实体链接¶
论文笔记 | 实体链接:问题、技术和解决方案 https://zhuanlan.zhihu.com/p/82302101 这个老哥写的不错
里面很详细的介绍
抽一个实体链接的应用放在这里:

Learning to Rank¶
参考资料:
https://jiayi797.github.io/2017/08/30/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%AE%97%E6%B3%95-%E5%88%9D%E8%AF%86Learning-to-Rank/ 机器学习算法-初识Learning to Rank
https://www.youtube.com/watch?v=yKwTAcsV8K8&t=605s Ranking Methods : Data Science Concepts
https://zhuanlan.zhihu.com/p/318300682 pairwise建模入门–排序算法
基本介绍¶
L2R算法主要包括三种类别:PointWise,PairWise,ListWise。
PointWise¶
PointWise缺点:
这种方法没有考虑到排序的一些特征,比如文档之间的排序结果针对的是给定查询下的文档集合,而Pointwise方法仅仅考虑单个文档的绝对相关度; 比如说,假设用户搜cat,d1=0.9,d2=0.6,d3=0.1 但是当只有d2和d3的时候,d2就应该是最相关的
另外,在排序中,排在最前的几个文档对排序效果的影响非常重要,Pointwise没有考虑这方面的影响。
PairWise¶
pairwise存在的问题
尽管文档对方法相对单文档方法做出了改进,但是这种方法也存在两个明显的问题:
一个问题是:文档对方法只考虑了两个文档对的相对先后顺序,却没有考虑文档出现在搜索列表中的位置,排在搜索站果前列的文档更为重要,如果前列文档出现判断错误,代价明显高于排在后面的文档。 针对这个问题的改进思路是引入代价敏感因素,即每个文档对根据其在列表中的顺序具有不同的权重,越是排在前列的权重越大,即在搜索列表前列如 果排错顺序的话其付出的代价更高?
另外一个问题是:不同的査询,其相关文档数量差异很大,所以转换为文档对之后, 有的查询对能有几百个对应的文档对,而有的查询只有十几个对应的文档对,这对机器学习系统的效果评价造成困难 ? 我们设想有两个查询,査询Q1对应500个文文档对,查询Q2 对应10个文档对,假设学习系统对于査询Ql的文档对能够判断正确480个,对于査询 Q2的义格对能够判新正确2个,如果从总的文档对数量来看, 这个学习系统的准确率是 (480+2)/(500+10)=0.95.即95%的准确率,但是从査询的角度,两个査询对应的准确率 分别为:96%和20%,两者平均为58%,与纯粹从文档对判断的准确率相差甚远,
结构
我们首先从pairwise模型结构来看一下:如下图,对于pairwise模型来说,可以看出其训练结构和与预测时有比较大的区别。实际上,训练时,基于pair对来进行输出,而预测时与pointwise模型基本一致,并不需要基于pair来输入。
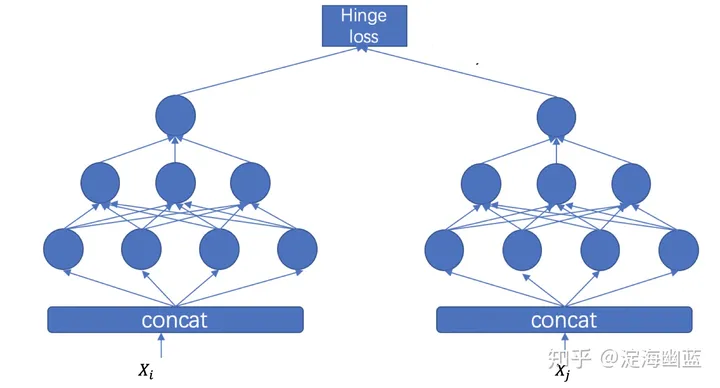
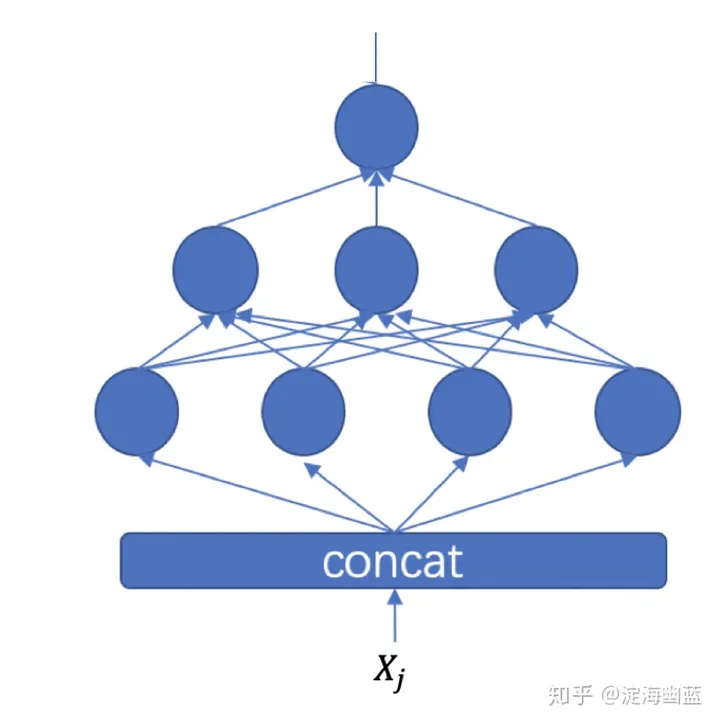
实际上可以看出,预测时就是把训练时的模型砍了一半来使用。需要注意的是, 虽然训练时一般为双塔结构,但实际上这两个塔可以理解为share的,实际上就是一个塔,只不过对Xi 和Xj分别forward了两次。后面看代码就会理解。
损失函数
一般来说,pairwise的损失函数有这么几种可选的(hinge loss, 交叉熵, 交叉熵+lambda)。最常用的是hinge loss, 没错!就是svm用的那个hinge loss。 如果使用交叉熵损失函数,那就是ranknet算法, 如果使用交叉熵+lambda那就是lambdarank算法。实际上lambdarank已经属于listwise的范畴。
这里有个简单构造的demo https://mp.weixin.qq.com/s/2VcBwv-oj6ofOyyGViWxfA
输入还是成对输入的:
1train_data = train[['x','y']]
2train_label = train[['label']]
3......
4dataset1 = xgb.DMatrix(train_data,label=train_label) # used in train
5......
6model = xgb.train(params,dataset1,num_boost_round=100)