实用工具¶

SQL语法¶
学习资料¶
其实不麻烦,几个小时看一遍这个就懂了 https://www.runoob.com/sql/sql-tutorial.html
经典解读¶
以我们最常用的这个模板作为解读
1select
2 count(*) as pv,
3 count(distinct cuid) as uv,
4 event_type,
5 break_max,
6 push_active_level,
7 (case when sid like '%30864_6%' then '30864_6' when sid like '%30864_7%' then '30864_7' end) as exp
8from
9 default.xxxxxx_ads_push_dimension_info
10where
11 event_type in ('ack', 'click')
12 and event_day = '20220522'
13 and source in ('1', '2')
14 and is_all = '2'
15 and tag_type in ('2', '3', '5')
16 and (sid like '%30864_6%' or sid like '%30864_7%')
17group by
18 event_type,
19 exp,
20 break_max,
21 push_active_level
解读一下。其实就四个部分: select, from, where, group by
首先,拿到一个需求,比如需要统计什么,最重要的是select。因为这会是最后展示结果的结构
from就是从哪个表里找
再解释一下group by
| CUID | COIN |
|---|---|
| cuid1 | 1 |
| cuid2 | 2 |
| cuid1 | 4 |
| cuid3 | 3 |
比如这个表。如果select CUID, sum(COIN)的时候,如果不group by cuid。其实算的是所有人的coin的sum。所以有这种加减乘除的,要先group by 再在这些小群体里面执行这种加减乘除的操作
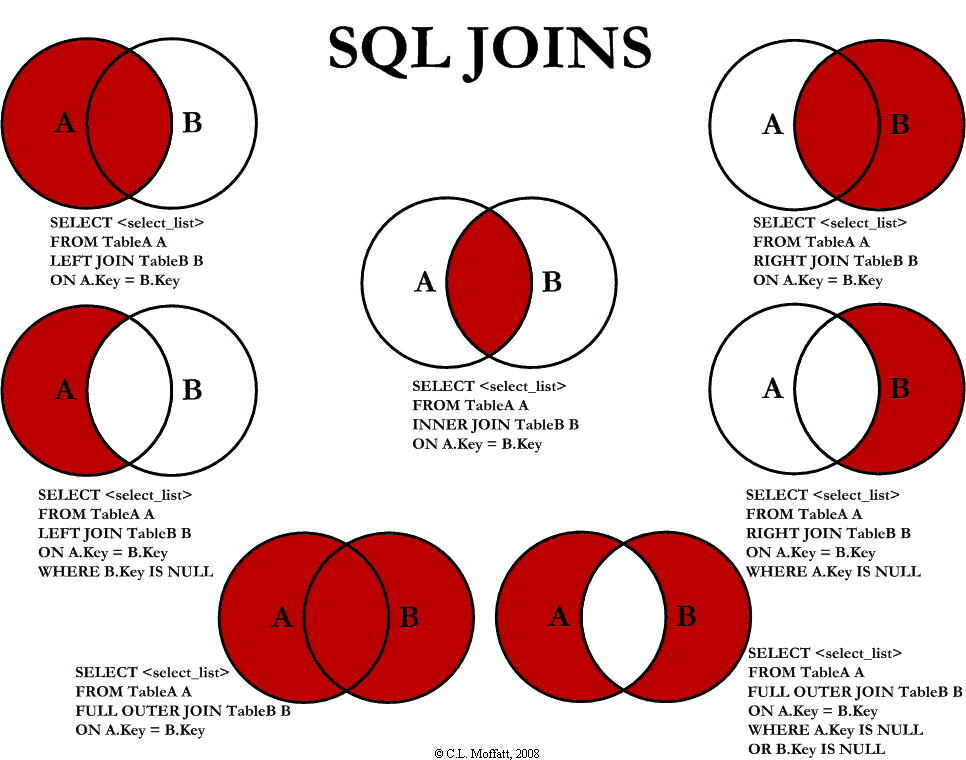
还有一些join(inner join), left join的语法。还有一些as(别名)的语法看看菜鸟教程就好。
hadoop常用命令¶
大部分hadoop命令跟Linux命令相同,只是在使用时需要加上hadoop fs前缀。
各命令请看官方文档: Hadoop Shell命令 http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html
DAG格式¶
1$HADOOP_ROOT_HMP/bin/hadoop streaming -conf $HADOOP_CONF \
2 -D abaci.dag.is.dag.job=true \
3 -D abaci.split.remote=true \
4 -D abaci.dag.vertex.num=4 \
5 -D abaci.dag.next.vertex.list.0=1 \
6 -D abaci.dag.next.vertex.list.1=2 \
7 -D abaci.dag.next.vertex.list.3=2 \
8 -D stream.map.streamprocessor.0="${HADOOP_PYTHON_CMD} feed_nid_cuid_mapper_feed_click.py --exp1_ids=$exp1_ids" \
9 -D stream.reduce.streamprocessor.1="${HADOOP_PYTHON_CMD} feed_nid_cuid_reducer_join_uid.py" \
10 -D stream.reduce.streamprocessor.2="${HADOOP_PYTHON_CMD} feed_nid_cuid_reducer_print_final.py --tuwen_dict=feed_clk_tuwen_clear --video_dict=feed_clk_video_clear" \
11 -D stream.map.streamprocessor.3="${HADOOP_PYTHON_CMD} feed_nid_cuid_mapper_nid_json.py" \
12 -D mapred.reduce.slowstart.completed.maps=0.9 \
13 -D mapred.reduce.tasks=100 \
14 -D mapred.job.map.capacity=1800 \
15 -D mapred.job.reduce.capacity=100 \
16 -D mapred.map.memory.limit=1500 \
17 -D mapred.reduce.memory.limit=1500 \
18 -D mapred.job.priority=HIGH \
19 -D abaci.job.base.environment=default \
20 -D stream.num.map.output.key.fields=1 \
21 -D mapred.output.compress=true \
22 -D mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec \
23 -D map.output.key.field.separator='#' \
24 -D reduce.output.key.field.separator='#' \
25 -D num.key.fields.for.partition=1 \
26 -D mapred.job.name="${HADOOP_JOB_NAME}" \
27 -partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner \
28 -file ../src/feed_nid_cuid_mapper_feed_click.py \
29 -file ../src/feed_nid_cuid_reducer_join_uid.py \
30 -file ../src/feed_nid_cuid_mapper_nid_json.py \
31 -file ../src/feed_nid_cuid_reducer_print_final.py \
32 -file ../src/libMMHash.so \
33 -file ../src/user_hash.py \
34 -file ../dict/experiment_dict \
35 -file ../dict/feed_clk_tuwen_clear \
36 -file ../dict/feed_clk_video_clear \
37 -cacheArchive "${HADOOP_PYTHON_ARCHIVE_WANGHUAN}#python" \
38 -outputformat org.apache.hadoop.mapred.${output_format} \
39 -mapper "cat" \
40 -reducer "cat" \
41 -input ${INPUT_FEED_PATH}/* \
42 -input ${INPUT_NID_JSON_PATH}/part-* \
43 -input ${HADOOP_INPUT_CUID_INDEX}/* \
44 -output $HADOOP_OUTPUT
多输出路径¶
C++ 入门¶
Model Deployment¶
Docker¶
Kubernetes¶
Model Deployment¶
describe a project focused on the production phase¶
like what’s your role in the process? And what tools did you use to production as a model?
from GPT
Project Name: Predictive Maintenance for Manufacturing Equipment
Objective: The goal is to deploy a machine learning model that predicts equipment failures in a manufacturing plant to minimize downtime and maintenance costs.
As a Machine Learning Engineer, my role in the production phase includes the following responsibilities:
Production Phase Workflow
Outcome
By following this approach, the machine learning model for predictive maintenance is successfully deployed into production, enabling real-time predictions of equipment failures. The use of containerization and orchestration ensures scalability and reliability. The deployment pipeline is automated to allow for seamless updates and retraining, ensuring the model remains accurate over time. Monitoring tools provide visibility into the model’s performance, enabling proactive issue resolution.
This structured production phase ensures that the predictive maintenance system operates efficiently, reducing equipment downtime and maintenance costs, and ultimately improving operational efficiency in the manufacturing plant.
after the model is in production or went online, how do you monitor the model.¶
Monitoring a machine learning model in production is crucial to ensure its performance, reliability, and integrity. Here are the key steps and practices to effectively monitor a model once it is deployed:
将机器学习模型部署到生产环境后,监控其性能、可靠性和完整性至关重要。以下是有效监控模型的关键步骤和实践:
CI/CD¶
what is the end to end machine learning life cycle.¶
system Design¶
https://www.youtube.com/watch?v=KYExYE_9nIY
whimsical
sql vs nosql
先问些问题,比如user Number,text image video? xxx这些功能是否需要
打开 whimsical
做一些文字记录,关键数据
calculation: 然后开始计算内存
都有哪些组成部分 title timestamp comments
each character int 2 bytes
需要一些 mircoservice
sql vs nosql
cache